
来自斯坦福大学、谷歌研究、图宾根大学和Stability AI的研究人员推出3D Congealing,这是一种新颖的3D感知图像对齐技术,用于处理捕捉语义相似对象的2D图像集合。
简单来说,就像我们人类能够从不同角度和光照条件下识别出同一个物体的不同照片,并在心中构建出一个统一的3D模型一样,这项技术旨在通过一系列未标记的互联网图片,自动地找出这些图片中共同的语义部分,并将它们对齐到一个共享的3D空间中。

主要功能和特点:
- 无需模板或相机参数: 传统的3D重建技术通常需要已知的物体形状模板或者相机参数,但3D Congealing不需要这些信息,它可以处理任意形状和任意光照条件下的图像。
- 强大的知识融合: 该技术结合了预训练图像生成模型的先验知识和输入图像的语义信息,以引导这个欠约束任务,并减少训练数据偏差。
- 多任务适用性: 它可以用于多种任务,如姿态估计(确定物体在3D空间中的方向和位置)、图像编辑和对象对齐等。
工作原理:
3D Congealing的核心是一个规范的3D表示,它包含了几何和语义信息。这个框架通过优化过程,同时寻找每个输入图像的规范表示和姿态,以及每个图像的坐标映射,这些映射将2D像素坐标变换到3D规范框架中,以考虑形状匹配。 优化过程融合了预训练图像生成模型的先验知识(如Stable-Diffusion和DINO模型)和输入图像的语义信息。这个过程通过迭代优化,逐渐调整3D表示和图像姿态,直到找到最佳匹配。
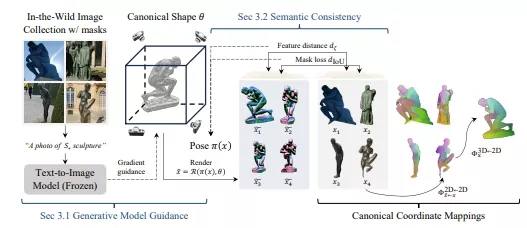
具体应用场景:
- 图像编辑: 通过3D Congealing,我们可以将来自不同角度和光照条件的图片中的相同对象对齐到一个共享的3D空间,然后进行图像编辑,如更换背景、添加特效等。
- 在线图像集合处理: 对于从互联网上收集的图片,如旅游地标照片,这项技术可以帮助我们理解和分析这些图片中的共同特征,并将它们整合到一个统一的视觉表示中。
- 个性化3D模型生成: 通过输入一系列特定对象的图片,3D Congealing可以生成一个个性化的3D模型,这对于产品设计、游戏开发等领域非常有用。
3D Congealing是一种先进的图像处理技术,它通过3D几何和语义信息的结合,为处理和理解复杂图像数据提供了一种新的解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











