
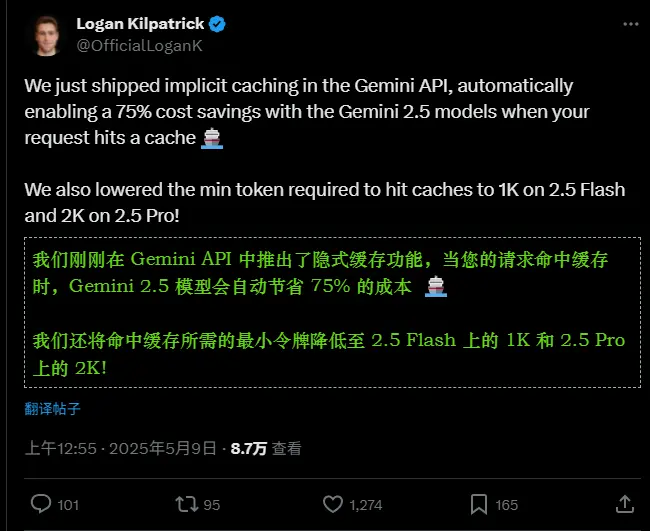
谷歌今天在Gemini API中引入了一项名为“隐式缓存”(implicit caching)的新功能,帮助第三方开发者更经济地使用其最新的AI模型。谷歌表示,这项功能可以为通过Gemini API传递的“重复上下文”提供高达75%的成本节省。该功能支持Gemini 2.5 Pro和2.5 Flash模型,标志着谷歌在优化AI模型使用成本方面迈出的重要一步。

什么是隐式缓存?
隐式缓存是一种自动化机制,用于识别和重用通过Gemini API发送的重复请求中的共同部分,从而减少计算需求和成本。与传统的显式缓存(explicit caching)不同,隐式缓存无需开发者手动定义高频提示或进行额外配置,默认对所有符合条件的请求启用。
隐式缓存的工作原理
- 当开发者向Gemini 2.5模型发送请求时,如果请求的前缀与之前的请求共享相同内容,则系统会自动将其标记为“命中缓存”。
- 系统将动态地为命中的缓存请求传递成本节省,而无需开发者干预。
谷歌在博客中解释道:“如果你的请求包含一个与之前请求相同的前缀,那么它就有资格命中缓存。我们将自动为你节省成本。”
显式缓存 vs. 隐式缓存
- 显式缓存的局限性
在此之前,谷歌提供的缓存机制主要是显式缓存,要求开发者手动定义最高频的提示。尽管这种方法理论上能够降低成本,但实际操作中往往涉及大量手动工作,并且一些开发者反映显式缓存可能导致API账单意外高企。 - 隐式缓存的优势
- 自动化:隐式缓存完全由系统自动处理,减少了开发者的负担。
- 低门槛触发:根据谷歌文档,隐式缓存的最小提示令牌数为:
- 2.5 Flash模型:1,024个令牌
- 2.5 Pro模型:2,048个令牌
这意味着即使较小的重复上下文也能触发缓存节省。
- 动态节省:开发者无需提前规划或调整代码,系统会自动识别并应用节省。
隐式缓存的实际应用场景
隐式缓存特别适用于需要频繁重复上下文的场景,例如:
- 对话系统:在聊天机器人或客服系统中,用户的问题通常具有相似的前缀(如问候语或常见问题)。隐式缓存可以显著降低这些重复请求的处理成本。
- 批量数据处理:对于需要处理大量类似输入的任务(如文本分类或翻译),隐式缓存可以帮助避免重复计算。
- 教育与培训工具:许多教育类AI工具会反复使用类似的提示模板(如练习题生成或知识点讲解)。隐式缓存可以显著降低这类应用的运营成本。
如何优化隐式缓存的使用?
为了最大化隐式缓存的效果,谷歌建议开发者遵循以下最佳实践:
- 将重复上下文放在请求开头:系统会优先检查请求的前缀部分,因此将重复内容放在开头可以增加缓存命中的机会。
- 将变化的部分放在请求末尾:如果某些上下文可能发生变化(如用户输入或动态参数),应将其放置在请求的末尾,以避免干扰缓存匹配。
潜在争议与需谨慎对待的方面
尽管隐式缓存听起来是一个极具吸引力的功能,但也存在一些需要注意的问题:
- 缺乏第三方验证:谷歌尚未提供独立的第三方验证来证明隐式缓存能如承诺般实现自动成本节省。早期使用者的反馈将是评估这一功能效果的关键。
- 对请求结构的依赖:隐式缓存的效果高度依赖于请求的结构设计。如果开发者未能合理组织请求内容,可能会导致缓存命中率较低,从而影响节省效果。
- 历史争议的影响:谷歌此前关于缓存成本节省的承诺曾引发争议,部分开发者对显式缓存的实现方式表示不满。因此,隐式缓存的推出需要更加透明和可信的沟通,以赢得开发者的信任。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











