
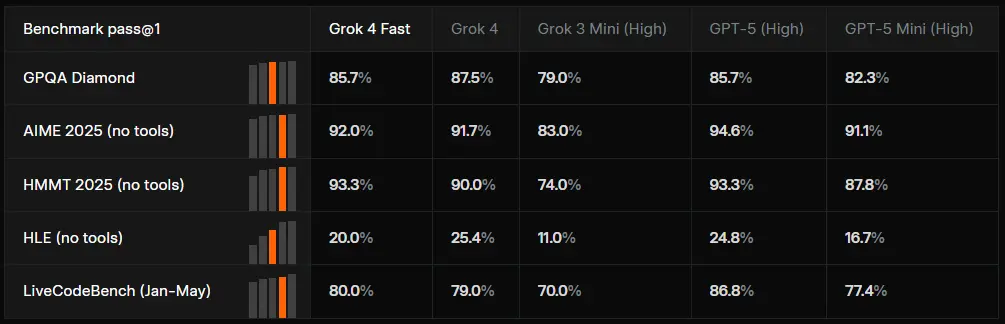
xAI 正式推出 Grok 4 Fast ——一款在成本效率与推理性能之间取得突破平衡的新一代模型。它不是简单地堆叠参数,而是聚焦于“智能密度”的提升:用更少的计算资源完成高质量的复杂任务。

Grok 4 Fast 的目标明确:让高阶 AI 推理能力不再局限于少数资源充足的机构,而是变得更轻量、更快、更具可及性。
核心优势:高效、统一、实时
✅ 显著降低推理成本
基于 Grok 4 的训练经验,Grok 4 Fast 在多个关键维度实现跃升:
- 相比 Grok 4,平均减少 40% 的思考令牌使用量
- 每个输出 token 成本大幅下降
- 实现相同性能水平时,综合成本降低 98%
这一结果已通过第三方评测机构 Artificial Analysis 验证,在其发布的“价格-智能比率”榜单中,Grok 4 Fast 达到当前公开可用模型中的最先进(SOTA)水平。
这意味着:你可以用极低的成本运行原本昂贵的长链推理任务。
原生工具调用 + 实时搜索能力
Grok 4 Fast 在训练阶段就引入了端到端的强化学习机制,使其具备自主判断是否调用外部工具的能力,例如:
- 执行代码
- 浏览网页
- 检索 X 平台内容
这使得它在处理需要实时信息的任务时表现尤为出色。例如,在回答涉及最新事件的问题时,模型可主动跳转链接、解析图文视频内容,并快速整合成连贯回应——整个过程无需人工干预。
它不只是“能联网”,而是“知道什么时候该联网”。
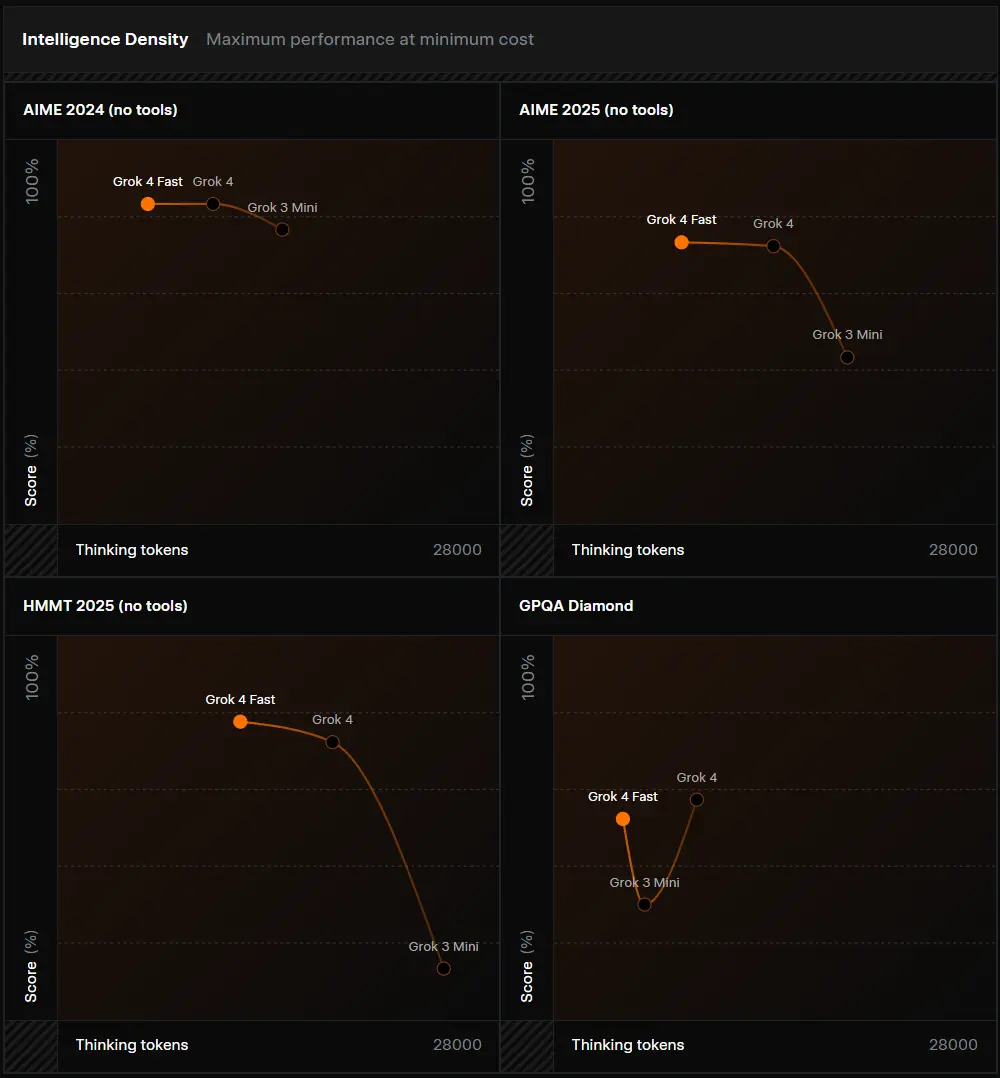
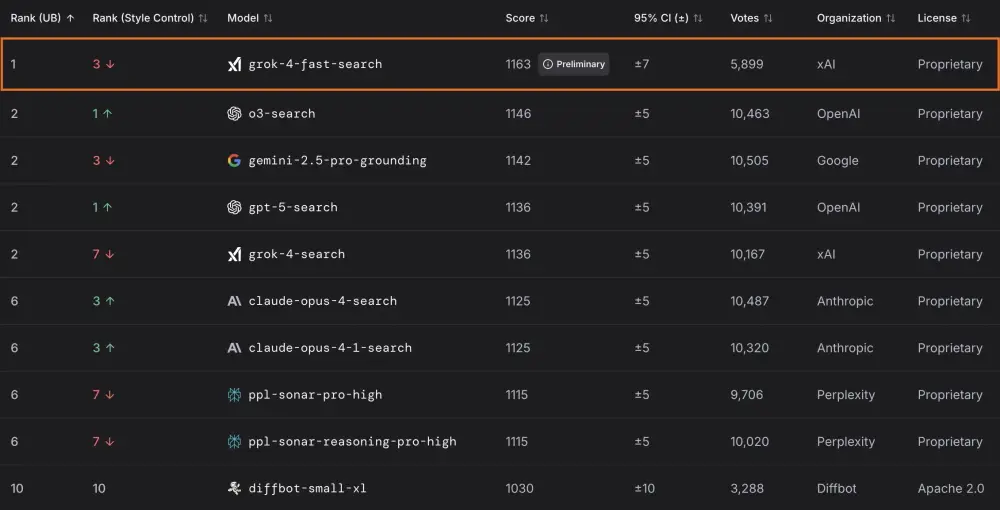
在 LMArena 上的表现:小模型,大能量
Grok 4 Fast 已在内部测试平台 LMArena 中完成多轮对抗评估,涵盖“搜索”与“文本生成”两大场景。
| 模型代号 | 场景 | Elo 得分 | 排名 |
|---|---|---|---|
| menlo (grok-4-fast-search) | 搜索竞技场 | 1163 | 第1位 |
| tahoe (grok-4-fast) | 文本竞技场 | - | 第8位 |
- 在搜索任务中,menlo 领先 o3-search 17 分,展现出卓越的信息检索与综合能力;
- 在通用对话与推理中,tahoe 表现接近 grok-4-0709,远超同规模其他模型(同类模型排名均低于第18位);
这些数据表明:Grok 4 Fast 虽非最大模型,但在智能密度和任务效率上处于领先地位。
统一架构:一个模型,两种模式
以往,推理模式(Reasoning)与快速响应模式(Non-reasoning)通常依赖两个独立模型。Grok 4 Fast 首次实现了单模型双模式统一架构:
- 使用相同的权重参数
- 通过系统提示(system prompt)动态切换行为
- 支持从即时应答到深度链式推理的平滑过渡
这种设计带来了双重优势:
- 降低延迟:无需模型切换或上下文迁移
- 节省成本:避免重复加载或冗余计算
在实际应用中(如 grok.com 或移动端 App),这意味着:
- 简单问题 → 即时回复
- 复杂查询 → 自动进入深度推理流程
用户无感知切换,体验更流畅。
当前可用性:全面开放,限时免费
🌐 对终端用户
Grok 4 Fast 已上线 grok.com 及 iOS / Android 应用:
- 所有用户(包括免费账户)均可无限制访问
- “自动模式”下会根据问题复杂度智能启用该模型
- 搜索与信息类查询响应速度显著提升
这是 xAI 向“民主化高级 AI”迈出的重要一步。
⚙️ 对开发者
Grok 4 Fast 现已通过以下平台提供服务:
- OpenRouter(限时免费)
- Vercel AI Gateway(限时免费)
- xAI API(正式发布)
并通过 xAI API 提供两个专用接口:
grok-4-fast-reasoning:适用于复杂推理任务grok-4-fast-non-reasoning:适用于低延迟交互
两者均支持高达 200 万 token 的上下文窗口(2M context),是目前最长上下文之一。
定价如下(单位:美元 / 百万 token)
| 类型 | <128K tokens | ≥128K tokens |
|---|---|---|
| 输入(Input) | $0.20 | $0.40 |
| 输出(Output) | $0.50 | $1.00 |
| 缓存输入(Cached Input) | $0.05 | — |
缓存机制可进一步降低重复内容的处理成本,适合知识库问答等场景。
展望未来
xAI 表示将持续基于用户反馈迭代 Grok 4 Fast,后续计划包括:
- 增强多模态理解能力(图像、音频等)
- 提升代理(Agent)级别的自主决策能力
- 深化与 X 平台的实时数据集成
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











