根据哥伦比亚新闻评论(CJR)下属的数字新闻Tow中心的一项最新研究,AI驱动的搜索工具在处理新闻来源相关查询时面临显著的准确性挑战。研究发现,这些模型的回答错误率超过60%。
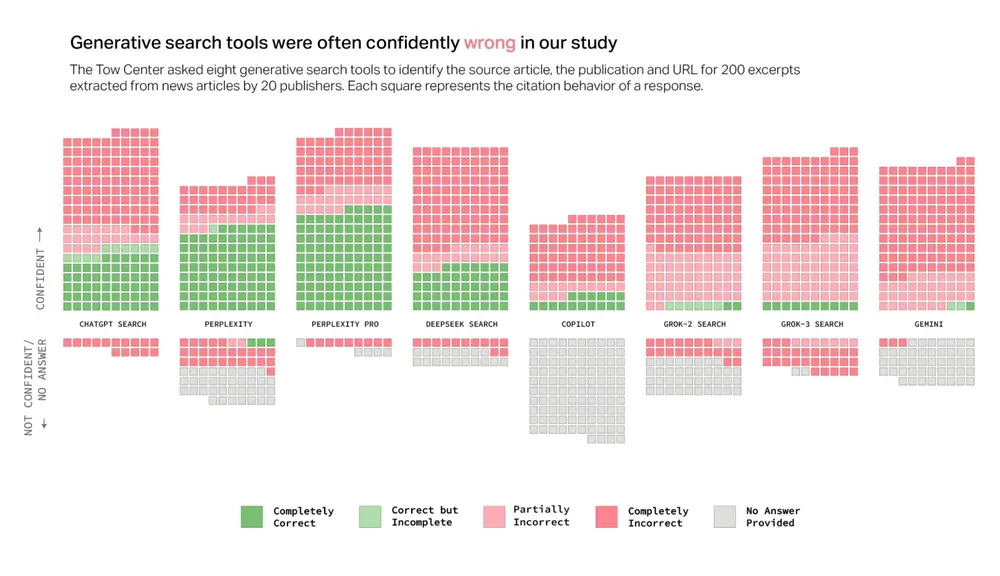
研究概览
- 参与测试的工具:八款具有实时搜索功能的AI驱动搜索工具。
- 错误率情况:整体错误率超60%,其中Perplexity为37%,ChatGPT Search为67%,Grok 3最高达94%。
- 测试方法:研究人员使用1,600次查询,基于实际新闻文章摘录来评估模型识别标题、原始出版商、发布日期和URL的能力。
主要发现
研究揭示了一个普遍现象:当面对缺乏可靠信息的情况时,AI模型倾向于提供看似合理但实际上错误或推测性的答案。更令人担忧的是,即使是付费高级版本,如Perplexity Pro和Grok 3高级服务,也未能改善这一状况,反而因不愿拒绝不确定的响应而导致更高的错误率。
引用与控制问题
此外,研究还指出了一些AI工具对出版商控制内容传播方式的影响:
- 忽视Robot Exclusion Protocol:例如,尽管《国家地理》明确禁止Perplexity访问其付费内容,但后者仍能正确识别相关内容。
- 指向聚合而非原始内容:即使提供了来源引用,用户往往被引导至Yahoo News等平台,而非原始出版商网站。
- URL伪造问题:Gemini和Grok 3中超过一半的引用链接最终失效或导向错误页面。
这些问题给出版商带来了巨大压力,他们必须在保护内容和增加曝光之间做出艰难选择。
行业反应
《时代》杂志首席运营官Mark Howard认为,虽然当前产品存在缺陷,但未来仍有改进空间。他同时强调,用户应保持谨慎,不应完全依赖免费AI工具的准确性。OpenAI和微软均回应表示将致力于支持出版商,并遵守相关协议,以提高内容透明度和控制权。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











