创建人物图像动画的新方法Champ:让静态人物图片动起来来自南京大学、复旦大学和阿里巴巴的研究团队推出一种用于创建人物图像动画的新方法Champ,该方法利用潜在扩散框架内的3D人体参数模型来强化当前人体生成技术中的形状对齐和运动引导。例如,你有一张静态的照...新技术# Champ# 图像动画2年前06770
AutoVFX:基于自然语言指令的自动视觉效果生成现代视觉效果(VFX)软件使熟练的艺术家能够创造出几乎任何图像,但创作过程仍然费力、复杂,并且对普通用户来说基本上是不可访问的。为了简化这一过程,伊利诺伊大学厄巴纳-香槟分校的研究人员提出了AutoV...新技术# AutoVFX1年前06760
新型生成模型DisCo-Diff:用于增强连续扩散模型的性能英伟达和麻省理工学院的研究人员推出新型生成模型DisCo-Diff,它用于增强连续扩散模型(Diffusion Models, DMs)的性能。扩散模型是一种强大的数据生成方法,但它们通常需要将复杂的...新技术# DisCo-Diff# 生成模型2年前06760
新型多模态DiT模型AV-DiT:生成既有视觉画面又有声音的高质量视频来自多伦多大学、德克萨斯大学达拉斯分校和Adobe研究中心的研究人员推出新型多模态扩散变换器AV-DiT(Audio-Visual Diffusion Transformer),它专门设计用于联合生成...新技术# AV-DiT# DiT模型2年前06760
新型图像生成模型家族LlamaGen:将大语言模型(Llama)应用到视觉图像生成领域香港大学及字节跳动的研究人员推出新型图像生成模型家族LlamaGen,将大语言模型(Llama)中原用于文本生成的“下一个令牌预测”范式应用到了视觉图像生成领域。LlamaGen是对传统自回归模型在图...新技术# LlamaGen# 图像生成# 大语言模型2年前06760
图像分割技术OpenTrans:提高开放词汇表分割(OVS)的效率来自北京交通大学和西蒙菲莎大学的研究人员推出OpenTrans,它旨在提高开放词汇表分割(Open-Vocabulary Segmentation, OVS)的效率。OVS是一种图像分割技术,能够识别...新技术# OpenTrans# 图像分割技术2年前06740
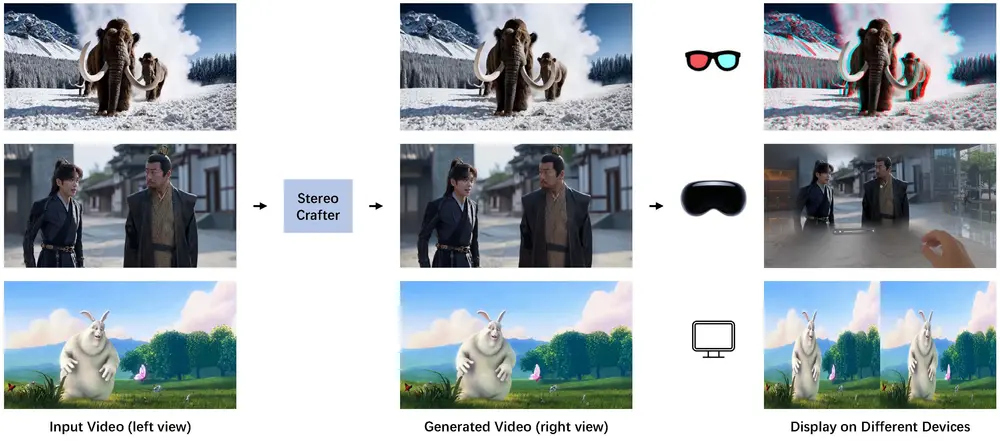
StereoCrafter框架:用于将单目(2D)视频转换为沉浸式立体 3D 视频,以满足人们对沉浸式数字体验的需求腾讯AI实验室和腾讯PCG ARC Lab的研究人员推出StereoCrafter框架,用于将单目视频转换为沉浸式立体 3D 视频,以满足人们对沉浸式数字体验的需求。该框架主要解决了传统 2D-to...新技术# StereoCrafter1年前06730
FoleyCrafter:用于将无声视频通过自动生成高质量、与视频同步的声音效果,从而带来沉浸式的视听体验上海人工智能实验室he 香港中文大学(深圳)的研究人员推出FoleyCrafter系统,它专门用于将无声视频通过自动生成高质量、与视频同步的声音效果,从而带来沉浸式的视听体验。这项技术在电影、电视和游...新技术# FoleyCrafter2年前06730
Video2Game:自动将现实世界的视频转化为真实且具备交互性的游戏环境来自伊利诺伊大学厄巴纳-香槟分校、上海交通大学和康奈尔大学的研究人员推出Video2Game,它可以将任何真实世界的视频转换成一个实时、互动、真实感强且与浏览器兼容的游戏环境。例如,你有一段拍摄街道的...新技术# Video2Game# 游戏2年前06730
视觉风格提示(Visual Style Prompting):不需要对模型进行微调的情况下,通过参考图像来生成具有特定风格的图像来自韩国延世大学和NAVER AI 实验室的研究团队推出“视觉风格提示(Visual Style Prompting)”,它能够在不需要对预训练模型进行微调的情况下,通过参考图像来生成具有特定风格的图...新技术# Visual Style Prompting# 视觉风格提示2年前06730
Follow-Your-Click:通过用户简单的点击和简短的动作提示来实现图像的局部动画化来自香港科大、腾讯浑源和清华大学的团队推出新颖框架Follow-Your-Click,它能够通过用户简单的点击和简短的动作提示来实现图像的局部动画化。 项目主页 GitHub 想象一下,你有一张静态图...新技术# Follow-Your-Click# 局部动画化2年前06710
新型框架Lightplane:用于处理3D神经场的高度可扩展的组件密歇根大学和Meta的研究人员推出新型框架Lightplane,它包含两个高度可扩展的组件:Lightplane Renderer和Lightplane Splatter。这两个组件专门用于处理3D神...新技术# 3D场景模型# Lightplane# Lightplane Renderer2年前06700