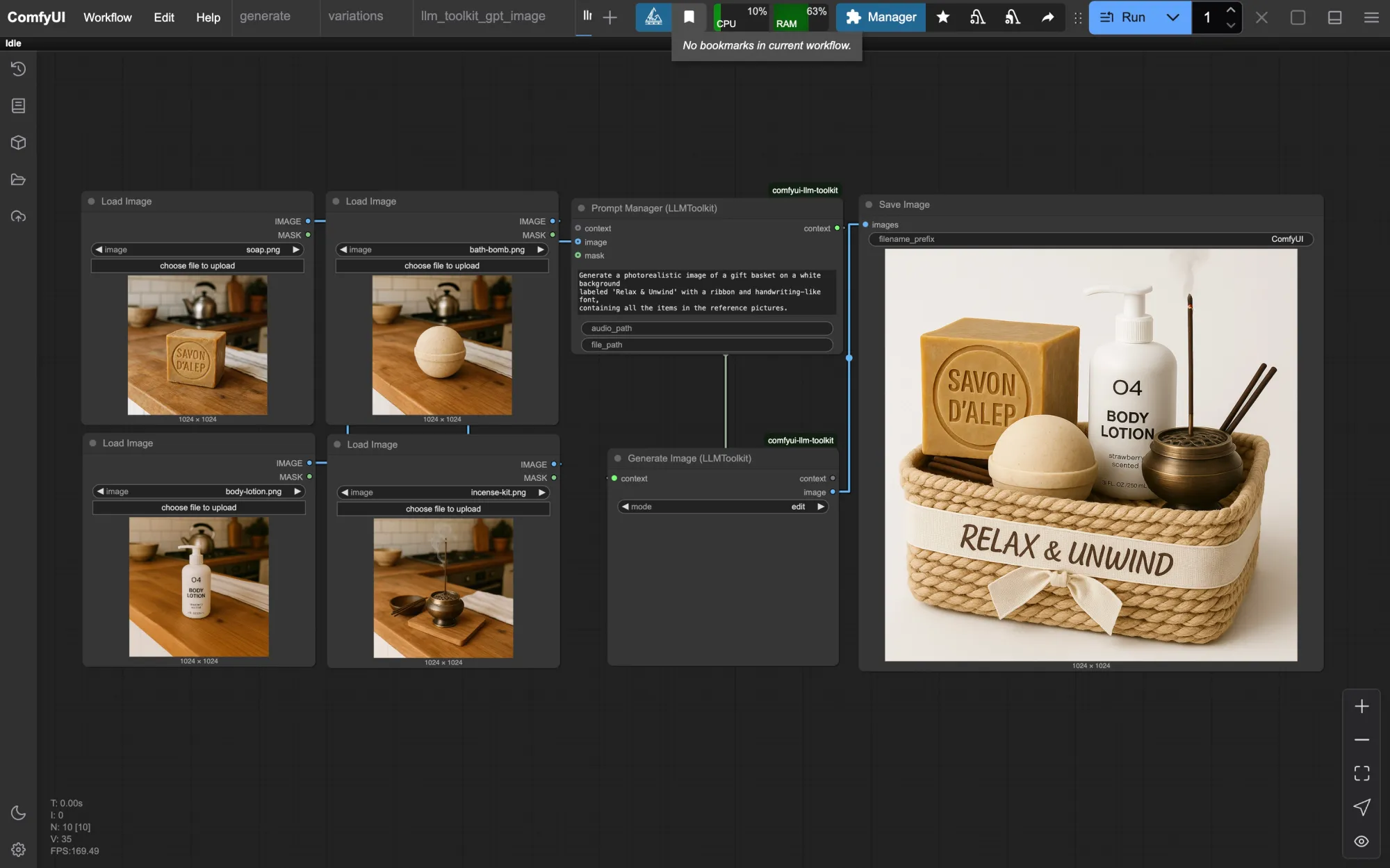
在视频创作中,寻找或制作与画面完美同步的音效和背景音乐往往是最耗时的环节之一。现在,ComfyUI-AudioX 自定义节点的到来,让这一过程在本地即可高效完成。
- GitHub:https://github.com/jinxishe/ComfyUI-AudioX
该节点基于香港科技大学(HKUST)最新推出的多模态音频生成框架 AudioX,能够根据视频内容自动生成高度同步的音效(SFX)或背景音乐(BGM),并支持通过文本提示词进行精细化引导。
新型多模态音频生成框架AudioX:通过统一的模型架构实现从各种输入模态(如文本、视频、图像、音频等)生成高质量的音频和音乐
核心功能:四大生成模式
AudioX 节点提供了灵活的任务模式,满足不同场景需求:
| 任务模式 | 描述 | 是否需要文本提示 | 应用场景 |
|---|---|---|---|
| V2A (Video-to-Audio) | 纯视频驱动,生成匹配画面的音效 | ❌ 否 | 快速为无声片段添加环境音、动作音效 |
| V2M (Video-to-Music) | 纯视频驱动,生成匹配氛围的背景乐 | ❌ 否 | 自动配乐,保持音乐节奏与画面剪辑同步 |
| TV2A (Text+Video-to-Audio) | 视频 + 文本引导,生成特定音效 | ✅ 是 | “生成沉重的脚步声”、“清脆的玻璃破碎声” |
| TV2M (Text+Video-to-Music) | 视频 + 文本引导,生成特定风格音乐 | ✅ 是 | “生成紧张的悬疑背景乐”、“轻快的爵士钢琴” |
节点详解与工作流
ComfyUI-AudioX 包含三个核心节点,可无缝接入现有工作流:
- AudioX 模型加载器:负责加载本地模型,输出
AUDIOX_MODEL供后续节点使用。 - AudioX 视频转音频:直接接收 ComfyUI 标准
VIDEO输入,生成同步音频。 - AudioX 图像转音频 (VHS):专为 VideoHelperSuite (VHS) 优化,接收帧序列 (
IMAGE) 和 FPS 信息,适合处理长视频或复杂加载逻辑。
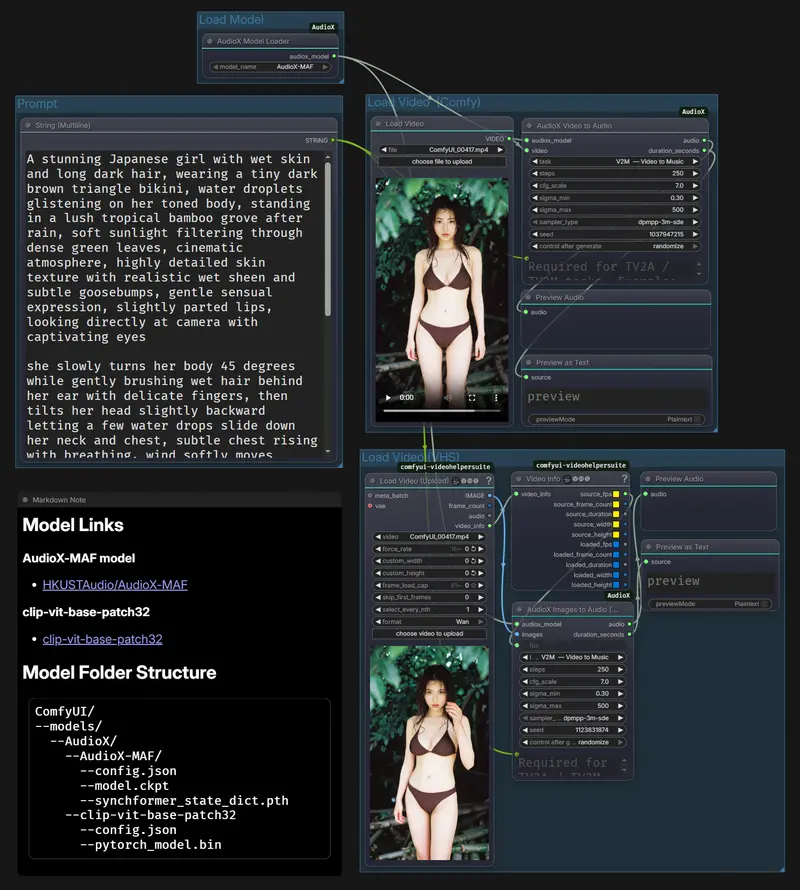
典型工作流示例:
graph LR
A[加载视频] --> B{选择路径}
B -->|标准路径 | C[AudioX 视频转音频]
B -->|VHS 路径 | D[AudioX 图像转音频 (VHS)]
D -->|需传入 FPS| E[来自 VHS 视频信息]
C --> F[预览/保存音频]
D --> F
模型选择与推荐
目前支持多种模型变体,建议优先使用经过充分测试的版本:
- 🏆 AudioX-MAF (强烈推荐):质量最佳,采用 Synchformer 视觉编码器,音画同步率最高。
- AudioX-MAF-MMDiT:MMDiT 架构变体,目前处于测试阶段。
- AudioX:基础版本,无 Synchformer 增强,同步效果略逊。
安装与配置指南
方法一:ComfyUI Manager 一键安装(推荐)
- 打开 ComfyUI Manager。
- 搜索
ComfyUI-AudioX并点击安装。 - 重启 ComfyUI,依赖项将自动处理。
方法二:手动安装
- 克隆仓库:
cd ComfyUI/custom_nodes git clone https://github.com/jinxishe/ComfyUI-AudioX.git - 安装依赖:
cd ComfyUI-AudioX pip install -r requirements.txt # 注意:torch 系列库由 ComfyUI 统一管理,无需重复安装 - 下载模型:
需在ComfyUI/models/AudioX/目录下构建以下结构:# 1. 下载主模型 (推荐 MAF) huggingface-cli download HKUSTAudio/AudioX-MAF \ --local-dir "ComfyUI/models/AudioX/AudioX-MAF" # 2. 下载共享 CLIP 视觉编码器 (所有模型共用) huggingface-cli download openai/clip-vit-base-patch32 \ --local-dir "ComfyUI/models/AudioX/clip-vit-base-patch32"
关键参数说明
| 参数 | 默认值 | 说明 |
|---|---|---|
steps | 250 | 扩散采样步数。越高音质越好,但生成越慢。 |
cfg_scale | 7.0 | 引导比例。控制文本提示对生成的影响力度。 |
sigma_min/max | 0.3 / 500 | 噪声调度范围,影响生成多样性。 |
sampler_type | dpmpp-3m-sde | 采样算法,推荐保持默认以获得最佳平衡。 |
seed | -1 | 随机种子。设为固定值可复现相同结果。 |
注意事项与硬件要求
- 显存需求:建议至少 16 GB VRAM(已在 RTX 4060 Ti 16GB 上验证)。低于此配置可能需要开启
--lowvram模式或降低分辨率。 - 视频时长:模型基于 10 秒片段 训练。
- 短于 10 秒:自动填充最后一帧。
- 长于 10 秒:建议切片处理,或接受输出音频被修剪至前 10 秒。
- 外部依赖:
AudioX 图像转音频 (VHS)节点依赖系统安装的 FFmpeg,用于临时组装帧序列。 - 日志警告:启动时若出现 CLIP
UNEXPECTED键警告,属正常现象(因仅加载视觉头),可安全忽略。
故障排除
1. NumPy 版本冲突
若报错 dctorch requires numpy<2.0.0 或类似冲突:
pip install "numpy>=2.0.0"
说明:大多数音频库已兼容 NumPy 2.x,升级通常能解决问题。
2. Protobuf 版本冲突
若 descript-audiotools 报错:
pip install "protobuf<3.20,>=3.9.2"
3. 依赖警告
如果节点能正常运行,pip 安装过程中的部分版本警告通常可以忽略,不必过度纠结。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











