
在近日的一次技术展示中,AMD 展示了其最新的 锐龙AI MAX+ 395 “Strix Halo” APU 在 DeepSeek R1 AI 基准测试中的卓越表现。这款集成了 Zen 5 架构处理器、XDNA 2 神经处理单元(NPU)和强大统一内存设计的 APU,不仅在性能上超越了竞争对手,还重新定义了 AI 工作负载的硬件标准。

令人瞩目的是,Strix Halo APU 的性能表现比英伟达最新的桌面显卡 RTX 5080 高出 3 倍以上,并在某些场景下甚至碾压更高端的 RTX 5090。这一结果不仅彰显了 AMD 在 AI 计算领域的技术实力,也为未来 AI 应用的普及提供了全新的可能性。

Strix Halo APU 的核心亮点
1. 强大的硬件架构
Zen 5 架构处理器:集成 16 核、32 线程的高性能 CPU,为通用计算提供坚实基础。 XDNA 2 NPU:具备高达 50 TOPS 的 AI 推理能力,专为深度学习和神经网络优化。 集成显卡与统一内存:支持高达 128GB 统一内存,其中最多可分配 96GB 作为显存,显著提升了处理大型 AI 模型的能力。
相比 RTX 5080 的 16GB显存 和 RTX 5090 的 32GB 显存,Strix Halo APU 的大容量统一内存使其在处理大语言模型(LLM)和其他 AI 工作负载时具有无可比拟的优势。
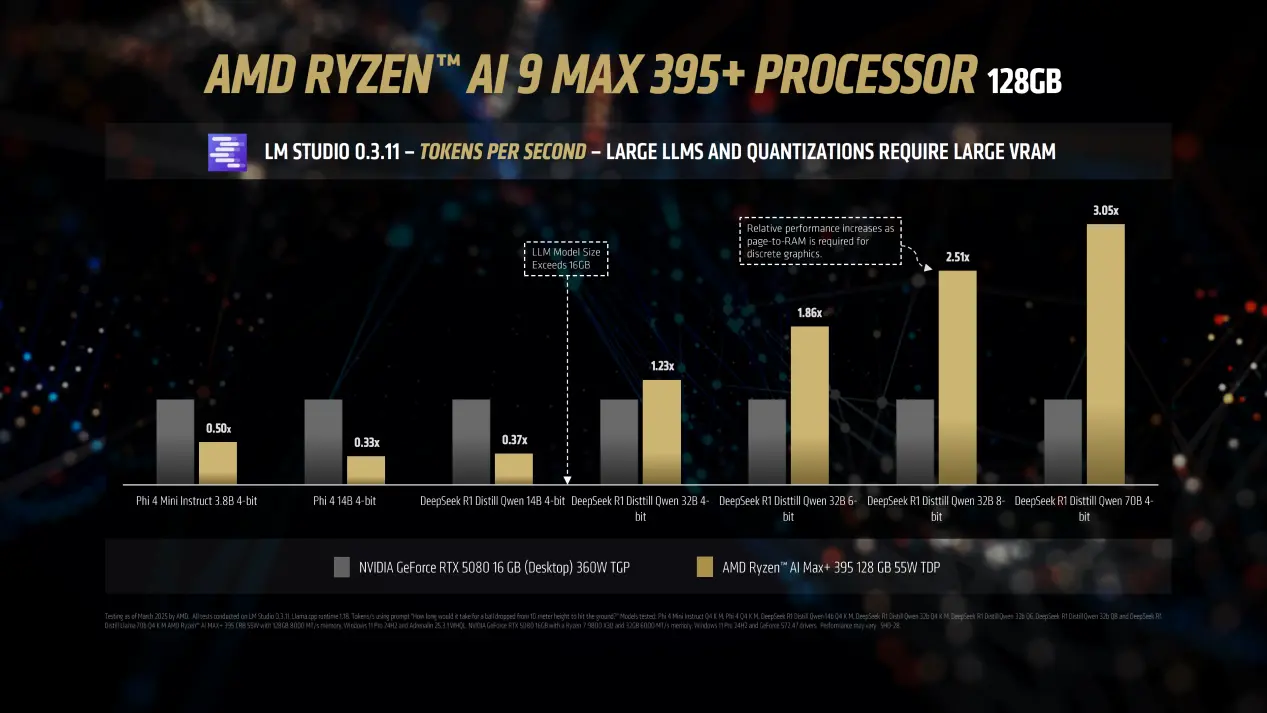
2. 性能对比:全面领先竞争对手
与 英伟达RTX 5080 对比
在运行大型语言模型(如 Llama 3.2)时,当模型大小超过 RTX 5080 的 16GB 显存容量限制时,Strix Halo APU性能提升 3.05 倍,即使面对超大模型,Strix Halo APU 依然能够流畅运行,而 RTX 5080 则因显存不足而陷入瓶颈。
与 英伟达RTX 5090 对比
尽管 RTX 5090 拥有更大的 32GB 显存,但 Strix Halo APU 凭借其 128GB 统一内存 和灵活的内存分配机制,在处理如谷歌 Gemma 3 27B Vision 等超大规模模型时仍占据绝对优势。
与英特尔 Arc 140V 对比
token 吞吐量提升 2.2 倍:在生成式 AI 应用中,Strix Halo APU 的高吞吐量使其更适合实时推理任务。 小模型性能飞跃:在运行 Llama 3.2 3B Instruct 等小型模型时,首个 token 生成时间最高可快 4 倍。 中大型模型加速:对于 7-8B 参数模型,速度提升可达 9.1 倍;而对于 14B 参数模型,性能比英特尔酷睿 Ultra 258V 快 12.2 倍。
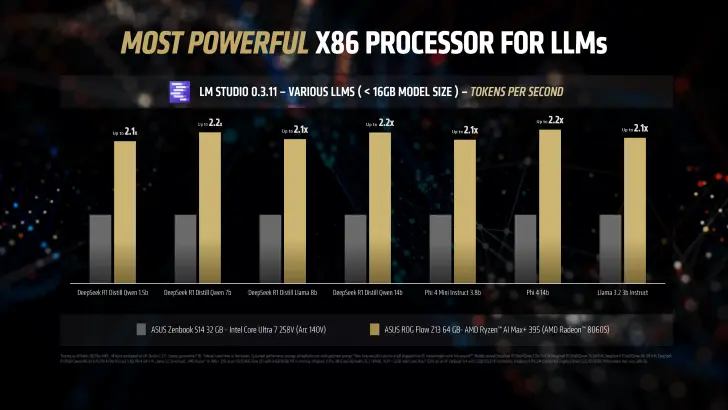
统一内存:AI 性能的关键突破
传统 GPU 的显存容量往往是处理大型 AI 模型的主要瓶颈,而 Strix Halo APU 的 128GB 统一内存 设计彻底解决了这一问题。通过灵活的内存分配机制,用户可以根据具体需求动态调整显存比例,从而在不同工作负载间实现最佳性能平衡。
例如:
处理小型模型时,可以减少显存分配以释放更多系统内存。 运行超大规模模型(如谷歌 Gemma 3 27B Vision)时,最多可将 96GB 内存转换为显存,确保模型顺利加载和运行。
这种灵活性不仅让 Strix Halo APU 能够处理其他硬件无法胜任的任务,还大幅降低了 AI 开发者的硬件成本。
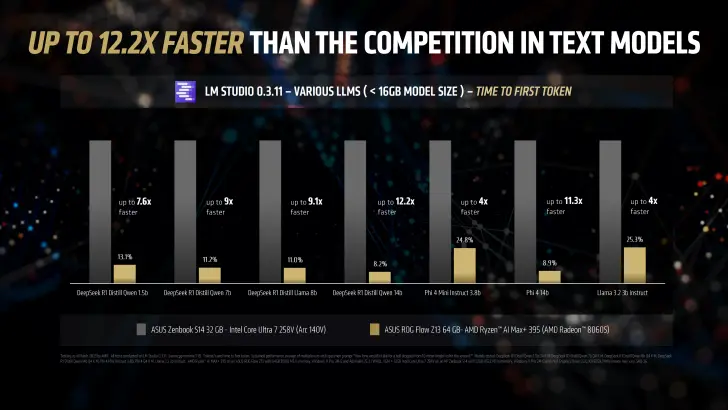
实际应用测试:多场景下的卓越表现
AMD 使用多种消费者级 AI 工作负载对 Strix Halo APU 进行了基准测试,包括基于 llama.cpp 的应用程序 LM Studio。测试结果显示,Strix Halo APU 在以下场景中表现出色:
大语言模型(LLM)推理:当模型大小超过 16GB 时,RTX 5080 因显存不足而崩溃,而 Strix Halo APU 则轻松应对,性能提升达 3.05 倍。 实时生成任务:在生成文本、图像或视频时,Strix Halo APU 的高吞吐量和低延迟特性使其成为创作者的理想选择。 多任务并行处理:凭借统一内存设计,Strix Halo APU 能同时运行多个 AI 模型,而不会出现资源冲突或性能下降。

AMD 的战略意义与市场潜力
随着 AI 技术的快速发展,越来越多的消费者和企业开始依赖 AI 工具进行内容生成、数据分析和科学研究。然而,高昂的硬件成本和有限的显存容量一直是阻碍 AI 普及的主要障碍。
AMD 锐龙AI MAX+ 395 “Strix Halo” APU 的推出,不仅填补了这一空白,还为市场带来了全新的解决方案:
性价比优势:相比昂贵的独立显卡,APU 的一体化设计显著降低了硬件成本。 广泛的适用性:从个人开发者到企业用户,Strix Halo APU 都能满足不同规模的 AI 需求。 生态系统的完善:AMD 提供了丰富的开发工具和优化库,帮助开发者快速部署和优化 AI 应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











