
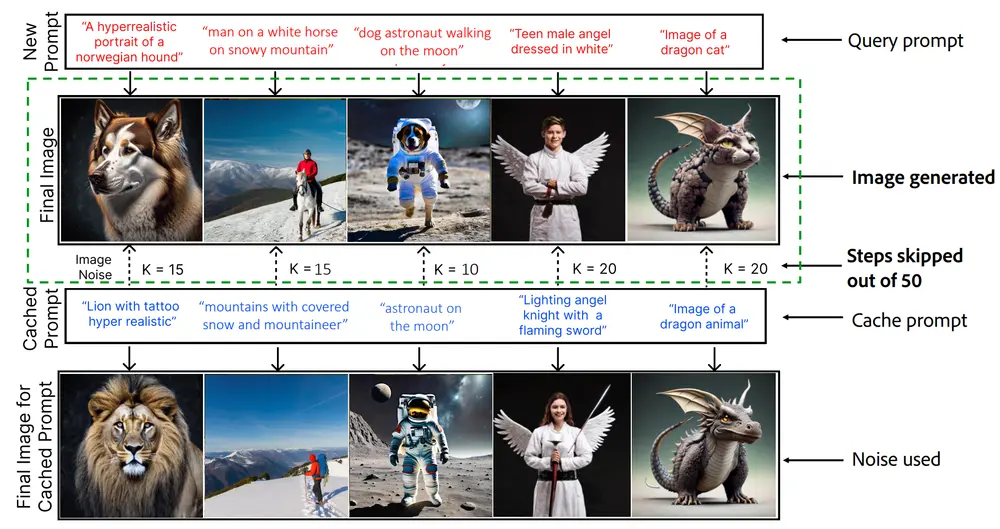
新型文本到图像生成系统NIRVANA:利用近似缓存技术,高效地服务基于扩散模型的文本到图像生成任务
Adobe和伊利诺伊大学厄巴纳-香槟分校的研究人员介绍了一种名为NIRVANA的新型文本到...




MotionShop:用于视频扩散模型中的零样本(Zero-Shot)运动转移方法,通过混合分数引导(MSG)实现
近年来,扩散模型在图像和视频生成领域取得了显著进展,但在运动迁移任务中,如何...



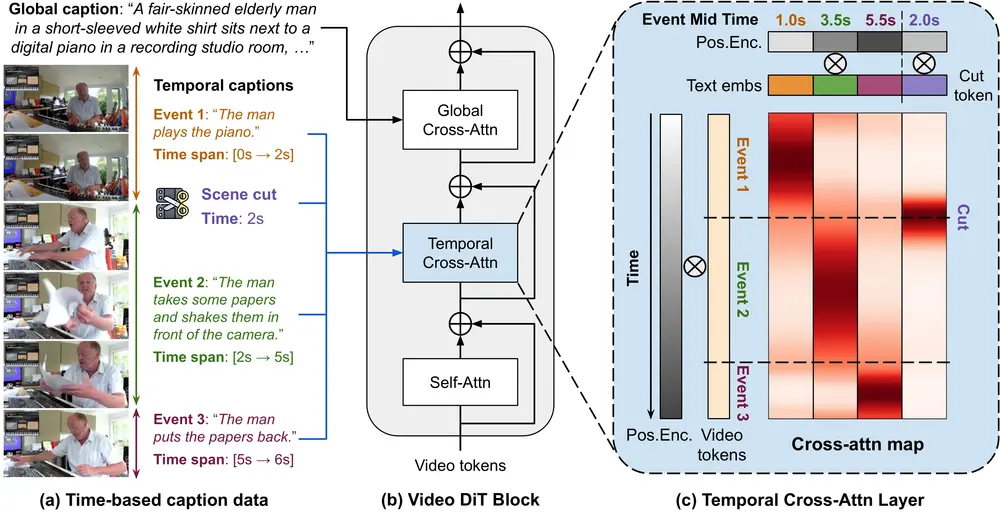
多事件视频生成框架MinT:根据一系列文本提示和特定的时间戳生成具有精确时间控制的视频序列
Snap Research、多伦多大学和向量研究所的研究人员推出多事件视频生成框架MinT(Mi...

