
来自香港中文大学和字节跳动的研究团队联合提出了一种新型视频生成框架 —— InterActHuman,用于生成包含多人物、人-物交互场景的高质量人类中心视频。
该框架支持从文本描述、参考图像和音频输入中生成高度逼真、语义一致的多主体人类动画,并能将局部音频条件精确注入到对应的时空区域,实现精准的唇部同步与角色控制。
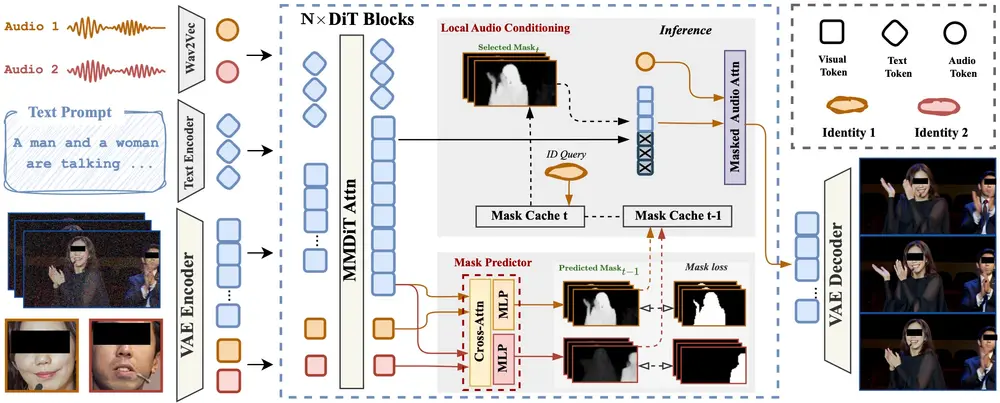
这项研究为音频驱动的复杂人类视频生成提供了全新思路,已在多个关键指标上达到当前最先进水平。
什么是 InterActHuman?
InterActHuman 是一种基于 扩散变换器(DiT) 的新型视频生成框架,具备以下核心能力:
| 功能 | 描述 |
|---|---|
| ✅ 多主体生成 | 支持同时生成多个独立人物,如对话场景中的不同说话者。 |
| ✅ 人-物交互 | 可建模人物与物体之间的互动,如手持工具、操作物品等行为。 |
| ✅ 局部音频注入 | 能将特定音频片段绑定到具体人物或动作部位,实现高精度音画同步。 |
| ✅ 多模态控制 | 支持文本描述 + 图像参考 + 音频输入的组合式控制方式。 |
这一框架突破了传统单主体视频生成的限制,是目前少数能够处理“多角色+多对象”复杂交互场景的解决方案之一。
实例演示:让视频生成更自然、更可控
举个例子,用户可以输入如下描述:
“在一个车库中,一个穿着深灰色T恤的黑发、有胡子的男人面向镜头,手里拿着一个小机械部件并说话。”
同时提供该男子的头部/全身图以及对应语音,InterActHuman 就能生成一段嘴唇动作与语音完美同步的视频,背景元素(如车库门、工具)也与描述一致。
更进一步,它还能处理多人对话场景:
比如两个或多个人物轮流说话,每个说话者的唇形都能与各自的音频精准对齐。
技术亮点解析
🧠 基于 DiT 架构,支持多步去噪优化
InterActHuman 采用扩散变换器(DiT)作为主干网络,利用其多阶段去噪机制逐步优化视频生成质量。
相比传统端到端方法,这种设计更易于融合多模态信息,并提升生成内容的空间一致性。
🎯 显式布局控制 + 迭代掩码预测
不同于以往将所有条件“一股脑”融合的做法,InterActHuman 引入了细粒度掩码预测器,逐帧推断每个主体的时空位置,并据此进行局部条件注入。
这种方式解决了“先有鸡还是先有蛋”的推理难题,确保音频信号能准确绑定到目标人物或物体。
🔊 局部音频注入:一人一音,精准同步
InterActHuman 的一大创新点在于实现了局部音频驱动:
- 用户可指定某段音频仅作用于某个角色;
- 支持同一角色在不同时间使用不同音频;
- 在多人物场景中,也能保持每段语音与相应人物唇形同步。
这为生成真实感更强、更具表现力的人类视频奠定了基础。
📦 多模态条件支持:文本、图像、音频灵活搭配
InterActHuman 允许用户通过多种方式进行控制:
- 文本描述:定义场景、人物外观与动作;
- 参考图像:指定人物外貌特征(如面部、服装);
- 音频输入:驱动语音与唇形同步;
- 交互提示:控制人与物体之间的互动方式。
这种灵活性使其适用于广泛的内容创作任务。
主要功能概览
| 特性 | 说明 |
|---|---|
| 🎬 多概念人类动画 | 支持多人物共现、人-物交互等复杂场景。 |
| 🔊 局部音频驱动 | 音频可精确绑定至特定人物或动作部位。 |
| 🖼️ 高质量视频输出 | 视觉效果逼真,语义一致性高,支持长视频生成。 |
| 🧩 多模态控制 | 支持文本、图像、音频等多种输入方式,便于定制化生成。 |
核心技术优势
| 优势 | 说明 |
|---|---|
| ✨ 显式布局控制 | 通过掩码预测明确控制每个角色的位置与运动轨迹。 |
| 🔄 迭代掩码预测 | 利用扩散模型的迭代特性,逐步优化空间定位,提高准确性。 |
| 🎧 多模态条件注入 | 文本、图像、音频可在生成过程中动态融合,提升表达能力。 |
| 🌐 高可扩展性 | 框架设计灵活,支持任意数量的概念图像与音频片段。 |
应用场景展望
InterActHuman 的发布,为多个领域带来了新的可能性:
🎥 对话视频生成
可用于虚拟会议助手、AI主播、客服机器人等场景,实现自然的多人对话视频生成,且每个角色都能拥有独立音频控制。
🤖 人-物交互视频
支持人物与物体的协同动作生成,如手持工具、操作设备等,非常适合用于教育、培训、虚拟现实等场景。
🎨 多样风格支持
不仅限于写实风格,InterActHuman 同样适用于卡通、手绘风格甚至动物拟人化视频生成,展现出良好的泛化能力。
测试结果与性能表现
在多项定量与定性评估中,InterActHuman 表现出显著优势:
- 唇部同步精度:优于现有主流方法;
- 人物一致性:生成角色在整个视频中保持稳定外观;
- 视频整体质量:视觉自然、动作连贯、细节丰富;
- 用户满意度:在多主体对话、个性化定制等任务中获得最高评分。
此外,研究人员还构建了一个包含超过260万对视频-实体标注数据的大规模训练管道,为模型持续进化提供了坚实的数据基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











