无需额外训练的缓存策略TeaCache:加速视频扩散模型的推理过程,同时保持生成视频的视觉质量扩散模型(DMs)作为视频生成的基本骨干,因其顺序去噪的性质而面临低推理速度的挑战。尽管先前的方法通过在均匀选择的时间步长上缓存和重用模型输出来加速模型,但这种策略忽略了模型输出在不同时间步长上的差异...新技术# TeaCache# 缓存策略1年前06620
新型知识蒸馏方法DisBack:加速扩散模型的生成模型的采样速度浙江大学、北京大学和阿里巴巴的研究人员推出新型知识蒸馏方法DisBack,它用于加速一类称为扩散模型(diffusion models)的生成模型的采样速度。扩散模型是当前非常热门的生成模型,能够生成...新技术# DisBack# 蒸馏方法2年前06620
新型视觉模型EfficientViT:专门用于高分辨率的密集预测任务来自MIT、浙江大学、清华大学、MIT-IBM Watson AI实验室的研究人员推出新型视觉模型EfficientViT,它专门用于高分辨率的密集预测任务。这类任务在计算机视觉领域非常重要,应用范围...新技术# EfficientViT# 视觉模型2年前06610
基于优化框架的跨模态视频-音频生成方法Seeing and Hearing:能够同时生成视频和音频内容香港科技大学和腾讯 PCG ARC 实验室推出基于优化框架的跨模态视频-音频生成方法Seeing and Hearing,它能够同时生成视频和音频内容。方法的主要创新点在于,通过预训练的多模态模型(如...新技术# Seeing and Hearing# 优化框架# 跨模态视频-音频生成方法2年前06590
基于身份条件的人脸基础模型Arc2Face:能够根据一个人的面部特征生成高质量的、逼真的图像来自英国伦敦帝国理工学院的研究人员推出基于身份条件的人脸基础模型Arc2Face,能够根据一个人的面部特征生成高质量的、逼真的图像。 项目主页 GitHub Demo 模型 想象一下,如果你有一张朋友...新技术# Arc2Face2年前06580
新型图像生成技术StrokeNUWA:利用大语言模型生成矢量图形StrokeNUWA是一种新型图像生成技术,用于仅通过大语言模型(LLM)生成矢量图形,无需依赖专门的视觉模块。 论文 该方法的关键创新在于利用矢量图形固有的视觉语义,将矢量图形编码为"笔画"标记,这...新技术# LLM# StrokeNUWA# 大语言模型2年前06580
多模态大语言模型Groma:具备精细化和定位化的视觉感知能力来自香港大学和字节跳动的研究人员推出多模态大语言模型Groma,它具备精细化和定位化的视觉感知能力。Groma不仅能够理解整个图像的内容,还能处理区域级别的任务,比如区域字幕(region capti...新技术# Groma# 多模态大语言模型2年前06560
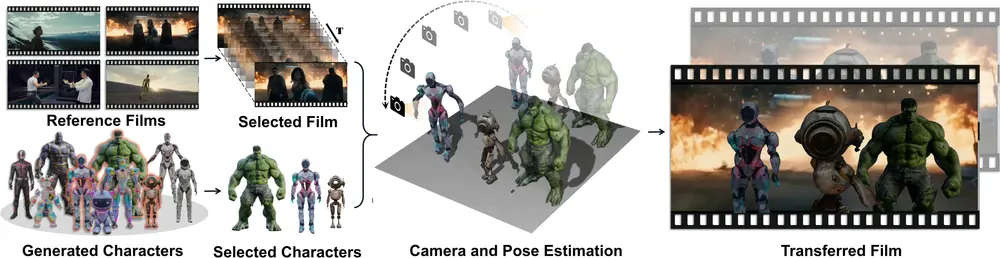
创新电影制作框架DreamCinema:利用AI技术简化了电影创作过程,使得个人也能轻松成为电影制作人清华大学推出创新电影制作框架DreamCinema,它利用AI技术简化了电影创作过程,使得个人也能轻松成为电影制作人。在这个数字化媒体蓬勃发展的时代,人们对于创造个性化、高质量的电影级视频有着广泛需求...新技术# DreamCinema# 电影2年前06540
新型文本到图像生成框架InstantStyle:在生成图像时保持一致的风格InstantX团队推出新型文本到图像生成框架InstantStyle,它专注于在生成图像时保持一致的风格。它通过简化风格迁移的过程,使得普通用户和专业人士都能够轻松地创造具有一致风格的图像。 项目主...新技术# InstantStyle# 风格2年前06540
多内容数据集ImagiNet:为了提高合成图像检测的泛化能力而设计保加利亚大特尔诺沃自然科学与数学高中、索非亚大学、保加利亚普罗夫迪夫数学高中和斯坦福大学的研究人员推出多内容数据集ImagiNet,它是为了提高合成图像检测的泛化能力而设计的。合成图像是由计算机生成的...新技术# ImagiNet# 数据集2年前06530
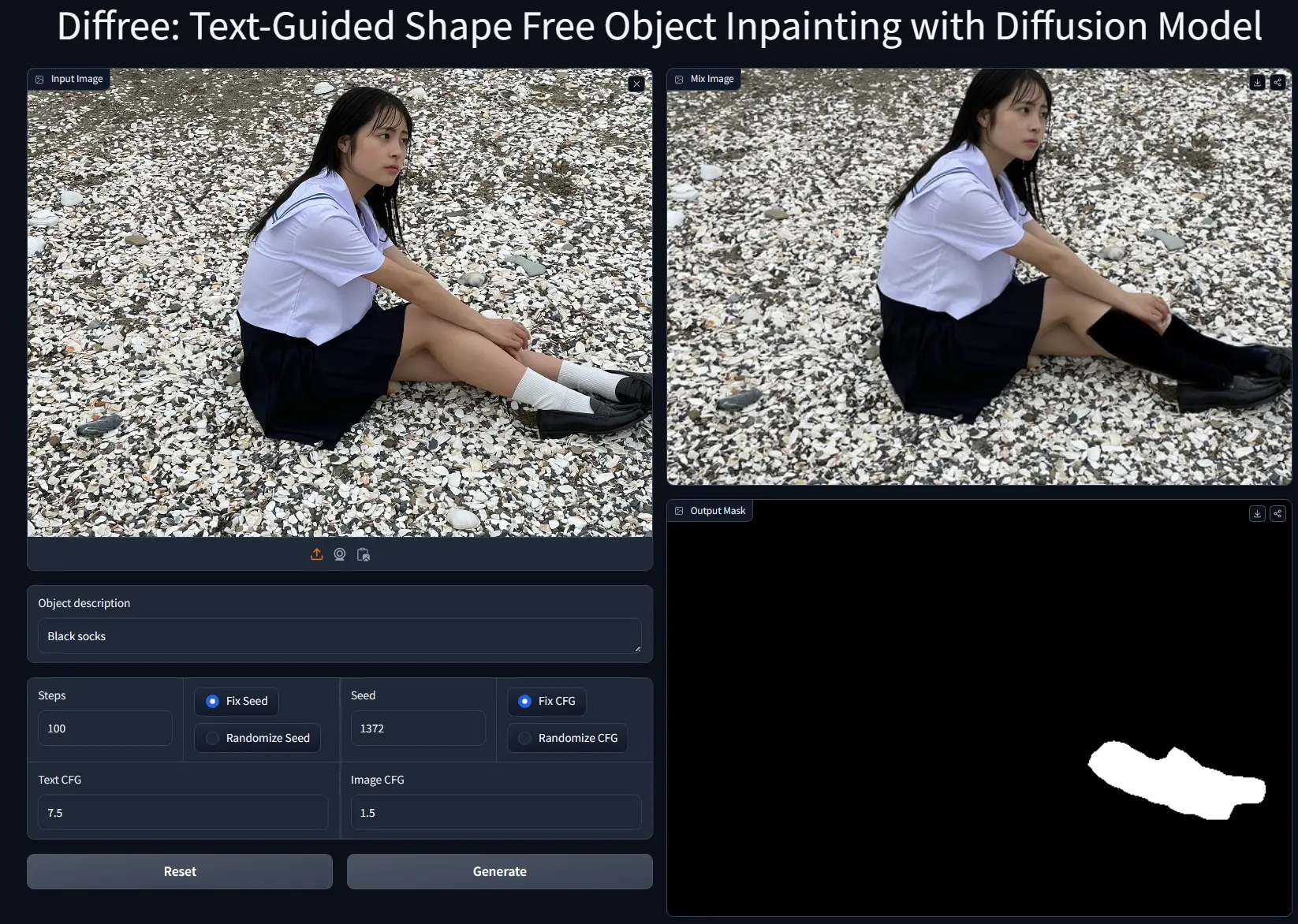
新型图像处理技术Diffree:根据文本提示,在图像中添加新的对象厦门大学多媒体可信感知与高效计算教育部重点实验室、上海人工智能实验室OpenGVLab和香港大学推出新型图像处理技术Diffree,它能够根据文本提示,在图像中添加新的对象。这项技术就像是给照片“填空...新技术# Diffree# 图像处理2年前06520
神经网络架构MVDiffusion++:用于从单个或少量图像中重建3D物体来自西蒙弗雷泽大学和Meta Reality Labs的研究人员推出神经网络架构MVDiffusion++,它用于从单个或少量图像中重建3D物体。这个模型能够在没有相机姿态信息的情况下,生成密集且高分...新技术# 3D# MVDiffusion++# 神经网络架构2年前06520