
随着大语言模型(LLM)在各类应用场景中的广泛部署,如何提升推理效率、降低延迟、节省资源成为关键挑战。近日,开源项目 LMCache 正式亮相,它是一个专为 LLM 服务优化的高性能缓存引擎,显著降低首 token 延迟(TTFT),并提升整体吞吐量。
简单来说,LMCache 就像是给大模型加了一个“Redis”,通过键值缓存复用技术,让重复文本的处理不再重复计算,从而大幅提升响应速度和资源利用率。

核心功能亮点
- ✅ 多级缓存支持:可在 GPU、CPU 和本地磁盘之间灵活存储 KV 缓存;
- ✅ 任意位置复用:不限于前缀匹配,任何重复出现的文本都可以被缓存复用;
- ✅ 跨实例共享缓存:多个服务实例可共享缓存内容,提高整体利用率;
- ✅ 深度集成主流引擎:已与 vLLM 深度整合,未来将支持更多推理框架;
- ✅ 显著性能提升:典型场景下延迟降低 3-10 倍,GPU 资源消耗大幅减少;
- ✅ 适用多轮对话与 RAG 场景:特别适用于问答系统、检索增强生成(RAG)等长上下文任务。
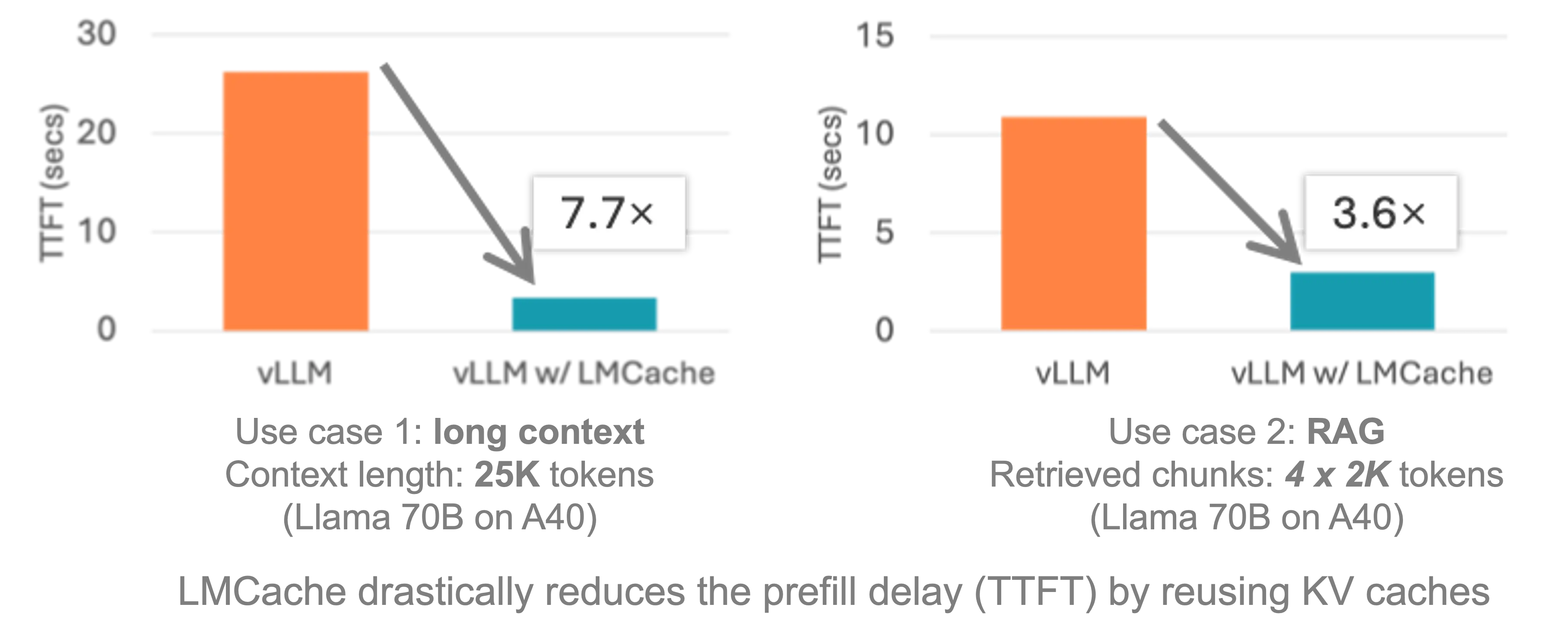
实测效果:性能与成本双赢
在实际测试中,结合 vLLM 推理引擎 使用 LMCache 后,在多个典型 LLM 应用场景中均表现出显著优化:
- 多轮问答(QA)响应更快;
- RAG 查询速度与准确性同步提升;
- 在长上下文处理中表现尤为突出。
据开发者反馈,LMCache 可帮助企业在保持高质量输出的同时,实现高达 8倍的性能提升 和 8倍的成本下降。
技术机制简析:KV 缓存复用
LMCache 的核心技术在于KV 缓存复用。在大模型推理过程中,每个 token 都会生成一组 Key-Value 状态用于注意力机制计算。对于重复出现的内容(如历史对话、固定模板、文档段落等),这些状态是可以复用的。
LMCache 利用这一特性,将已计算过的 KV 缓存保存下来,并在后续请求中直接复用,避免重复计算,从而:
- 减少 GPU 运算负担;
- 降低首 token 延迟(TTFT);
- 提升整体服务吞吐能力。
支持的典型应用场景
🧠 多轮对话优化
缓存完整的对话历史,使得每次新请求无需重新处理所有历史上下文,显著加快响应速度。
🔍 快速 RAG 查询
动态组合来自不同文本块的 KV 缓存,使检索增强生成(RAG)系统在处理大量文档时依然保持高效准确。
📁 文档处理工具
在需要频繁访问长文本的应用中(如AI助手、合同分析、报告生成等),提供无缝、低延迟的交互体验。
LMCache 的核心优势
| 特性 | 描述 |
|---|---|
| 可扩展性强 | 无需复杂路由机制即可横向扩展,适应大规模服务部署。 |
| 成本效率高 | 创新的压缩技术有效降低缓存存储与传输开销。 |
| 响应速度快 | 流式传输与即时解压技术确保缓存读取接近零延迟。 |
| 兼容性好 | 已适配 vLLM,后续将支持 TGI 等主流 LLM 推理引擎。 |
| 质量保障 | 支持离线内容升级,持续优化缓存命中与推理质量。 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











