Anthropic 正在将其 AI 模型的上下文窗口推向新高度。近日,公司宣布其主力模型 Claude Sonnet 4 现已支持 100 万个 tokens 的上下文长度,相当于可一次性处理 75 万字文本或 7.5 万行代码——几乎等同于整部《指环王》三部曲的篇幅。
这一更新不仅将此前 20 万 tokens 的限制提升了五倍,也超过了 OpenAI GPT-4 Turbo(40 万 tokens)的两倍以上,标志着大模型在长上下文处理能力上的又一次跃进。
该功能已通过 Anthropic API 向企业客户开放,并同步上线 Amazon Bedrock 和 Google Cloud Vertex AI 等云服务平台。
为什么长上下文如此重要?
对于软件工程、研究分析等复杂任务而言,上下文长度直接决定了 AI 的“记忆力”和理解深度。
- 当你需要 AI 为一个大型项目添加新功能时,它能否看到整个代码库,而非零散的文件片段?
- 当你要求模型进行跨文档推理时,它是否能记住前几十页的内容?
更长的上下文意味着:
- ✅ 更完整的项目理解
- ✅ 更少的信息丢失
- ✅ 更连贯的多轮推理与自主编码能力
Anthropic 平台产品负责人 Brad Abrams 表示:“我们预计 AI 编码平台将从此次更新中获得巨大收益。” 他特别指出,Claude 在长时间代理式编码任务中表现更优——模型可以记住自身过去数小时内的所有操作步骤,实现真正意义上的“自主工作流”。
背后是激烈的开发者生态之争
尽管 Anthropic 没有直接点名,但这次升级的背景清晰可见:对抗 OpenAI 的 GPT-4 Turbo,尤其是其在开发者市场的强势渗透。
目前,Anthropic 已建立起 AI 模型企业服务中最具规模的开发者生态之一,其客户包括:
- GitHub Copilot(微软)
- Windsurf
- Cursor(由 Anysphere 开发)
这些平台曾长期将 Claude 作为默认或可选模型。然而,随着 OpenAI 推出 GPT-4 Turbo 并以更具竞争力的定价吸引客户,局势正在发生变化。
一个标志性事件是:Cursor CEO Michael Truell 亲自参与了 GPT-4 Turbo 的发布活动,并宣布 GPT-4 Turbo 已成为 Cursor 新用户的默认 AI 模型。
这无疑对 Anthropic 构成了直接挑战。
不只是“堆参数”:Anthropic 关注“有效上下文”
面对 Google Gemini 2.5 Pro(200 万 tokens)和 Meta Llama 4 Scout(1000 万 tokens)等更激进的上下文扩展,Anthropic 并未盲目追求数字极限。
Abrams 强调,公司研究团队不仅关注“最大上下文长度”,更重视“有效上下文窗口”——即模型真正能理解和利用的信息比例。
“我们发现,仅仅提供海量输入并不等于更好的性能。”他表示,“关键在于模型能否在长序列中保持注意力、推理一致性和信息检索准确性。”
尽管他未透露具体技术细节,但这一表态暗示 Anthropic 在上下文压缩、注意力机制优化和记忆建模方面可能已有深入布局。
商业策略:从“按量计费”到“价值定价”
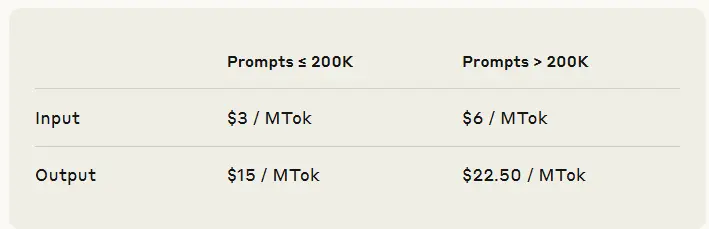
随着上下文窗口扩大,Anthropic 也调整了其 API 定价策略:
| 项目 | ≤200K tokens | >200K tokens |
|---|---|---|
| 输入 tokens | $3 / 百万 | $6 / 百万 |
| 输出 tokens | $15 / 百万 | $22.5 / 百万 |
这意味着,当用户使用超过 20 万 tokens 的上下文时,将支付更高的费用。
这一策略反映了 Anthropic 的商业逻辑:为高价值、高复杂度的企业任务提供差异化服务。相比 OpenAI 的统一费率,Anthropic 更倾向于根据资源消耗和任务难度进行分层定价。
同时发布:Claude Opus 4.1 更新
上周,Anthropic 还推出了其旗舰模型 Claude Opus 4.1 的更新版本,进一步提升了在代码生成、数学推理和复杂规划任务上的表现。
Opus 系列本就以强大但昂贵著称,此次更新强化了其在高端企业场景中的竞争力,与 Sonnet 4 形成高低搭配,覆盖更广泛的应用需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











