英伟达推出视频重光照技术UniRelight:通过对单张图像或视频进行光照条件的修改,实现场景在不同光照下的视觉效果呈现英伟达、多伦多大学和Vector 研究所的研究人员发布视频重光照(relighting)技术UniRelight,通过对单张图像或视频进行光照条件的修改,实现场景在不同光照下的视觉效果呈现。 项目主页...新技术# UniRelight# 视频重光照技术9个月前03730
新型训练自由高分辨率图像生成方法HiWave:利用预训练的扩散模型生成高质量的高分辨率图像苏黎世联邦理工学院和迪斯尼研究院的研究人员推出新型训练自由(training-free)高分辨率图像生成方法HiWave,利用预训练的扩散模型生成高质量的高分辨率图像。 论文地址:https://ar...新技术# HiWave# 高分辨率9个月前02120
用于生成 4D 场景(即包含时间和空间维度的视频)框架4Real-Video-V2 :从文本提示中创建 4D 场景Snap和阿卜杜拉国王科技大学的研究人员推出 4Real-Video-V2 框架,用于生成 4D 场景(即包含时间和空间维度的视频)。该框架能够从文本提示中创建 4D 场景,通过结合扩散模型直接生成同...新技术# 4Real-Video-V29个月前02320
SimpleGVR:轻量高效视频超分辨率模型,让低清视频也能高清呈现由澳门大学智慧城市物联网国家重点实验室、中国科学院深圳先进技术研究院、清华大学、快手科技和深圳理工大学联合研究团队提出了一种新型视频超分辨率(Video Super-Resolution, VSR)模...新技术# SimpleGVR# 视频超分辨率模型9个月前04260
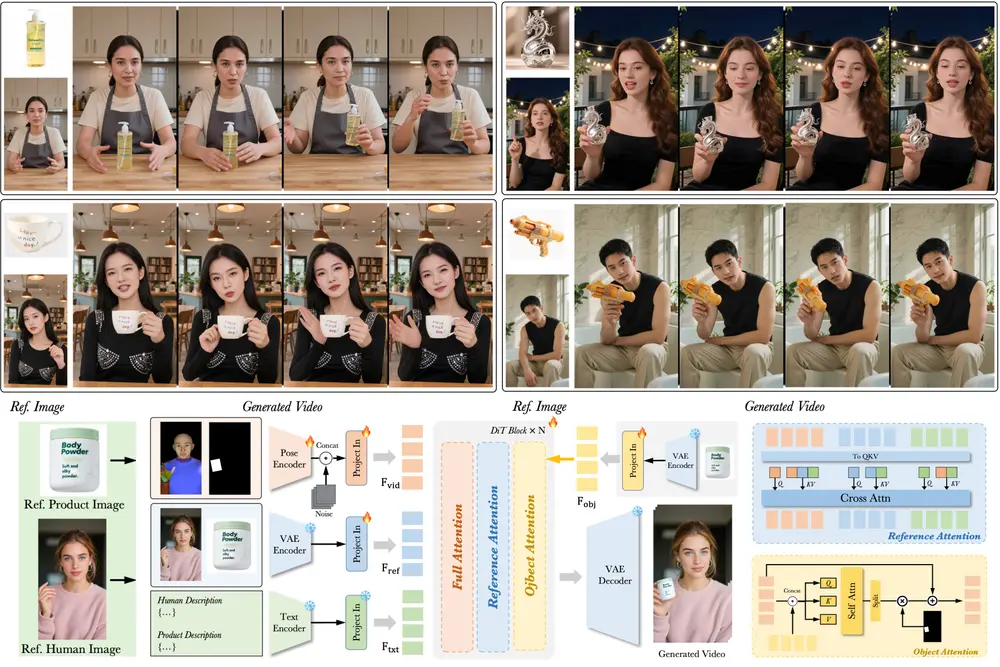
DreamActor-H1:字节跳动推出高保真人类-产品演示视频生成框架在电商广告、虚拟试穿、交互式媒体等场景中,如何高效生成高质量的人类-产品演示视频,一直是视觉生成领域的重要挑战。 近日,字节跳动 AI 实验室提出了一种全新的视频生成框架——DreamActor-H1...新技术# DreamActor-H1# 字节跳动9个月前03060
腾讯混元推出新型框架 Hunyuan-GameCraft:为游戏环境生成高动态、交互式的视频内容腾讯混元项目组和华中科技大学的研究人员推出新型框架 Hunyuan-GameCraft,为游戏环境生成高动态、交互式的视频内容。Hunyuan-GameCraft 能够从单张图像和对应的提示出发,生成...新技术# Hunyuan-GameCraft# 腾讯混元9个月前04000
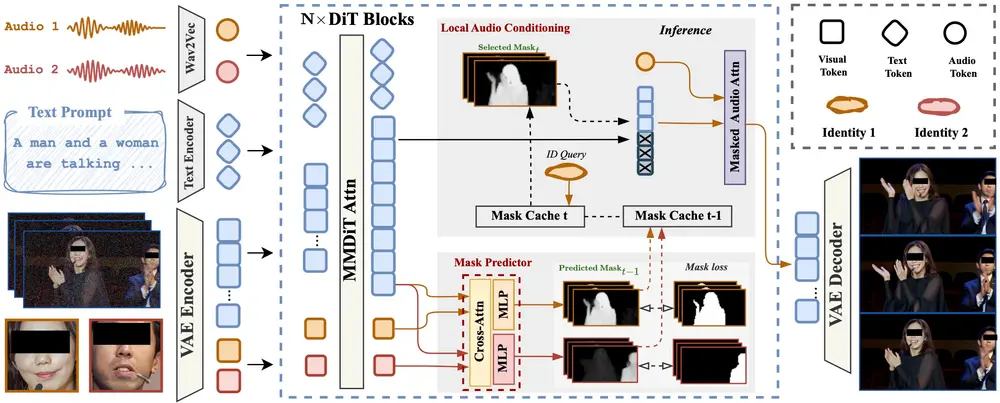
InterActHuman:港中大 & 字节跳动联合推出多概念人类动画生成框架来自香港中文大学和字节跳动的研究团队联合提出了一种新型视频生成框架 —— InterActHuman,用于生成包含多人物、人-物交互场景的高质量人类中心视频。 项目主页:https://zhenzhi...新技术# InterActHuman# 多概念人类动画生成9个月前02220
LMCache:为大语言模型加速的新一代缓存系统随着大语言模型(LLM)在各类应用场景中的广泛部署,如何提升推理效率、降低延迟、节省资源成为关键挑战。近日,开源项目 LMCache 正式亮相,它是一个专为 LLM 服务优化的高性能缓存引擎,显著降低...新技术# LMCache# 大语言模型# 缓存9个月前03660
英伟达联合团队提出新型连续时间流图(flow map)模型 AYF:统一扩散与流模型的少步生成方案由英伟达、多伦多大学及矢量研究所联合提出一种新型的连续时间流图(flow map)模型Align Your Flow(AYF) ,显著提升扩散模型和基于流的生成模型的采样效率。这些模型虽然在图像与文本...新技术# Align Your Flow# AYF# 英伟达9个月前03730
基于“幅度感知”的新型缓存机制MagCache:用于加速图像和视频扩散模型的生成过程近年来,视频扩散模型在生成高质量视频方面取得了显著进展,但其计算成本高、推理速度慢的问题始终是落地的一大障碍。 为了解决这一难题,来自北京大学和华为的研究人员在最新论文中提出了 MagCache ...新技术# MagCache# 幅度感知# 模型加速9个月前04420
香港大学 & 达摩院等联合推出:首个第一人称现实世界模拟器 PlayerOne由香港大学、阿里达摩院、湖畔实验室和华中科技大学联合研发的全新现实世界模拟系统 PlayerOne 正式亮相。这是首个以第一人称(egocentric)视角为核心的现实世界模拟器,标志着AI在沉浸式交...新技术# PlayerOne# 现实世界模拟器9个月前02620
苹果推出可扩展生成模型STARFlow:基于归一化流(NFs),在高分辨率图像合成方面取得了显著的成果苹果推出了一个名为STARFlow的可扩展生成模型,它基于归一化流(Normalizing Flows,NFs),在高分辨率图像合成方面取得了显著的成果。STARFlow的主要构建块是Transfor...新技术# STARFlow# 可扩展生成模型9个月前01900