类卷积局部注意力策略CLEAR:提升FLUX模型在高分辨率图像生成任务中的效率在图像生成领域,DiT(Diffusion Transformer)架构凭借其卓越的表现成为前沿技术。然而,该架构的核心——用于建模令牌间关系的注意力机制,由于其计算复杂度为二次方,导致在处理高分辨率...新技术# CLEAR# FLUX模型1年前03640
Unpacking SDXL Turbo: 使用稀疏自编码器来解释和理解文本到图像模型,特别是SDXL Turbo模型的内部工作机制稀疏自编码器(SAEs)已成为逆向工程大语言模型(LLMs)的核心组成部分。SAEs通过将中间表示分解为可解释特征的稀疏和,促进了对模型内部机制的更好理解和控制。然而,类似的分析和方法在文本到图像模型...新技术# SDXL Turbo# 稀疏自编码器1年前03640
新型图像编辑方法FluxSpace:基于修正流变换器(如Flux)来实现文本引导的图像编辑校正流模型(如 Flux)在图像生成中已成为主导方法,展示了高质量图像合成的卓越能力。然而,尽管它们在视觉生成中表现出色,校正流模型在图像的解耦编辑方面往往表现不佳。这一限制阻碍了在不影响图像无关部分...新技术# FLUX# FluxSpace# 图像编辑1年前03590
Allen人工智能研究所推出OLMoTrace:让大语言模型透明化,追溯AI决策的真实来源在企业AI应用中,大语言模型(LLM)的“黑盒”特性一直是阻碍其大规模采用的主要障碍之一。如何理解模型输出的来源、提升透明度并增强信任,成为行业亟需解决的问题。本周,Allen人工智能研究所(Ai2...新技术# Ai2# OLMoTrace# 大语言模型11个月前03570
高质量、人工奖励数据集HumanEdit:专为指令引导的图像编辑而设计天工AI、新加坡国立大学、北京大学和南洋理工大学的研究人员推出高质量、人工奖励数据集HumanEdit,专为指令引导的图像编辑而设计。该数据集通过开放式语言指令实现精确和多样化的图像操作,旨在解决现有...新技术# HumanEdit1年前03570
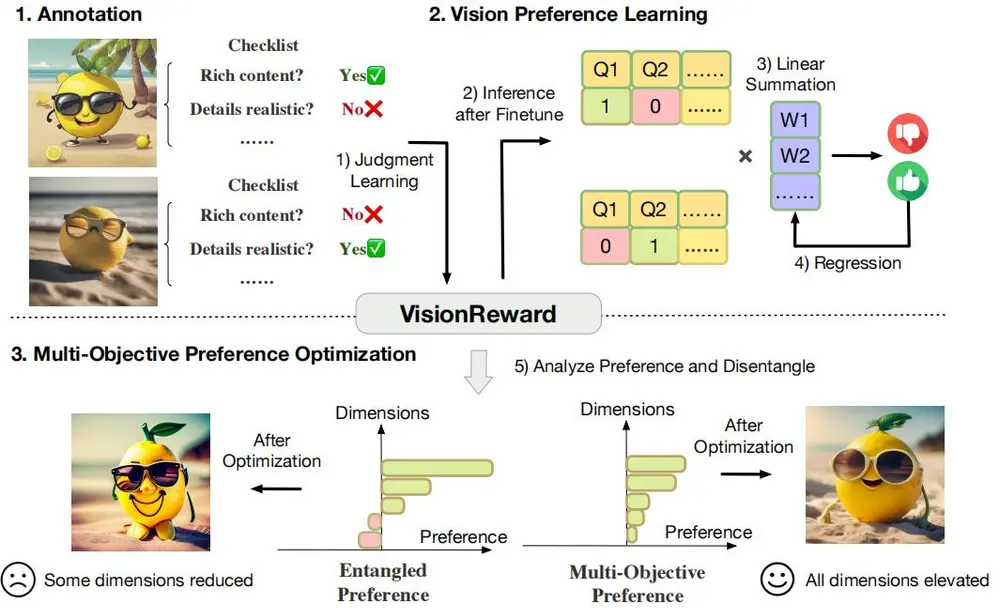
VisionReward:用于图像和视频生成的细粒度多维度人类偏好学习框架清华大学和智谱AI的研究人员推出VisionReward,这是一个用于图像和视频生成的细粒度多维度人类偏好学习框架。VisionReward通过构建一个细粒度且多维度的奖励模型,将人类对图像和视频的偏...新技术# VisionReward1年前03550
零样本视频对象插入框架VideoAnydoor:能够在视频中高精度地插入给定对象,并且允许用户精确控制对象的运动由香港大学和阿里巴巴达摩院等机构的研究团队推出零样本视频对象插入框架VideoAnydoor ,它能够在视频中高精度地插入给定对象,并且允许用户精确控制对象的运动。这项技术的核心挑战在于既要保留参考对...新技术# VideoAnydoor# 视频对象插入1年前03540
清华大学与清程极智开源大模型推理引擎“赤兔 Chitu”,实现 DeepSeek 推理成本降低一半、性能翻番清华大学高性能计算研究所翟季冬教授团队与清华系科创企业清程极智联合宣布,大模型推理引擎“赤兔 Chitu”现已正式开源。该引擎首次实现了在非英伟达 Hopper 架构 GPU 及各类国产芯片上原生运行...新技术# Chitu# DeepSeek# 大模型推理引擎1年前03530
Madd模型:通过引入“功能性”概念,旨在根据各种位置提示将任何对象无缝插入任何场景中图像合成是计算机视觉中的一个常见任务,涉及将前景对象无缝集成到背景场景中。传统的图像合成方法通常依赖于人为的编辑或预定义的规则,难以处理前景对象与背景场景之间的复杂相互作用。为了应对这一挑战,哈佛大学...新技术# Madd模型# 图像编辑1年前03530
适用于FLUX模型!新型零样本主题驱动图像生成方法Diptych Prompting主题驱动的文本到图像生成旨在通过准确捕捉主体的视觉特征和文本提示的语义内容,在期望的上下文中生成新主体的图像。传统方法依赖于耗时耗资源的微调以实现主题对齐,而最近的零样本方法则依赖于即时的图像提示,通...新技术# Diptych Prompting# FLUX模型1年前03520
无监督指令驱动图像编辑框架UIP2P:在不需要真实编辑图像数据集的情况下,根据文本指令对图像进行编辑现有的基于指令的图像编辑方法通常依赖于监督学习,需要包含输入图像、编辑图像和编辑指令的三元组数据集。这些数据集通常通过现有编辑方法或人工标注生成,引入了偏差并限制了模型的泛化能力。为了克服这些挑战,苏...新技术# UIP2P# 图像编辑1年前03510
英伟达推出Add-it:基于文本指令在图像中添加对象的创新方法英伟达、特拉维夫大学和巴伊兰大学的研究人员推出一个名为Add-it的系统,它是一种无需训练的方法,可以在图像中根据文本提示添加对象。这种方法扩展了预训练扩散模型的注意力机制,以整合来自三个关键来源的信...新技术# Add-it# 英伟达1年前03510