

Controlnet作者lllyasviel新开源项目Omost:将大语言模型的编程能力转化为图像合成能力
Controlnet作者lllyasviel的新开源项目Omost,这是一个将大语言模型的编程能力转化...

Jasper推出新型蒸馏方法Flash Diffusion:高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型图像生成
Jasper推出了一种高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型生成的...




人像视频生成框架V-Express:平衡不同控制信号(如文本、音频、参考图像、姿态、深度图等)的强弱,以便在生成视频中实现更协调和有效的控制
南京大学和腾讯人工智能实验室的研究人员推出人像视频生成框架V-Express,它用于生...

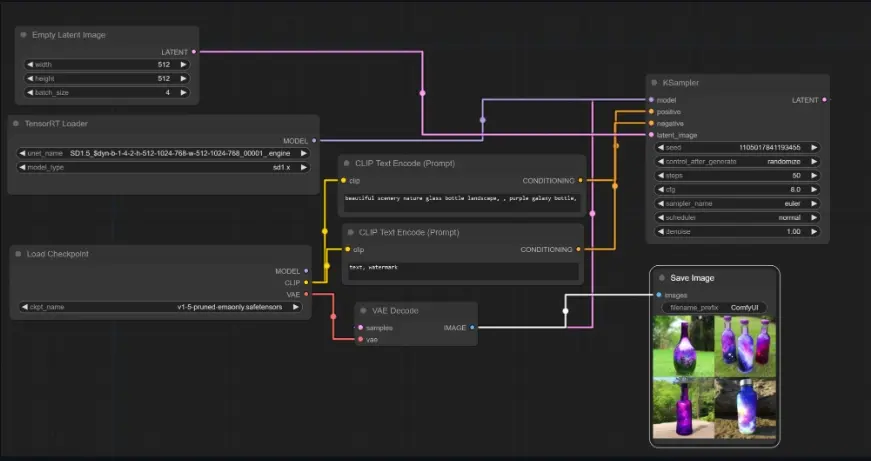
TensorRT Node for ComfyUI:TensorRT插件正式上架ComfyUI,加速图像生成
之前英伟达已经在Stable Diffusion web UI上推出了TensorRT插件,近日又联合ComfyU...



视频插帧新技术ZeroSmooth:提升预训练视频扩散模型生成高帧率视频的能力,而无需额外的训练数据和参数更新
中国科学院大学人工智能学院、中国科学院自动化研究所模式识别新实验室和腾讯AI实...

先进的视频深度估计方法ChronoDepth:通过结合视频生成模型的先验知识,有效地提高了深度估计的准确性和时间一致性
浙江大学、博洛尼亚大学、蚂蚁集团和Rock Universe的研究人员推出一种先进的视频深...