谷歌正在内部测试两项新功能:Visual Layout 和 Creative Canvas,提升 Gemini 在生成内容后的交互能力。
这两项功能均聚焦于改变AI输出的呈现形式,从静态文本或图片,转向可直接在聊天界面内操作的动态内容。
Creative Canvas:内联交互式内容生成
Creative Canvas 的核心是允许用户在 Gemini 的对话窗口中,直接生成并使用嵌入式交互组件,而非通过侧边栏或跳转页面访问。
这些组件包括:
- 互动新闻仪表板:可点击的摘要卡片、动态数据图表、可筛选的时间轴
- 迷你网页游戏:例如基于文本提示生成的简单点击类、解谜类或模拟类小游戏
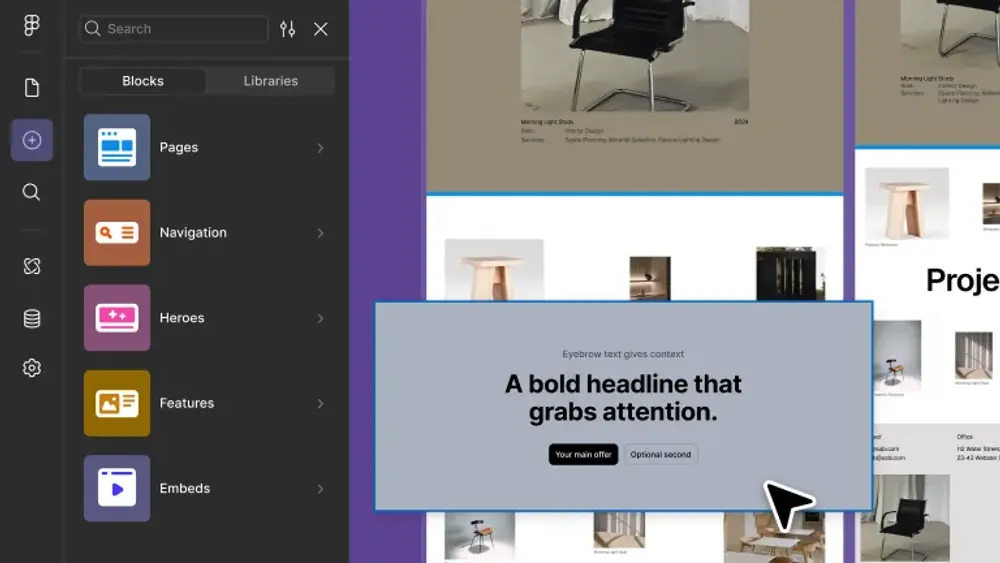
- 可编辑画布:包含图文混合布局的模板,用户可调整元素位置、增删内容
与此前演示的 Visual Layout(主要用于生成结构化、演示型界面)相比,Creative Canvas 更强调可操作性与即时性。
- Visual Layout:输出的是“设计稿”——静态布局,供用户参考
- Creative Canvas:输出的是“可运行组件”——用户可在对话中直接点击、拖拽、交互
例如,用户输入:“用我上周的健身数据做一个交互式周报”,系统可能直接在聊天窗口中生成一个包含折线图、可切换天数、点击查看细节的微型仪表板,无需离开对话界面。
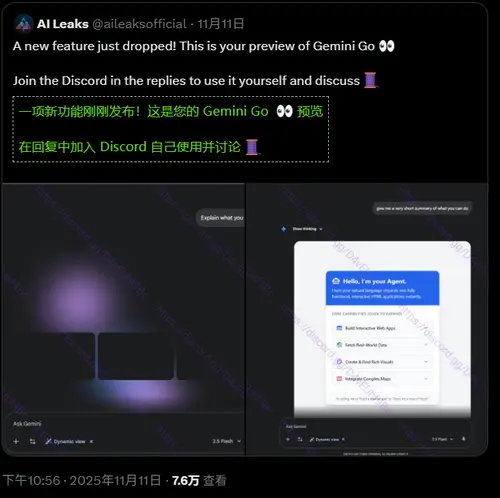
技术背景:与 Agent Mode 并行开发
这些功能并非孤立更新,而是谷歌在 Gemini 平台中推动的多模式交互系统的一部分。
目前,谷歌正在同步开发以下三项内部功能:
| 功能 | 目的 | 输出形式 |
|---|---|---|
| Agent Mode | 让AI自主执行多步骤任务 | 自动调用工具、分步反馈 |
| Visual Layout | 生成结构化视觉布局 | 静态图文模板 |
| Creative Canvas | 生成可交互数字工件 | 内联可操作组件(游戏、仪表板等) |
三者目标一致:让用户更直接地控制AI生成内容的使用方式,但实现路径不同。
Creative Canvas 的底层技术依赖于谷歌持续优化的模型栈,特别是对多模态输出编码和前端渲染能力的整合。它不依赖外部网站或插件,所有交互内容均在浏览器内动态生成。
当前状态:仅限内部测试
目前,Creative Canvas 和 Visual Layout 均处于内部测试阶段,无公开发布时间表。
谷歌未说明这些功能是否会与下一代 Gemini 模型(如 Gemini 2.0)同步发布,也未透露是否将向所有用户开放。
据内部信息,这些功能优先面向企业用户、教育机构和创意工作者测试,评估其在内容创作、数据展示和教学场景中的实用性。
潜在应用场景
| 场景 | 应用示例 |
|---|---|
| 教育 | 学生提问“解释光合作用”,AI生成一个可点击的植物结构图,点击叶绿体显示化学反应 |
| 数据分析 | 产品经理要求“展示上季度用户留存趋势”,AI直接输出可筛选日期、导出CSV的交互图表 |
| 内容创作 | 博主输入“帮我做一个关于AI伦理的互动小测验”,AI生成一个5题选择题游戏,嵌入文章末尾 |
| 产品原型 | 设计师说“做一个简单的待办事项管理器”,AI生成可增删任务、标记完成的轻量级网页应用 |
这些不是“演示demo”,而是可直接在对话中使用、无需跳转、无需下载的数字工件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...