新型图像超分辨率技术S3Diff:让模糊的低分辨率图片变清晰中山大学深圳校区网络科学与技术学院、南洋理工大学S实验室和华为诺亚方舟实验室的研究人员推出新型图像超分辨率技术S3Diff ,简单来说,这是一种能让模糊的低分辨率图片变清晰的方法。研究团队引入了一种新...新技术# S3Diff# 图像超分辨率1年前08820
图像修补任务Reflecting Reality:专门用于创建逼真的镜面反射印度理工学院班加罗尔分校视觉与人工智能实验室、三星印度研发中心和牛津大学视觉几何组的研究人员推出Reflecting Reality,它专门用于创建逼真的镜面反射。简单来说,可以处理给定的图片,自动在...新技术# Reflecting Reality# 镜面反射2年前05960
多功能图像到图像视觉助手PixWizard:根据自由形式的语言指令执行图像生成、编辑和转换香港中文大学MMLab、北京大学和上海人工智能实验室的研究人员推出一种多功能的图像到图像视觉助手 PixWizard,它可以根据自由形式的语言指令执行图像生成、编辑和转换。简单来说,PixWizard...新技术# PixWizard2年前05000
ColorfulShading:能够在复杂的环境中准确地分离出物体的颜色和光照效果加拿大西蒙弗雷泽大学的研究人员推出ColorfulShading,它能够将真实世界中的照片中的表面反射率(也就是物体本来的颜色)和照明效果(比如光线如何影响物体的外观)分离开来。简单来说,它可以将一张...新技术# ColorfulShading2年前04210
Meta推出个性化图像生成模型Imagine yourself:根据参考照片,生成遵循特定文字描述的新图像,而且不需要对每个新用户进行单独调整Meta旗下GenAI团队推出个性化图像生成模型Imagine yourself,与传统的基于调整的个性化技术不同,Imagine yourself作为一个无需调整的模型运行,使得所有用户都能利用共享...新技术# Imagine yourself# Meta2年前04440
人像视频编辑方法PortraitGen:可以根据多模态提示对人像视频进行一致且富有表现力的编辑中国科学技术大学的研究人员推出人像视频编辑方法PortraitGen,该方法可以根据多模态提示对人像视频进行一致且富有表现力的编辑。例如,给定一段人物跳舞的视频,PortraitGen 可以根据文字提...新技术# PortraitGen# 人像视频编辑2年前04050
新型视频生成技术Dr. Mo:提高视频生成的效率,同时保持或提升视频质量新型视频生成技术Dr. Mo(Diffusion Reuse MOtion),这项技术的核心在于提高视频生成的效率,同时保持或提升视频质量。研究团队的关键发现是,在早期去噪步骤中的粗粒度噪声在连续视频...新技术# Dr. Mo# 视频生成2年前04520
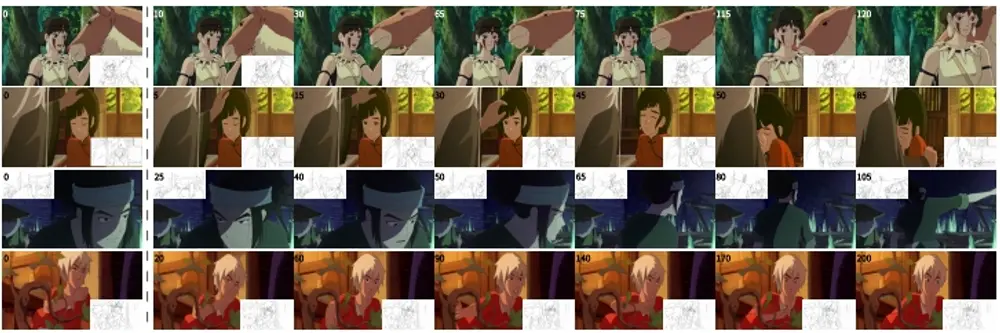
基于参考的线条艺术视频上色的视频扩散框架LVCD:用于根据参考图像和线稿序列为动画视频着色香港城市大学和腾讯的研究人员推出基于参考的线条艺术视频上色的视频扩散框架LVCD,用于根据参考图像和线稿序列为动画视频着色。这种方法能够生成长时间一致的、高质量的动画视频。LVCD在保持长时间一致性和...新技术# LVCD# 视频上色2年前04660
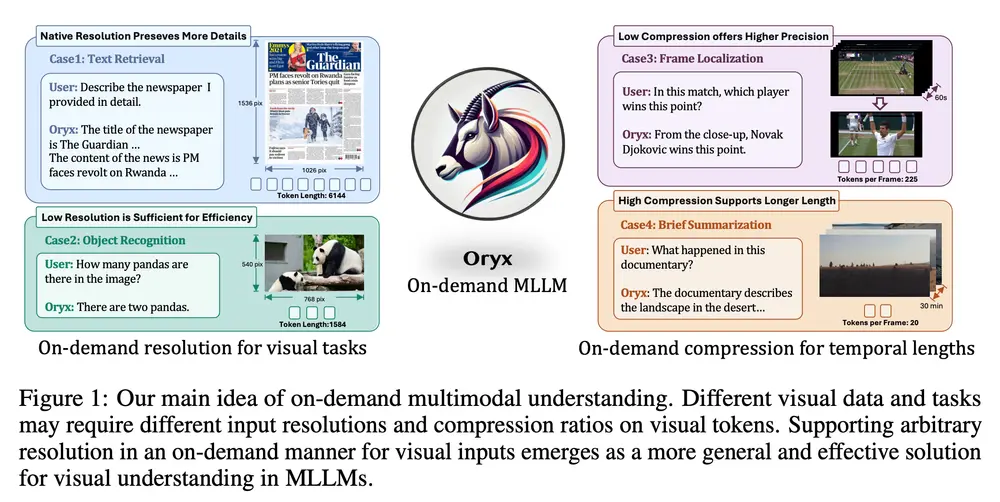
多模态大语言模型Oryx:专门设计用于理解和处理视觉数据,如图像、视频和3D场景清华大学、腾讯和南洋理工大学 S-Lab的研究人员推出多模态大语言模型Oryx,它专门设计用于理解和处理视觉数据,如图像、视频和3D场景。Oryx模型的特点是能够根据需要处理任意空间大小和时间长度的视...新技术# Oryx# 多模态大语言模型2年前06350
新型图像到视频生成技术OSV:可以将单张图像仅仅一步内生成高质量视频复旦大学、香港科技大学、香港中文大学和腾讯优图实验室的研究人员推出新型图像到视频生成技术OSV,可以将单张图像转换成视频。这项技术的目标是能够快速生成高质量的视频内容,而不需要复杂的多步骤处理。例如...新技术# OSV2年前04450
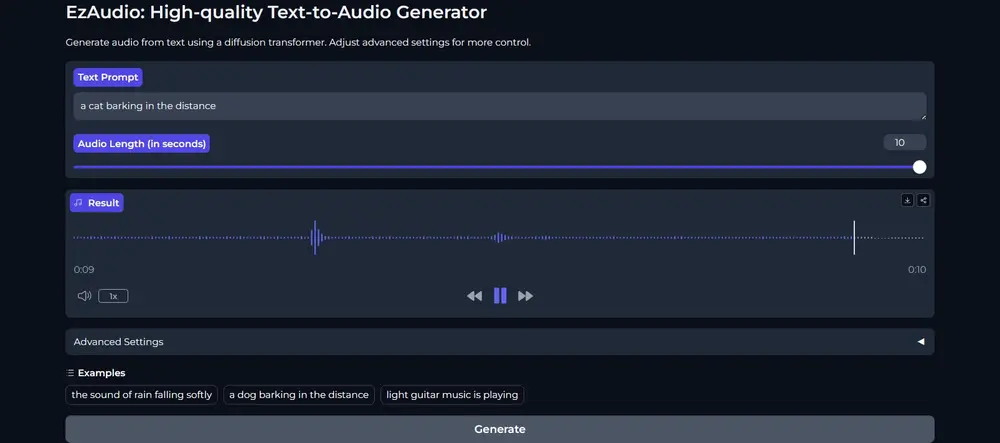
新型高品质文本音频生成器EzAudio:将文本描述转换成相应的音频内容约翰·霍普金斯大学和腾讯人工智能实验室的研究人员推出一种新型的文本到音频(Text-to-Audio,简称T2A)生成技术EzAudio,这项技术的目标是将文本描述转换成相应的音频内容,比如将“一只狗...新技术# EzAudio# 文本音频生成器2年前06320
diffusion-e2e-ft:通过微调图像条件扩散模型来简化和提高单目深度估计的效率亚琛工业大学和埃因霍温理工大学的研究人员推出diffusion-e2e-ft,通过微调图像条件扩散模型来简化和提高单目深度估计的效率。单目深度估计是指仅使用一张图片来预测场景中每个像素的深度信息。这项...新技术# diffusion-e2e-ft# 单目深度估计2年前06130