阿里通义实验室近日推出新一代端到端语音识别大模型 Fun-ASR。该模型基于大语言模型(LLM)能力构建,在家装、保险、畜牧等多个垂直行业的语音识别准确率提升15%以上,部分场景最高提升达18%,显著增强语音转写在真实业务中的可用性。
目前,Fun-ASR 已应用于会议字幕、同声传译、智能纪要生成、语音助手等场景,未来将正式上线阿里云百炼平台,向更多企业和开发者开放。
什么是 Fun-ASR?
Fun-ASR 是一个由大语言模型驱动的端到端语音识别系统,其核心目标是解决传统 ASR(自动语音识别)在复杂场景下的三大难题:
- 专业术语识别不准
- 上下文理解能力弱
- 多语种、多方言、噪声环境适应性差
它并非简单的“语音转文字”工具,而是一个具备语义理解、上下文感知和领域适配能力的智能语音引擎。
技术亮点:从“听清”到“听懂”
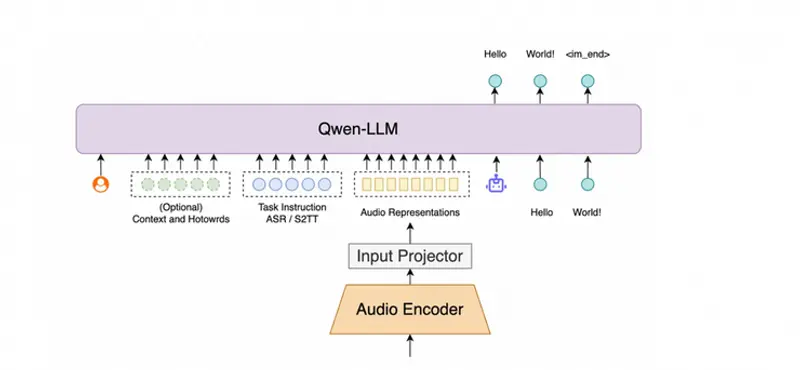
1. 大模型驱动,语言能力更强
Fun-ASR 基于通义自研语音算法,并结合 Qwen3 大模型进行监督微调(SFT),在文本生成与语义理解层面获得显著增强。
相比传统ASR仅依赖声学和语言模型拼接,Fun-ASR 实现了声学信号与语言理解的深度融合,能更好地处理口语化表达、省略句、长句断句等问题。
2. 集成 RAG:让模型“边查边听”
Fun-ASR 首次在语音识别系统中引入 RAG(检索增强生成)机制,支持:
- 最多导入 1000+ 自定义热词
- 自动检索相关领域文档、前序对话记录
- 动态增强关键词识别能力
例如,在保险理赔场景中,系统可自动加载“免赔额”“定损”“第三方责任险”等术语库,大幅提升专业词汇识别准确率。
3. 强化学习优化,减少“幻觉”输出
为防止模型在低信噪比或模糊发音下“脑补”错误内容(即“幻觉”),通义团队在训练中引入 强化学习(RL)策略,通过奖励机制引导模型:
- 优先输出高置信度内容
- 对不确定部分保持保守
- 减少误识别和虚构文本
实测表明,该策略有效提升了系统整体的可靠性与稳定性。
4. 多方言、多环境适应性强
Fun-ASR 在方言和复杂声学环境下的表现尤为突出:
- ✅ 方言支持:在四川话、粤语、闽南语等方言上,识别准确率领先同类产品
- ✅ 远场拾音:适用于会议室、展厅等远距离收音场景
- ✅ 近场降噪:在工位、超市、户外等嘈杂环境中仍能保持高准确率
无论是电话录音、现场访谈,还是移动设备采集的语音,Fun-ASR 均能稳定输出高质量转写结果。
行业实测:垂直领域准确率显著提升
Fun-ASR 在训练中使用了上亿小时的音频数据,覆盖互联网、科技、家装、畜牧、汽车、金融等十余个行业,积累了丰富的专业术语和语境知识。
实测数据显示:
| 行业 | 准确率提升 |
|---|---|
| 保险 | ↑ 18% |
| 家装 | ↑ 16% |
| 畜牧 | ↑ 15% |
| 汽车 | ↑ 17% |
在保险行业,面对大量口语化描述和专业术语混合的对话,Fun-ASR 能准确识别“重疾险”“现金价值”“等待期”等关键词,显著提升保单录入与客服质检效率。
在家装场景中,对“乳胶漆”“轻钢龙骨”“地暖回填”等施工术语的识别能力大幅提升,助力设计师沟通记录自动化。
应用场景:不止于“转写”
Fun-ASR 已在多个实际场景中落地:
- 🎤 会议字幕与同传:实时生成中英双语字幕,支持多人对话分离
- 📝 智能纪要:自动提取会议要点、待办事项、决策结论
- 🧠 语音助手:提升指令理解准确率,支持复杂上下文交互
- 🔍 内容检索:结合RAG能力,实现语音内容的关键词定位与知识关联
未来,Fun-ASR 将上线 阿里云百炼平台,企业可通过API快速集成,构建专属的语音处理 pipeline。
通义音频矩阵持续完善
截至目前,通义实验室已在音频领域布局完整技术栈:
| 模型 | 能力 |
|---|---|
| Fun-ASR | 高精度语音识别 |
| CosyVoice | 自然流畅语音合成 |
| MinMo | 端到端多模态音频理解 |
| ThinkSound | 音频生成与音效创作 |
覆盖从“听”到“说”、从“识别”到“生成”的全链路需求,形成完整的音频大模型体系。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...