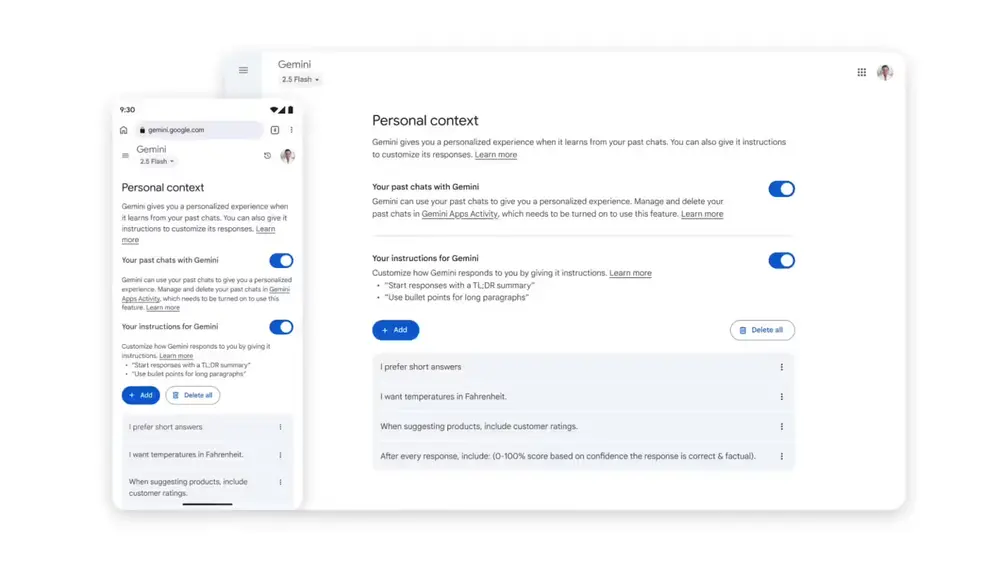
谷歌为 Gemini 推出有限个性化功能,记忆能力仍落后于竞品谷歌正在为其 AI 助手 Gemini 逐步引入个性化功能,迈出追赶 OpenAI 与 Anthropic 的关键一步。近日,公司宣布上线“个人上下文”与“临时聊天”功能,并强化用户对数据使用的控制权...早报# Gemini# 记忆# 谷歌6个月前01530
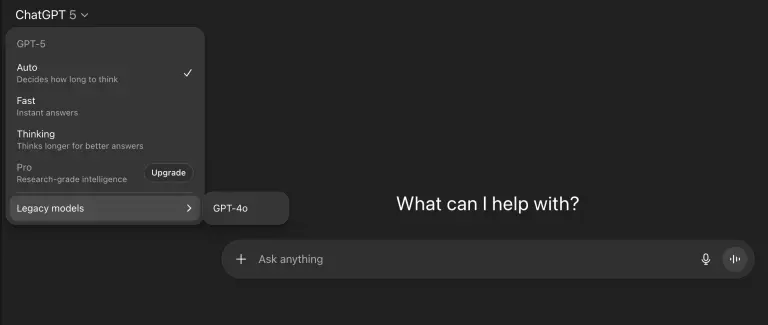
GPT-5 路由器未达预期,OpenAI 重启模型选择器上周,OpenAI 在发布 GPT-5 时描绘了一个理想图景:一个统一、智能的 AI 模型,通过内置的“路由器”自动判断用户问题的复杂程度,并调用最合适的处理方式。公司希望借此淘汰长期存在的“模型选择...早报# GPT-5# OpenAI6个月前03060
Anthropic 收编 Humanloop 核心团队,加码企业级 AI 安全能力Anthropic 正在通过一次关键的人才整合,强化其在企业 AI 领域的竞争力。该公司已确认,收购初创公司 Humanloop 的联合创始人及大部分技术团队,此举被视为其应对日益激烈的企业 AI 人...早报# Anthropic# Humanloop6个月前01340
xAI联合创始人伊戈尔·巴布什金宣布离职,将专注AI安全投资周三,埃隆·马斯克旗下AI公司 xAI 的联合创始人伊戈尔·巴布什金(Igor Babuschkin)在 X 平台发布公开信,宣布正式离开公司。这一消息标志着 xAI 创始团队的一次重要变动,也折射出...早报# xAI# 伊戈尔·巴布什金6个月前01410
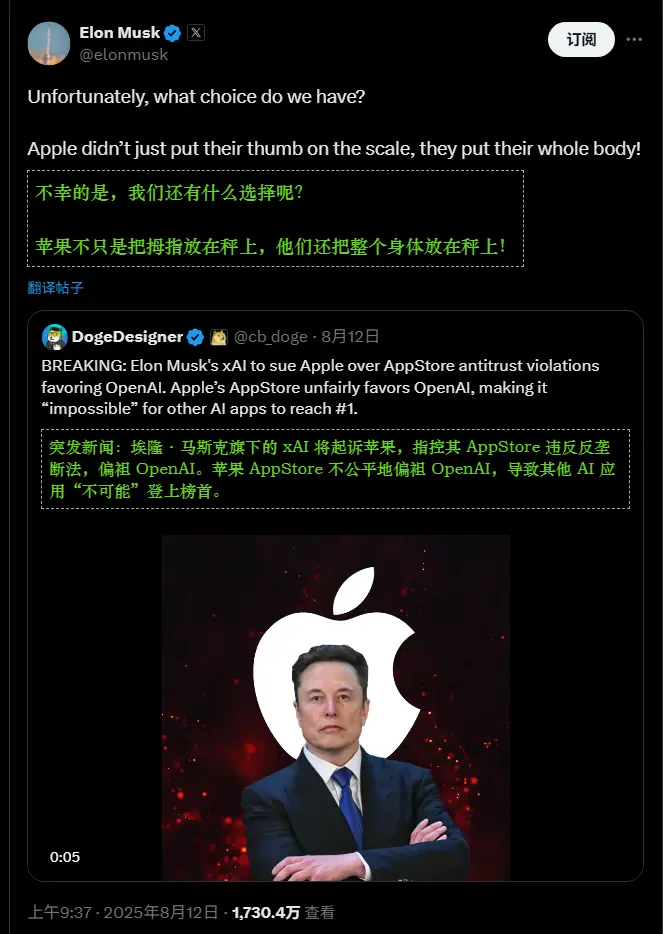
马斯克指控苹果操纵应用商店排名,xAI拟提起诉讼埃隆·马斯克再次将矛头指向科技巨头苹果。近日,他通过旗下AI公司 xAI 宣布将对苹果采取“立即法律行动”,指控其在 App Store 中操纵排名,偏袒 OpenAI 的 ChatGPT,而刻意压制...早报# xAI# 苹果# 马斯克6个月前02540
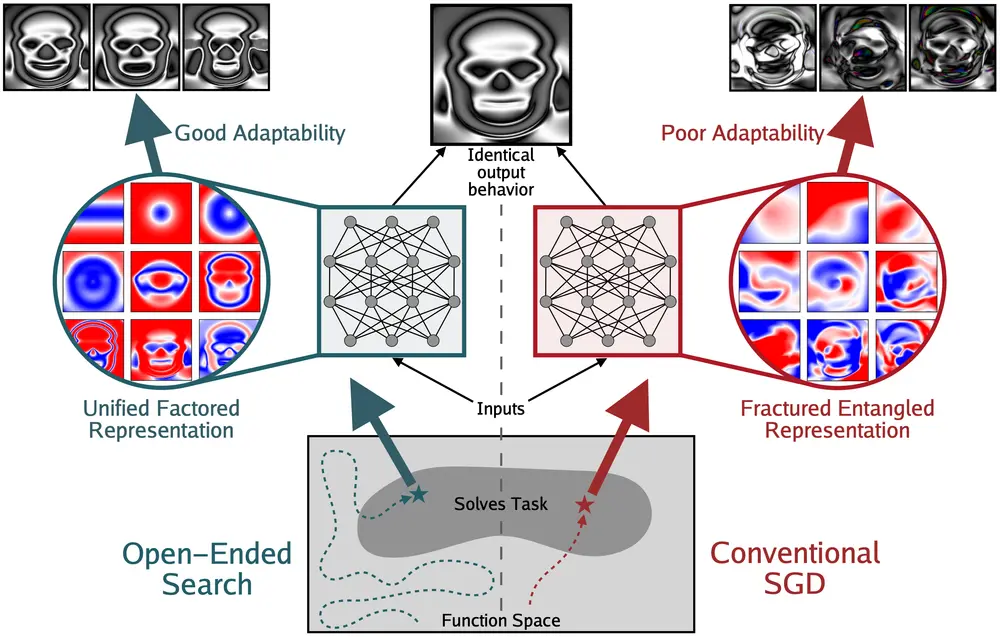
模型变强了,内部表示就更好了吗?MIT等提出“碎片化纠缠表示(FER)”假说当我们看到大模型在各种任务上不断刷新性能纪录时,一个隐含的信念常常浮现:性能提升 = 内部表示更优。这种观点被称为“表示乐观主义”(Representational Optimism)——即认为随着模...新技术# FER# 碎片化纠缠表示6个月前03060
DynamicFace:一种面向图像与视频的高保真人脸交换方法人脸交换(Face Swapping)技术旨在将一个人的身份特征迁移到另一个人的面部图像或视频中,同时保留目标人物的表情、姿态、发型和背景等属性。近年来,随着生成模型的发展,人脸交换已能生成高度逼真的...新技术# DynamicFace# 人脸交换6个月前03830
Anthropic 回应 OpenAI:1 美元向美国政府机构提供 Claude在 OpenAI 宣布以每年 1 美元的价格向美国联邦行政部门提供 ChatGPT Enterprise 仅一周后,Anthropic 迅速出手,将这场“AI 入政”竞赛推向新高度。 周二,Anthr...早报# Anthropic# Claude6个月前03750
Perplexity 报价 345 亿美元收购 Chrome?一场战略喊话,还是真实意图?AI 搜索公司 Perplexity 向谷歌提出以 345 亿美元现金收购 Chrome 浏览器。 更令人意外的是,这一报价是未经请求的主动出价,且已由 Perplexity 向 TechCrunch...早报# Chrome# Perplexity6个月前02240
Qwen-Image 使用指南:如何用提示词与参数生成高质量图像在闭源图像模型主导的今天,阿里巴巴推出的 Qwen-Image 成为一股清流——它不仅性能强大,更以 Apache 2.0 开源协议发布,允许企业、开发者和创作者自由使用、修改和部署。 这一特性使其迅...教程# Qwen-Image# 提示词6个月前01,1950
Anthropic 推出“记忆”功能:Claude 现可记住你的历史对话周一,Anthropic 为其 AI 聊天机器人 Claude 推出了一项备受期待的新功能:对话记忆。 现在,你可以直接对 Claude 说:“还记得我们上次讨论的项目吗?” 它将主动搜索过往对话,读...早报# Anthropic# Claude# 记忆6个月前02860
Anthropic 推出百万 tokens 上下文:Claude Sonnet 4 支持 75 万字输入Anthropic 正在将其 AI 模型的上下文窗口推向新高度。近日,公司宣布其主力模型 Claude Sonnet 4 现已支持 100 万个 tokens 的上下文长度,相当于可一次性处理 75 ...早报# Anthropic# Claude Sonnet 46个月前04170