
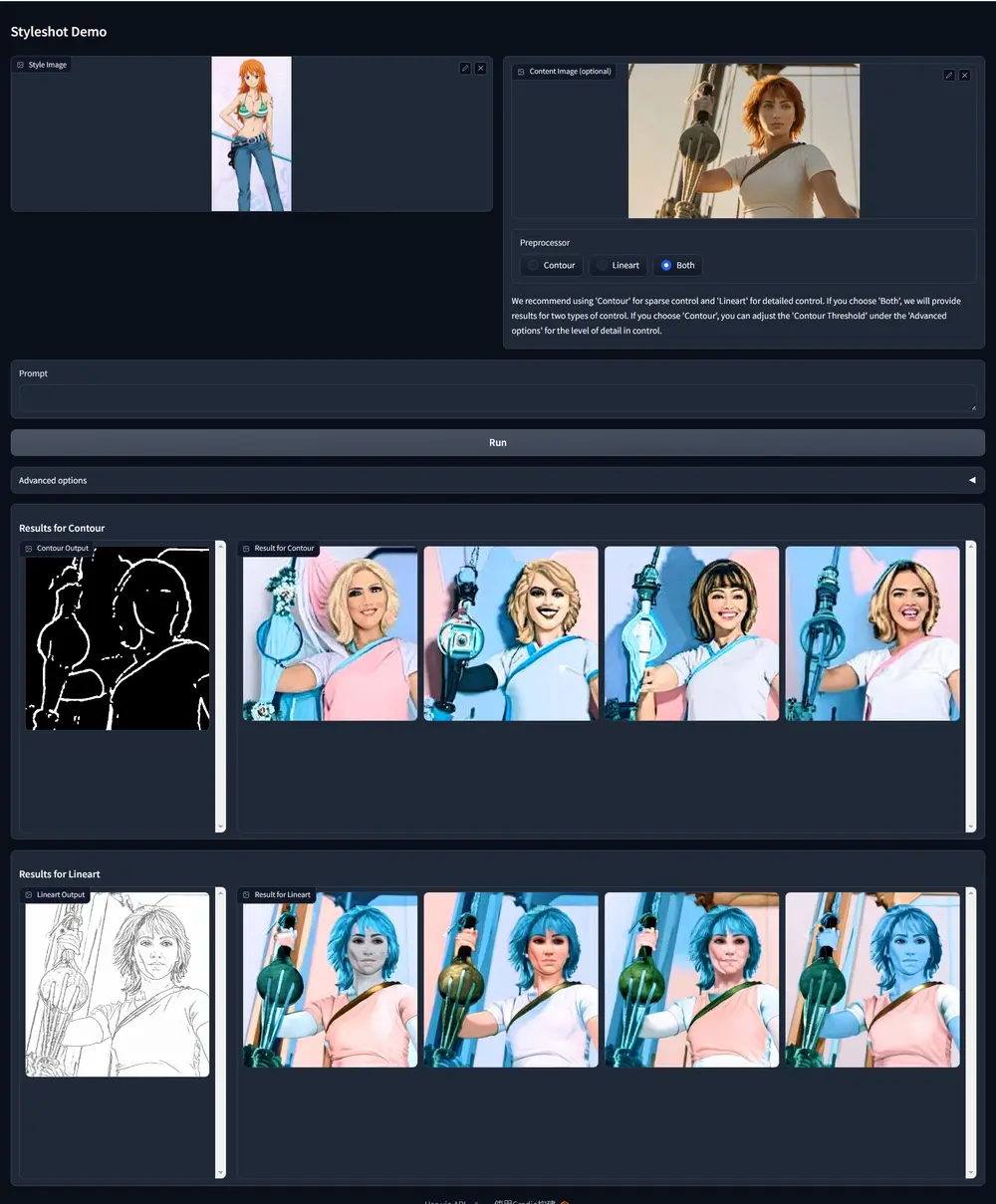



参照音频-视觉分割RefAVS:依据融合了多模态提示(包括音频和视觉描述)的自然语言表达,对视觉场景中的目标物进行分割
中国人民大学、北京邮电大学和上海人工智能实验室的研究人员推出RefAVS(参照音频-...

针对姿势引导的人像图像动画技术TCAN:让图片中的人物根据某个动作序列(比如一个视频)来做出相应的动作
韩国科学技术院和Naver的研究人员推出一种针对姿势引导的人像图像动画技术TCAN,该...

视频增强技术Noise Calibration(噪声校准):使用预训练的视频扩散模型来改善视频质量,同时确保原始视频的内容保持不变
大连理工大学和腾讯AI实验室的研究人员推出视频增强技术“Noise Calibration(噪声...

以Stable Cascade为基础!新型超高分辨率图像生成方法UltraPixel:生成从1K至6K多种分辨率的高品质图像
香港科技大学(广州)、 华为诺亚方舟实验室、马克斯普朗克信息研究所和香港科技...


