
在开发智能应用程序时,开发者常常面临一个核心挑战:如何让 AI 模型基于最新的、专有的或特定领域的数据生成准确的响应?传统的大语言模型(LLM)虽然功能强大,但它们的能力受限于训练数据,无法自动适应动态变化的内容。为了解决这一问题,检索增强生成(RAG)应运而生。然而,构建和维护 RAG 流水线往往需要大量的技术投入和持续优化。
现在,Cloudflare 推出了AutoRAG,这是一个完全托管的 RAG 解决方案,旨在帮助开发者快速、高效地将上下文感知的 AI 功能集成到应用程序中。无论是支持机器人、内部知识助手,还是语义搜索系统,AutoRAG 都能让开发者专注于业务逻辑,而不是复杂的基础设施管理。

什么是 AutoRAG?
AutoRAG 是 Cloudflare 提供的一个端到端的 RAG 平台,目前已进入公开测试阶段。它通过自动化整个 RAG 流水线的关键步骤,大幅简化了开发流程。具体来说,AutoRAG 包括以下功能:
数据摄取与处理
AutoRAG 自动从您的数据源中提取内容,并将其分割成适合嵌入的小块。这些数据可以是文档、数据库记录、网页内容等。向量化与存储
分割后的数据会被转换为向量表示,并存储在 Cloudflare 的 Vectorize 数据库 中。这种高效的向量存储方式支持快速的语义检索。语义检索
当用户提出查询时,AutoRAG 会根据查询内容从向量数据库中检索出最相关的上下文信息。响应生成
检索到的相关信息会与用户的输入结合,传递给大型语言模型(如 Workers AI),从而生成高质量、上下文相关的响应。自动更新与维护
AutoRAG 会持续监控您的数据源,并在后台自动重新索引和更新嵌入,确保系统的相关性和性能始终保持最佳状态。
通过这种方式,AutoRAG 将原本复杂且易出错的 RAG 流水线变成了一个简单、可靠的工具,只需几次点击即可完成配置。
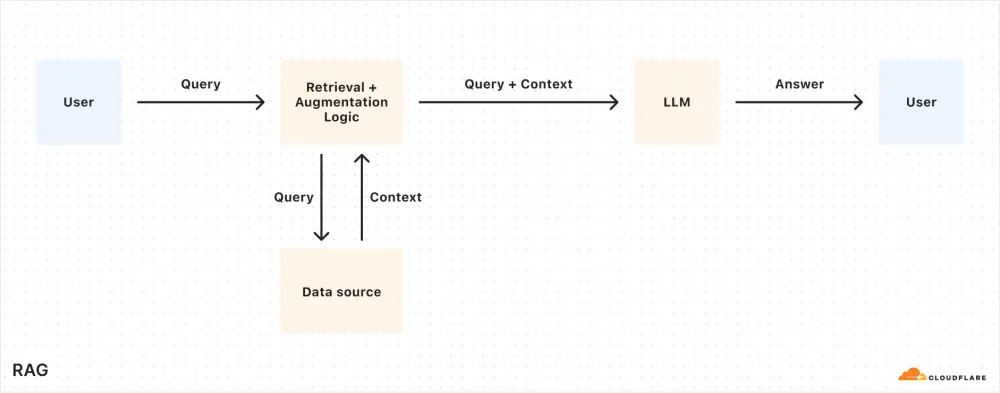
为什么选择 RAG?
尽管像 Meta 的 Llama 3.3 这样的大型语言模型非常强大,但它们有一个明显的局限性:它们只能基于训练时的数据生成响应。当面对新的、专有的或特定领域的问题时,这些模型的表现往往不尽如人意。
解决这一问题的传统方法包括:
系统提示:在用户输入中手动添加相关信息。这种方法不仅增加了输入长度,还受限于模型的上下文窗口大小。 微调模型:针对特定任务对模型进行微调。但这种方法成本高昂,且需要持续重新训练以保持数据的时效性。
相比之下,RAG 提供了一种更灵活、更经济的解决方案。它通过在查询时动态检索相关信息,并将其与用户输入结合,使模型能够生成基于最新数据的精准响应。这使得 RAG 成为以下场景的理想选择:
AI 驱动的客户支持机器人 内部知识库助手 文档的语义搜索 其他需要动态更新真相来源的应用
AutoRAG 的优势
AutoRAG 的推出,标志着 RAG 技术进入了一个全新的阶段。以下是 AutoRAG 的几大亮点:
完全托管,开箱即用
开发者无需拼凑多个工具和服务,也无需担心底层基础设施的维护。AutoRAG 提供了一个无缝集成的解决方案,让您专注于构建智能应用。自动化的数据管理
AutoRAG 会持续监控您的数据源,并在后台自动重新索引和更新嵌入,确保系统始终与最新数据同步。高性能语义检索
基于 Cloudflare 的 Vectorize 数据库,AutoRAG 能够快速、准确地检索出与用户查询最相关的信息。与 Cloudflare 生态深度集成
AutoRAG 与 Cloudflare 的开发者平台无缝连接,支持与其他服务(如 Workers AI)协同工作,进一步提升开发效率。
如何开始使用 AutoRAG?
如果您对 AutoRAG 感兴趣,现在就可以通过 Cloudflare 仪表板开始体验。只需几次点击,您就可以配置一个完整的 RAG 流水线,并将其集成到您的应用程序中。无论您是希望构建一个智能客服系统,还是需要为团队提供一个内部知识助手,AutoRAG 都能为您提供强大的支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











