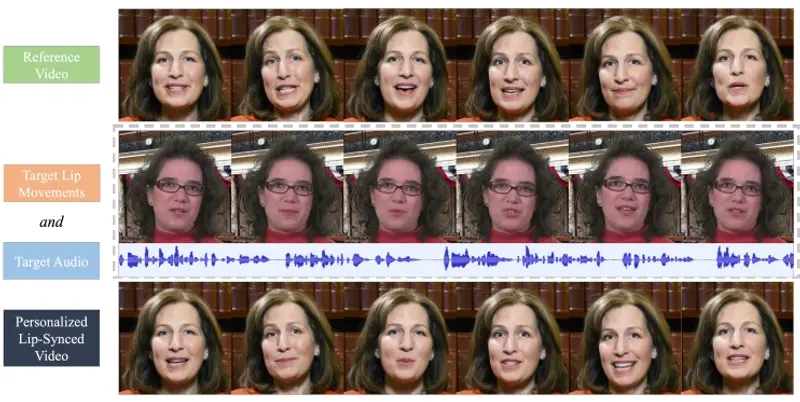
Claude新功能Computer Use的开源平替方案大合集
Anthropic在近期升级了Claude 3.5 Sonnet 和推出新模型 Claude 3.5 Haiku,不过最...
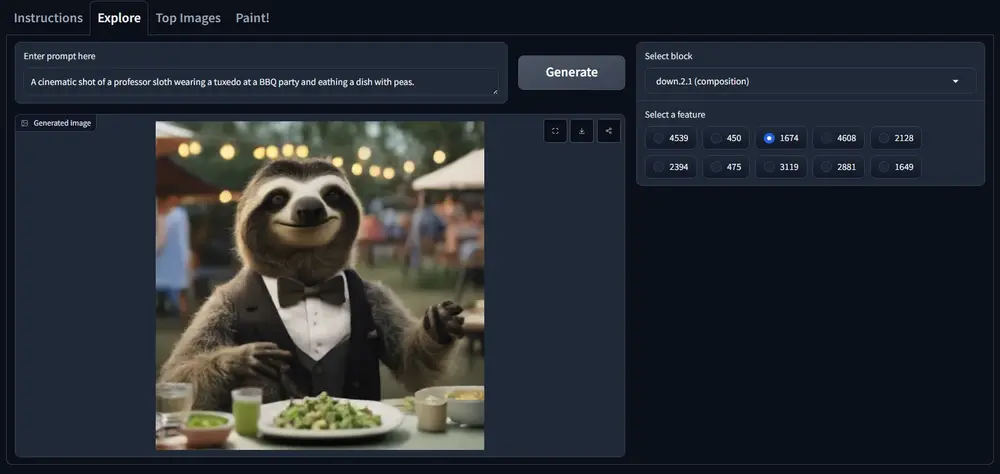
Unpacking SDXL Turbo: 使用稀疏自编码器来解释和理解文本到图像模型,特别是SDXL Turbo模型的内部工作机制
稀疏自编码器(SAEs)已成为逆向工程大语言模型(LLMs)的核心组成部分。SAEs通过...

高容量真实世界图像恢复模型DreamClear:结合隐私安全的数据处理流程(GenIR)和DiT技术,以实现对低质量图像的高质量恢复
现实世界中的图像恢复(IR)面临着显著的挑战,主要是缺乏高容量模型和全面的数据...

新型文本到图像生成技术GrounDiT:利用DiT实现了无需训练的空间定位能力,实现更精细的用户控制
韩国科学技术研究院推出新型文本到图像生成技术GrounDiT(GROUNDIT),它通过利用D...
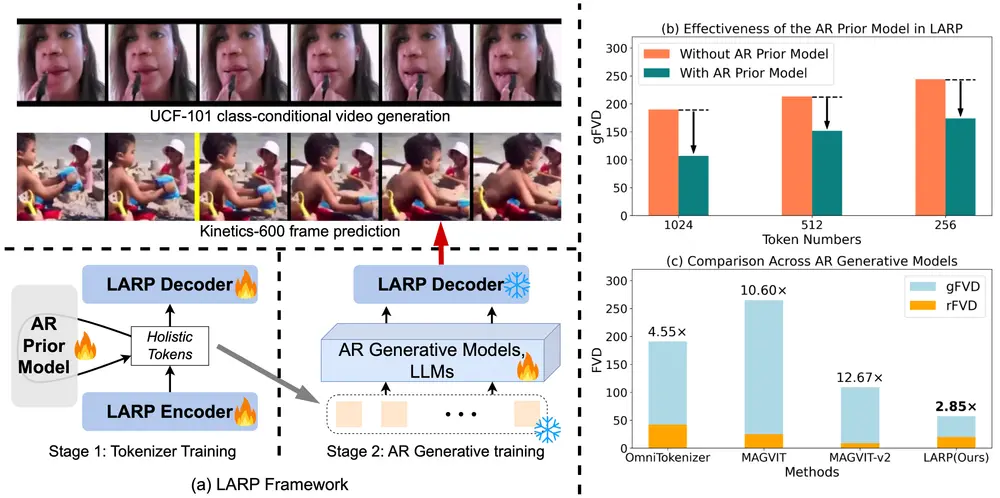
新型视频分词器LARP:专为自回归(AR)生成模型设计,用于提高视频生成任务的性能
马里兰大学学院公园分校的研究人员提出了一种名为LARP(Latent Aggregation and Re...

新型视频生成模型家族MarDini:通过将掩码自回归(MAR)技术与扩散模型(DM)相结合,开创了一种高效的视频生成方法
Meta AI与阿卜杜拉国王科技大学的研究人员推出了一种新型视频生成模型家族——MarDin...


用于长视频生成的双速学习系统SLOWFAST-VGEN:模仿了人类大脑中慢速学习和快速学习相结合的互补学习系统
人类拥有一个独特的学习系统,它既能从普遍的世界规律中缓慢学习,也能迅速地将新...

神秘图像生成模型“red_panda”揭晓,来自AI设计平台Recraft,官方正式版本为Recraft V3
之前给大家介绍了神秘图像生成模型“red_panda”,其在Artificial Analysis 图像模型...