SliderSpace:自动分解文生图模型的视觉能力,将其转化为简单的滑块控件,使用户能够更直观地控制生成结果扩散模型(Diffusion Models)在生成高质量图像方面表现出色,但其生成过程的黑箱性质限制了用户的控制能力。为了增强扩散模型的可控性和可解释性,来自美国东北大学和 Adobe Researc...图像模型# Adobe Research# SliderSpace# 东北大学1年前05700
文字处理能力出众!Playground推出最新文生图模型Playground v3Playground 推出了Playground v3(PGv3),这是Playground最新的文本到图像模型,在多个测试基准上达到了最先进的(SoTA)性能,在图形设计能力上表现出色,并引入了新的...图像模型# Playground v3# 文生图模型1年前04580
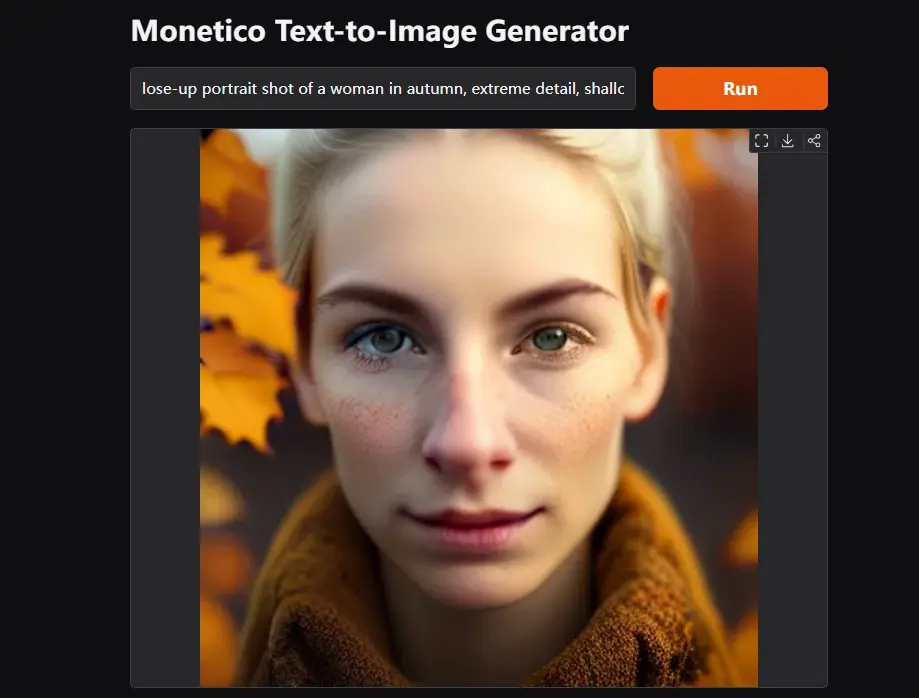
Collov Labs推出非自回归掩码图像建模的文本到图像合成模型MoneticoCollov Labs 最近在8块H100 GPU上训练了一周时间,推出了新的非自回归掩码图像建模的文本到图像合成模型——Monetico。这款模型能够生成高分辨率图像,并且被设计为在消费级显卡上高效...图像模型# Monetico# 文生图模型1年前04840
SWITTI:用于文本到图像合成的新型规模感知变换器模型Yandex Research、HSE 大学、MIPT 和 Skoltech 的研究人员提出了 Switti,这是一个专门设计用于文本到图像(T2I)生成的尺度变换器。Switti 从现有的下一尺度预...图像模型# SWITTI# 文生图模型1年前03140
新型文生图框架Ranni:利于大语言模型,更准确地理解和执行复杂的文本提示阿里巴巴和蚂蚁集团推出新型文生图框架Ranni,Ranni的核心特点是它能够更准确地理解和执行复杂的文本提示,尤其是那些包含数量描述、对象属性绑定和多主题描述的提示。这使得Ranni在生成图像时能够更...图像模型# Ranni# 文生图模型1年前08810
新型图像生成模型MoMA:具有灵活的零样本能力,专注于主体驱动的个性化图像生成来自字节跳动和罗格斯大学的研究人员推出新型图像生成模型MoMA(Multimodal LLM Adapter),这是一个开放词汇、无需训练的个性化图像模型,具有灵活的零样本能力,专注于主体驱动的个性化...图像模型# MoMA# 个性化图像生成# 文生图模型1年前09510
新型文生图模型YaART:利用人类反馈的强化学习与人类偏好进行对齐来自俄罗斯Yandex、斯科尔科沃科学技术学院、莫斯科国立大学和高等经济学院的研究团队推出新型的、适用于生产环境的文本到图像级联扩散模型YaART(Yet Another Art Rendering ...图像模型# YaART# 文生图模型1年前05810
新型框架Diffusion-KTO:用于调整文生图模型,使其生成的图像更符合人类的偏好加州大学洛杉矶分校、松下人工智能研究中心和 Salesforce 人工智能研究中心的研究人员推出新型框架Diffusion-KTO,它专门用于调整文生图模型,使其生成的图像更符合人类的偏好。这个过程不...图像模型# Diffusion-KTO# 文生图模型1年前06580
文生图模型新架构MoA:根据用户的个性化需求生成包含特定人物的图像,同时保持原有模型的风格和多样性Snap推出新架构注意力混合(Mixture-of-Attention,简称MoA),即在个性化图像生成中实现主体与上下文解耦的注意力混合模型(MoA),用于个性化文本到图像的扩散模型。简单来说,Mo...图像模型# MoA# 文生图模型1年前09950
新型文生图模型CoMat:更好地理解和执行文本描述,提高了文本到图像生成的质量和准确性来自香港中文大学、商汤科技和上海人工智能实验室的研究人员推出新型文生图模型CoMat,这是一种具有图像到文本概念匹配机制的端到端扩散模型微调策略。开发团队借助图像字幕模型来评估图像与文本的对齐程度,并...图像模型# CoMat# 文生图模型1年前01,1470
CosmicMan:专注于生成高保真人类图像的文生图基础模型上海人工智能实验室推出CosmicMan,这是一款专注于生成高保真人类图像的文本到图像基础模型。CosmicMan能够生成外观精细、结构合理,并且与详细描述精确对齐的逼真人类图像。 项目主页:http...图像模型# CosmicMan# 文生图模型1年前01,1010
华为PixArt系列最新模型—PIXART-Σ:基于DiT,可直接生成4K分辨率的图像来自华为诺亚方舟实验室、大连理工大学、香港大学的研究人员推出了最新的PixArt模型—PIXART-Σ,PixArt-Σ基于Diffusion Transformer架构 (DiT,与Sora、Sta...图像模型# DiT# PIXART-Σ# 文生图模型1年前01,0400