苹果公司最新发布的一项研究表明,当前主流的大型推理模型(Large Reasoning Models, LRMs)在面对高度复杂的问题时,依然存在显著的能力局限。即便是在引入了“链式思维”等结构化推理机制之后,这些模型的表现仍然远未达到人类水平。

这项研究由苹果的研究团队主导,旨在评估当前先进AI系统是否具备真正的泛化推理能力——即能否在没有明确训练数据覆盖的情况下解决新问题。研究人员选择了包括Claude 3.7 Sonnet Thinking和DeepSeek-R1 LRM在内的多个高级AI模型进行测试,并设计了一系列受控实验环境,以精确衡量其推理表现。
实验设计:从简单到复杂的谜题挑战
为了深入分析AI模型的推理能力,研究团队并未停留在传统的数学或编程基准测试上,而是设计了一组更具挑战性的任务,如经典的“汉诺塔”问题和“过河”谜题。这些任务具有可调节的复杂度,能够帮助研究人员逐步提升问题难度,从而观察AI在不同阶段的表现。
与以往研究不同的是,苹果团队不仅关注最终答案的准确性,还特别重视模型在解题过程中的“推理轨迹”。他们希望借此了解AI是否真的在“思考”,还是仅仅依赖于模式匹配和记忆。
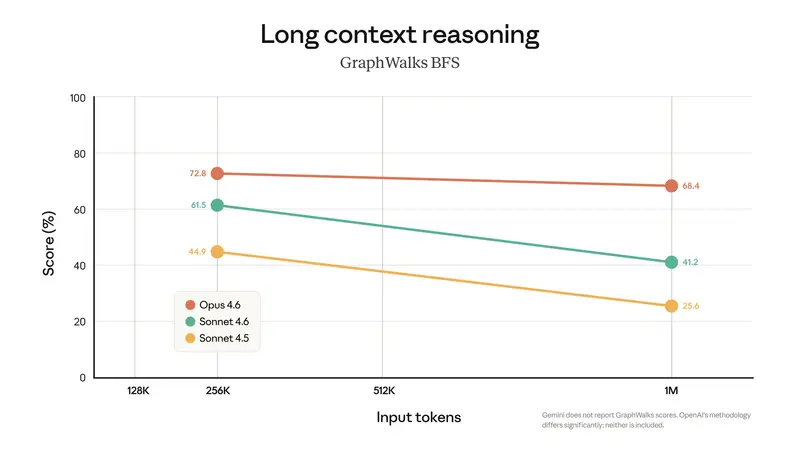
实验结果:复杂性越高,AI越无力
研究结果显示,在低复杂度任务中,不具备专门推理机制的标准大型语言模型(LLM)反而表现得更为高效准确。它们能够在较少计算资源下完成任务,说明在这种情况下,结构化的推理机制并不具备明显优势。
当问题复杂度上升至中等水平时,配备链式思维等推理机制的模型开始展现优势,能够超越标准LLM。然而,一旦任务复杂度进一步增加,所有模型都出现了全面失效的情况——无论提供多少计算资源,它们的准确率都趋近于零。
这一发现表明,目前的AI模型在应对高度复杂、需要多步逻辑推导的任务时,仍存在根本性的能力瓶颈。
深入分析:推理轨迹暴露AI弱点
通过对模型推理过程的详细追踪,研究人员发现了几个令人惊讶的现象:
- 推理长度不稳定:随着问题变难,模型通常会延长推理步骤,但在接近失败点时,它们却突然缩短推理过程,仿佛“放弃”了继续尝试。
- 执行算法困难:即使模型被明确告知了解题方法,它们也无法稳定地按照步骤执行,暴露出在逻辑控制方面的薄弱环节。
- 过度依赖训练数据:在熟悉的谜题上表现良好,但在陌生场景中迅速崩溃,说明AI的成功更多来源于对已有知识的记忆,而非真正意义上的推理能力。
AI推理仍处于初级阶段
苹果的研究清楚地指出,尽管当前的生成式AI在某些场景下展现出类人的推理能力,但这种能力是有限的、脆弱的。尤其是在缺乏足够训练样本或面临高复杂度任务时,AI的表现远不能与人类相提并论。
这项研究并非否定AI的发展潜力,而是提醒业界:我们距离实现真正具有通用推理能力的人工智能,还有很长的路要走。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











