新型视频人脸超分辨率技术KEEP:让模糊不清的人脸视频变得清晰南洋理工大学 S-Lab推出一种新型视频人脸超分辨率技术KEEP,也就是让模糊不清的人脸视频变得清晰。例如,你手里有一些老旧电影的片段,或者监控摄像头拍到的模糊人脸,这项技术能够让这些人脸在视频中变得...新技术# KEEP# 视频人脸超分辨率2年前01,5820
如何从HuggingFace导入新模型到Ollama在《如何在本地安装及使用Ollama,轻松玩转本地大语言模型》这篇文章里,已经详细向大家介绍了Ollama这款软件如何安装及使用,虽然官方的模型库已经提供了大量可用模型,但与Hugging Face上...教程# HuggingFace# Ollama2年前01,5240
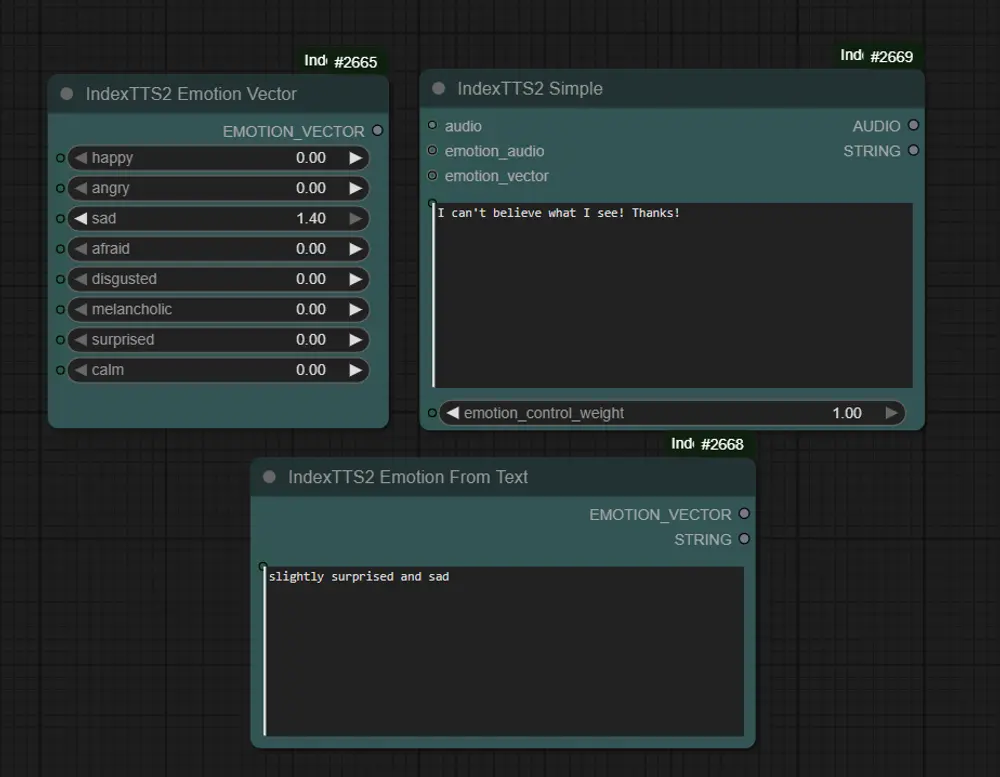
ComfyUI-IndexTTS2:轻量IndexTTS-2包装器实现语音克隆 + 情感控制,附安装与节点指南在 AI 音频生成领域,高质量的文本转语音(TTS)系统正从“能说”向“会表达”演进。近期,由 B站IndexTeam 推出的 IndexTTS-2 因其出色的语音克隆能力与细粒度情感控制机制受到关注...百科# ComfyUI-IndexTTS2# IndexTTS-27个月前01,5040
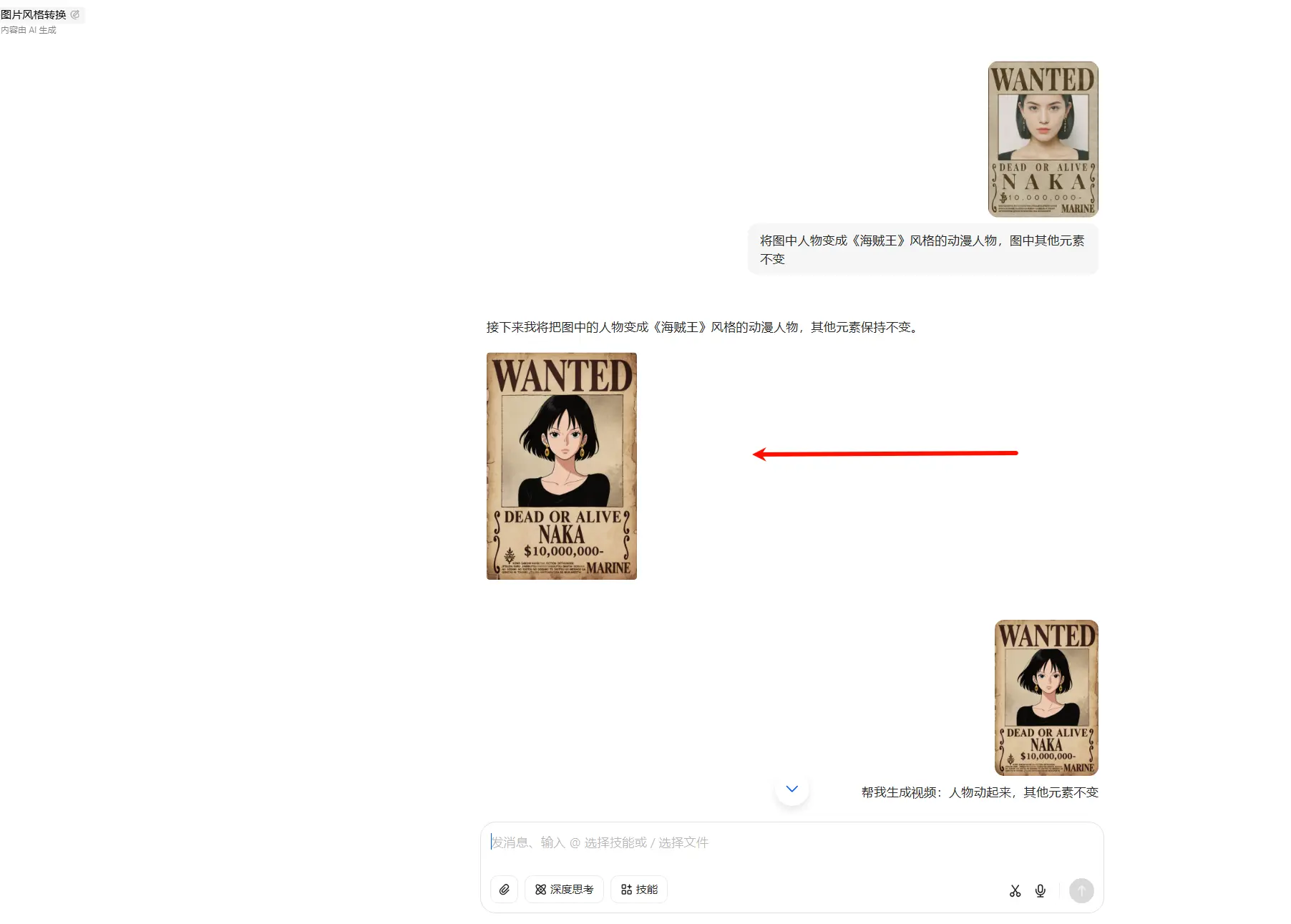
豆包AI修图大升级!一键P图、换风格、删杂物,一句话搞定!字节跳动旗下多功能AI助手 豆包(Doubao) 宣布其 App 内的智能修图功能迎来重大更新。此次升级基于全新图像编辑模型 SeedEdit 3.0,带来了更多实用又有趣的 P 图玩法,让普通用户也...早报# AI修图# 豆包10个月前01,4510
Stable Diffusion中的embedding是什么?什么是文本嵌入?在使用Stable Diffusion进行生图的时候,我们常常会用到embedding模型,这个embedding模型是什么呢?在中文中通常被翻译为“文本嵌入”,其实也就是我们之前介绍的Textual...科普# embedding# Stable Diffusion# 文本嵌入模型2年前01,4250
Stable Diffusion提示词简介、语法规则、常用提示词与浏览器插件推荐在使用 Stable Diffusion模型进行绘画的时候,最令人头疼的可能就是提示词该怎么写,无论是Stable Diffusion Web UI还是ComfyUI都有插件可以解决这个问题,不过大家...科普# ComfyUI# negative prompts# positive prompts2年前01,3840
新型SD加速模型PCM:解决在高分辨率、文本条件图像生成中的一些现有问题而设计香港中文大学、 Avolution AI 、Hedra、上海人工智能实验室、商汤和斯坦福大学的研究人员推出新的SD加速模型PCM(Phased Consistency Model,分阶段一致性模型...新技术# LCM# PCM# SD模型2年前01,3820
新型图像生成模型Diffusion Mamba(DiM):通过结合Mamba序列模型的效率和扩散模型的表现力,来高效生成高分辨率的图像来自香港大学、华为诺亚方舟实验室、清华大学和上海交通大学的研究人员推出新型图像生成模型Diffusion Mamba(简称DiM),它融合了基于状态空间模型(SSM)的高效序列模型——Mamba,与扩...新技术# Diffusion Mamba# DiM# 图像生成2年前01,3810
字节跳动推出PuLID:用于个性化文本到图像的生成字节跳动推出PuLID,它用于个性化文本到图像(Text-to-Image,简称T2I)的生成。PuLID的全称是“Pure and Lightning ID customization”,即纯粹和闪...新技术# PuLID# 个性化图像生成# 字节跳动2年前01,3800
一种新颖的模型微调方法DoRA:比LoRA更精细、更全面的微调策略DoRA(Weight-Decomposed Low-Rank Adaptation)是一种用于微调(fine-tuning)大型预训练模型的新方法。DoRA的核心思想是将预训练模型的权重分解为两个部...新技术# DoRA# Lora# 模型微调2年前01,3280
零成本尝鲜 OpenClaw:一部安卓手机就能跑起本地 AI 助手最近,不少用户分享了通过部署 OpenClaw(原名 Clawdbot)实现自动化、提升效率甚至“改变人生”的体验。但很多人误以为必须拥有一台 Mac 或高性能 PC 才能运行它——其实不然。 你只需...教程# OpenClaw# 安卓手机2个月前01,3170
Windows 11 新增命令行文本编辑器:Microsoft Edit 使用指南微软为 Windows 命令提示符和 PowerShell 用户带来了一款全新的 CLI(命令行界面)文本编辑器——Microsoft Edit。这是一个轻量、开源、功能齐全的命令行文本编辑工具,适用...教程# Microsoft Edit# Windows 11# 命令行文本编辑器11个月前01,3100