Stability AI获得新的投资,并任命Prem Akkaraju为新CEOStability AI已经正式公布了来自一组新投资者的重大资金投入。该公司已任命Prem Akkaraju为首席执行官,并由Sean Parker出任执行主席。这一举措旨在加速Stability A...早报# Prem Akkaraju# Stability AI2年前01,0090
Google AI Studio 初学者指南:轻松掌握基础知识,即使您不是开发者谷歌作为全球领先的科技公司,推出了 Gemini 模型,可集成到各种 AI 应用中。为了帮助开发者轻松将 AI 集成到他们的应用中,谷歌于 2023 年推出了 Google AI Studio。这款工...教程# Google AI Studio12个月前01,0080
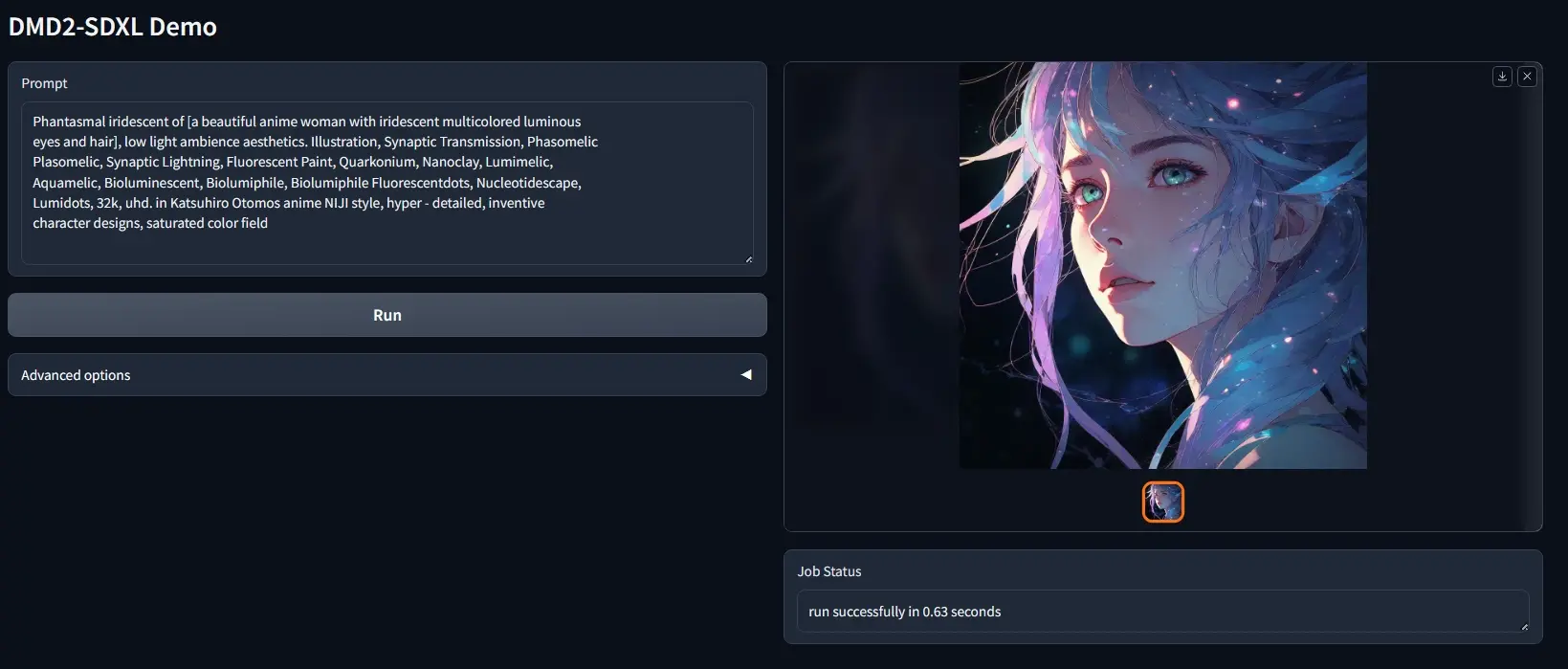
改进图像生成技术DMD2:通过高效的一步生成模型来加速图像生成过程,同时保持或甚至超越原始模型的质量麻省理工学院和 Adobe 研究中心的研究人员推出DMD2(Distribution Matching Distillation的改进版),这是一种改进图像合成技术,特别是针对大语言模型在图像生成...新技术# DMD2# 图像合成2年前01,0060
新型3D生成模型LN3Diff:快速生成高质量的3D对象来自南洋理工大学、北京大学和上海人工智能实验室推出新型3D生成模型LN3Diff,它是一个基于潜在空间的神经辐射场扩散模型,用于快速生成高质量的3D对象。 项目主页 GitHub 想象一下,你有一张2...新技术# 3D生成模型# LN3Diff2年前01,0040
自级联扩散模型Self-Cascade:快速适应高分辨率的图像和视频生成来自南洋理工大学、腾讯AI实验室、香港科技大学和克莱姆森大学的研究人员提出了一种名为自级联扩散模型(Self-Cascade Diffusion Model)的新方法,该方法利用了低分辨率模型的丰富知...新技术# Self-Cascade# 自级联扩散模型2年前01,0020
微软将在Windows 11 Build 26052 预览版引入新功能,将原生支持 Sudo 命令微软已经在Windows 11 预览版 26052中引入了新功能Sudo for Windows。对于熟悉macOS和Linux系统的用户来说,sudo命令一定不会陌生。 官方文档 GitHub su...教程# Sudo# Windows 11# 微软2年前01,0020
腾讯音乐娱乐推出开源虚拟人视频生成框架MusePose腾讯音乐娱乐旗下天琴实验室推出开源虚拟人视频生成框架MusePose,MusePose 是 Muse 开源系列的最后一个组件,与 MuseV 和 MuseTalk 一起,标志着向构建端到端虚拟人物生成...新技术# MusePose# 虚拟人2年前01,0000
独立条件引导(ICG)和时间步引导(TSG):在不牺牲这两种特性的情况下,改善生成模型的表现苏黎世联邦理工学院和迪士尼搜索的研究人员提出了两种新的图像生成模型引导方法——独立条件引导(ICG)和时间步引导(TSG),它们可以在不牺牲这两种特性的情况下,改善生成模型的表现。这些方法可以提高生成...新技术# ICG# TSG# 时间步引导2年前09930
新型文本到视频生成框架VideoTetris:专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战来自北京大学和快手科技的研究人员推出新型文本到视频生成框架VideoTetris,此框架专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战。VideoTetri...新技术# VideoTetris# 北京大学# 快手2年前09920
新型文生图风格迁移技术InstantStyle-Plus:在生成图像的同时保留原始图像的内容和风格InstantX团队推出新型文生图风格迁移技术InstantStyle-Plus,在生成图像的同时保留原始图像的内容和风格。这项技术特别适用于需要将一种图像的风格应用到另一种图像上,但又希望保留原始图...新技术# InstantStyle-Plus# 风格迁移2年前09900
xAI 即将推出 Grok 系列重大更新:Grok 3.5、语音视觉功能与更多新特性埃隆·马斯克旗下的 xAI 正在为其 Grok 系列产品准备一系列令人期待的更新,涵盖模型性能提升、新功能开发以及用户体验优化。这些更新不仅展示了 xAI 在人工智能领域的持续投入,也进一步缩小了 G...早报# Grok# Grok 3.5# xAI12个月前09870
MVEdit:用于3D对象合成和编辑的通用3D扩散适配器来自斯坦福大学、加州大学圣地亚哥分校和Apparate Labs的研究人员推出MVEdit,这是一个用于3D对象合成和编辑的通用3D扩散适配器。 项目主页 Demo GitHub MVEdit的核心功...新技术# 3D# MVEdit2年前09790