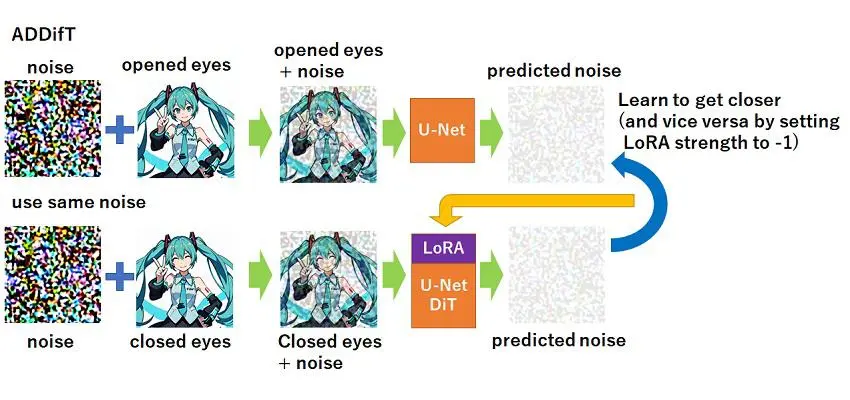
全新LoRA训练方法ADDifT(交替直接差分训练)背景与动机 LoRA(低秩适应)是一种参数高效的微调技术,广泛用于大语言模型和扩散模型(如Stable Diffusion)的定制化训练。然而,传统LoRA训练方法存在效率低和易学到无关特征(如背景或...新技术# ADDifT# Lora# LoRA模型1年前05990
西湖大学推出一款具备自我进化能力的 GUI 代理AppAgentX西湖大学 AGI 实验室张驰团队近日推出一款具备自我进化能力的 GUI 代理——AppAgentX,它能够在持续执行任务的过程中不断学习并优化自身行为模式,从而实现更高效的操作,为自动化任务执行带来了...新技术# AI智能体# AppAgentX# GUI 代理1年前03420
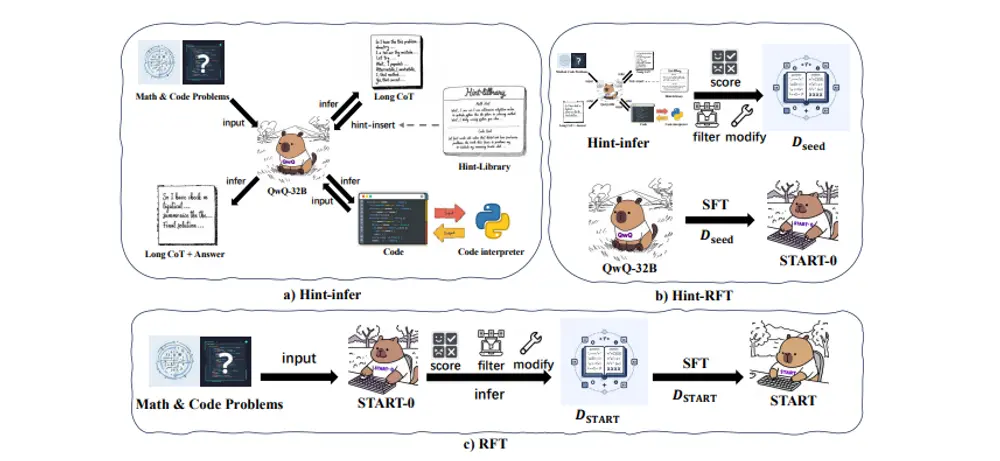
阿里巴巴提出START:显著提升大语言模型推理能力的创新工具在大语言模型的发展中,尽管在理解和生成类人文本方面取得了显著进展,但在处理复杂推理任务时,尤其是需要多步计算或逻辑分析的任务,这些模型往往表现不佳。传统的思维链(Chain of Thought, C...新技术# START# 大语言模型# 推理1年前02310
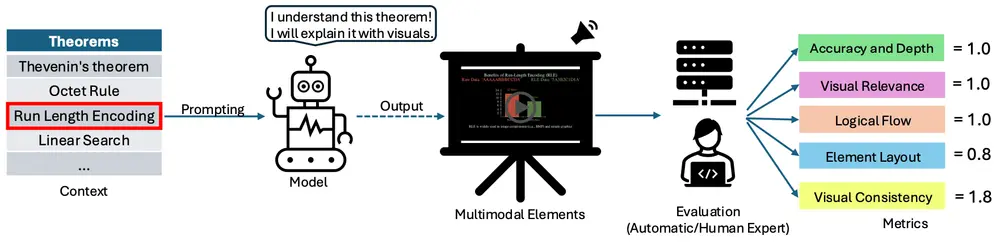
TheoremExplainAgent:用于生成长篇幅的定理解释视频(超过5分钟),并使用 Manim 动画工具实现可视化滑铁卢大学和Vector 研究所的研究人员推出代理系统TheoremExplainAgent,用于生成长篇幅的定理解释视频(超过5分钟),并使用 Manim 动画工具实现可视化。 项目主页:https...新技术# Manim 动画# TheoremExplainAgent# 定理解释视频1年前02420
多粒度视频编辑框架VideoGrain:通过自然语言提示实现对视频内容的精细编辑悉尼科技大学和浙江大学的研究人员推出多粒度视频编辑框架VideoGrain,通过自然语言提示实现对视频内容的精细编辑。多粒度视频编辑包括类别级(class-level)、实例级(instance-le...新技术# VideoGrain# 视频编辑1年前03020
深圳大学推出Attention Distillation:用于将参考图像的视觉特征(如风格、纹理、外观)转移到生成的图像中深圳大学的研究团队介绍了一种名为 Attention Distillation (AD) 的方法,用于将参考图像的视觉特征(如风格、纹理、外观)转移到生成的图像中。该方法通过计算预训练扩散模型中的自注...新技术# Attention Distillation# 参考图像# 深圳大学1年前06150
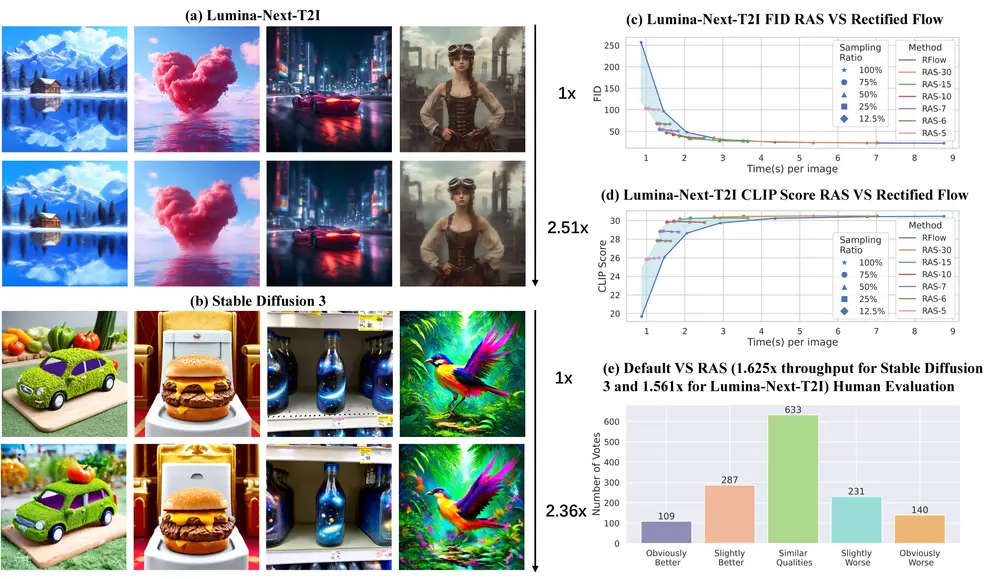
微软研究院推出新型采样策略RAS:用于加速DiT架构模型的生成过程新加坡国立大学和微软研究院的研究团队提出了一种全新的扩散采样策略——区域自适应采样 (Region-Adaptive Sampling, RAS)。这是首个允许采样率在图像不同区域间动态变化的扩散采样...新技术# RAS# 区域自适应采样# 微软研究院1年前05030
高效稀疏注意力机制 SpargeAttn:加速大模型的推理过程,同时不损失模型性能清华大学和加州大学伯克利分校的研究人员推出高效稀疏注意力机制 SpargeAttn,旨在加速大模型的推理过程,同时不损失模型性能。注意力机制在现代深度学习模型中扮演着重要角色,但由于其计算复杂度与序列...新技术# SpargeAttn# 加州大学伯克利分校# 清华大学1年前05920
DeepSeek开源周第五弹:高性能分布式文件系统 3FS和Smallpond 数据处理框架在开源周的第五天,DeepSeek 正式发布了 3FS(Fire-Flyer File System)。这是一个专为现代 SSD 和 RDMA 网络设计的并行文件系统,旨在为深度学习等数据密集型应用提...新技术# 3FS# DeepSeek# Smallpond1年前02630
Hugging Face 发布开源Python库FastRTC,简化实时 AI 语音和视频应用AI 初创公司 Hugging Face 近日推出了一款名为 FastRTC 的开源 Python 库,旨在简化开发者构建实时音频和视频 AI 应用的复杂性。这一创新工具的发布,标志着实时 AI 应用...新技术# AI 语音# FastRTC# Python 库1年前02120
DeepSeek 开源周第四弹:DualPipe 和 EPLB 的发布今天是 DeepSeek 开源周的第四天。与前三天相比,今天的开源项目公布稍晚一些,让关注者们等待得略显焦急,不过等待的结果总是值得的!DeepSeek 今日公布了两项重要的开源内容:DualPipe...新技术# DeepSeek# DualPipe# EPLB1年前02290
深度求索开源第三弹DeepGEMM:专为高效 FP8 矩阵乘法设计的库在开源周的第三天,DeepSeek 推出了一个名为 DeepGEMM 的新库,专为高效、简洁的 FP8 通用矩阵乘法(GEMM)而设计。这一工具旨在解决现代 AI 计算中矩阵乘法的效率和精度问题,特别...新技术# DeepGEMM# DeepSeek# 深度求索1年前02970