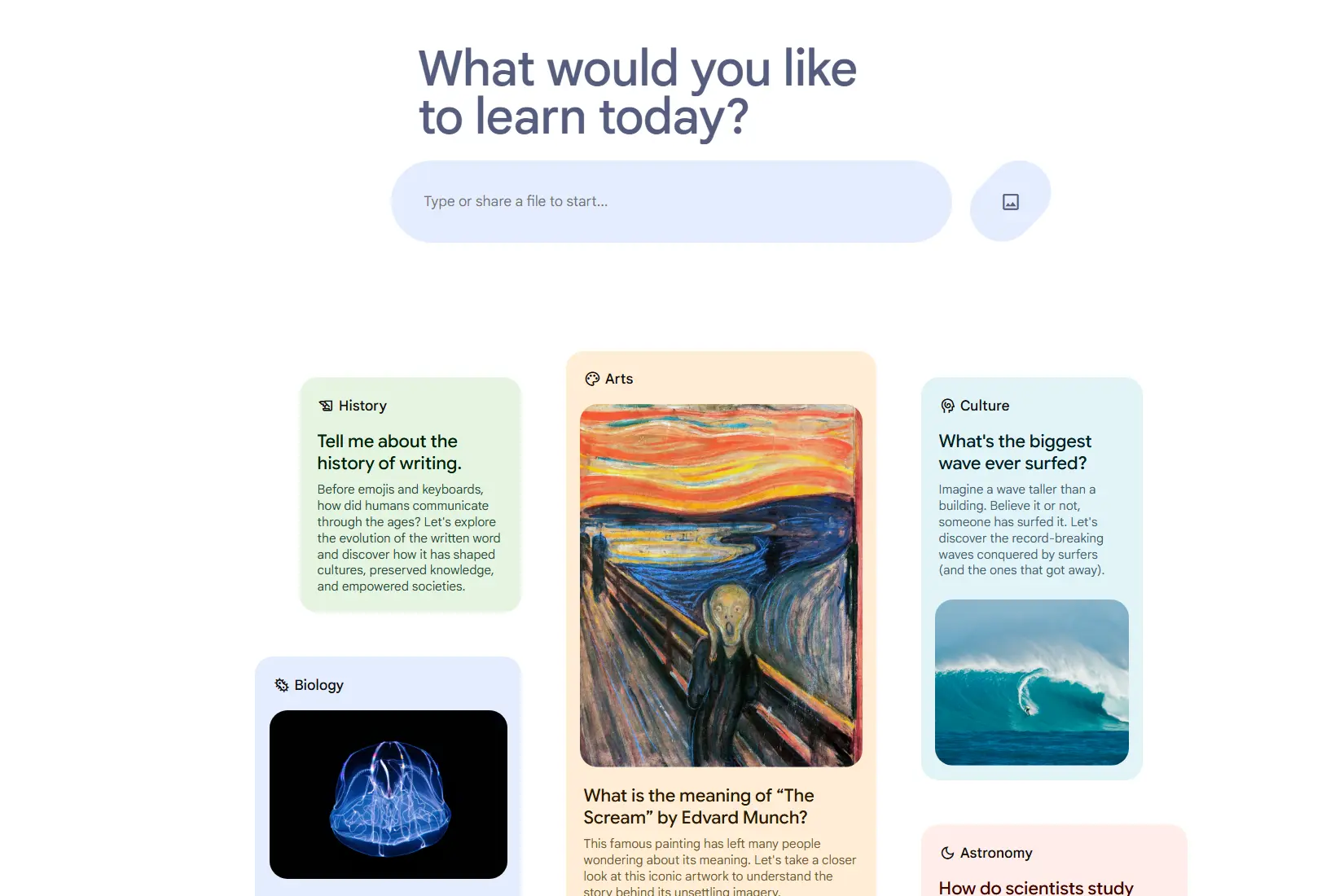
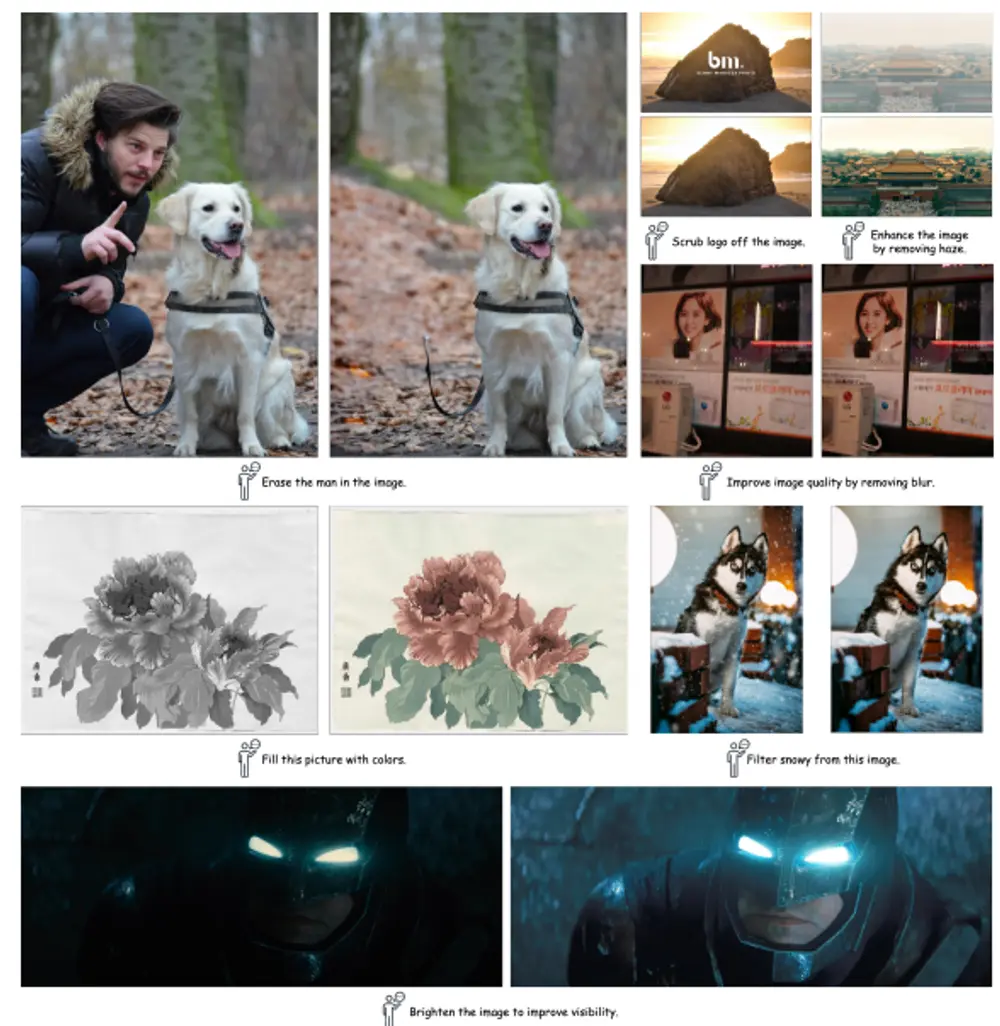
基于扩散模型的图像处理系统PromptFix:能够根据人类的指令执行各种图像处理任务,如上色、提升照片亮度、去除水印、抠图、去雾和去模糊等
扩散模型结合语言模型在图像生成任务中展现了卓越的可控性,能够根据人类指令进行...

阿里通义团队推出图像生成新型框架In-Context LoRA:利用现有的DiT架构模型(Flux模型)的上下文生成能力,通过提示词生成连贯图像
随着深度学习技术的发展,图像生成领域取得了显著进展。DiT架构作为一种新兴方法,...
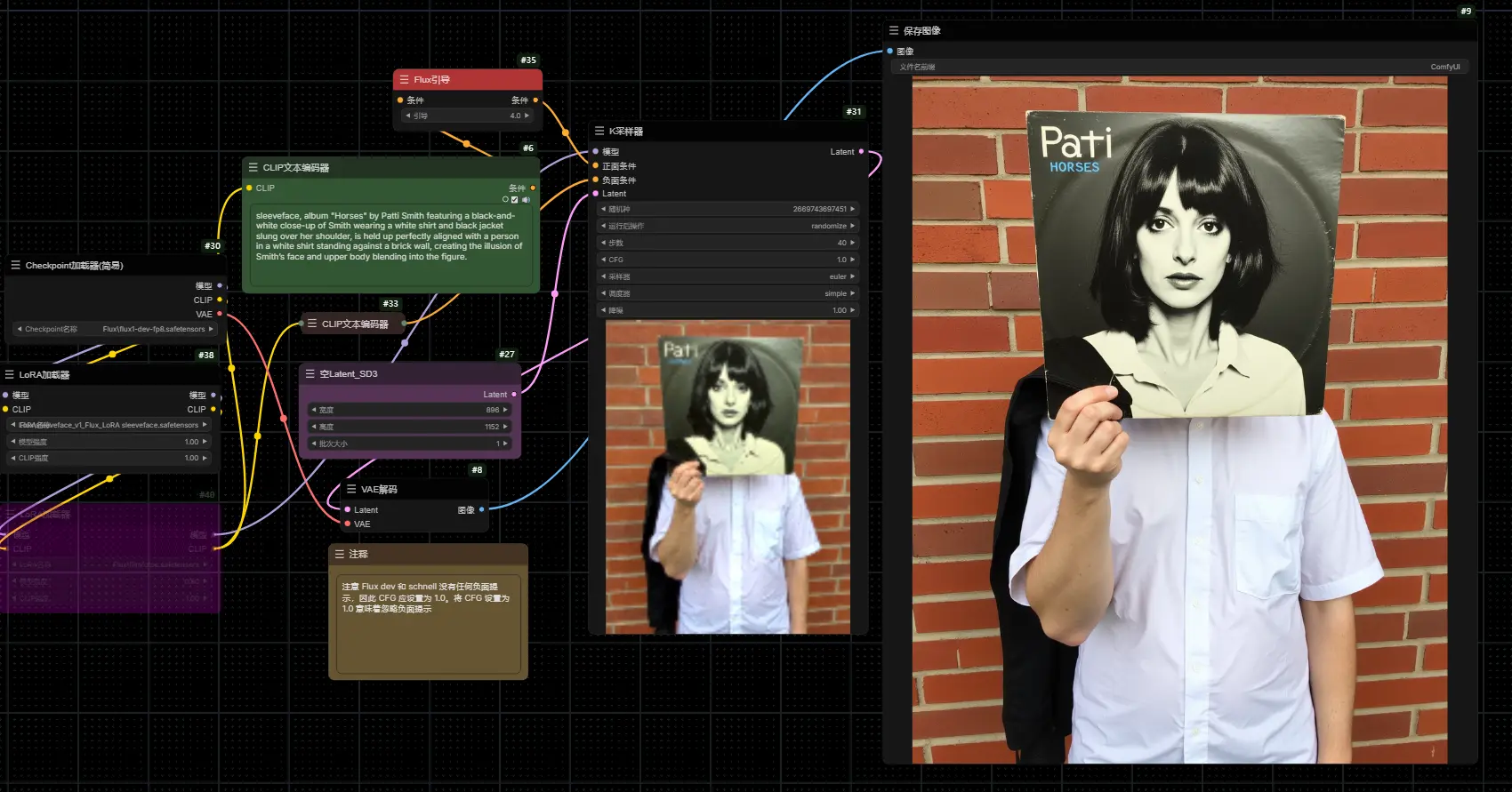
Sleeveface :基于 FLUX.1-dev 的风格LoRA,专门设计用来重现2000年代流行的“Sleeveface”风格
Sleeveface 是一款基于 FLUX.1-dev 的概念LoRA,专门设计用来重现2000年代流行的“S...
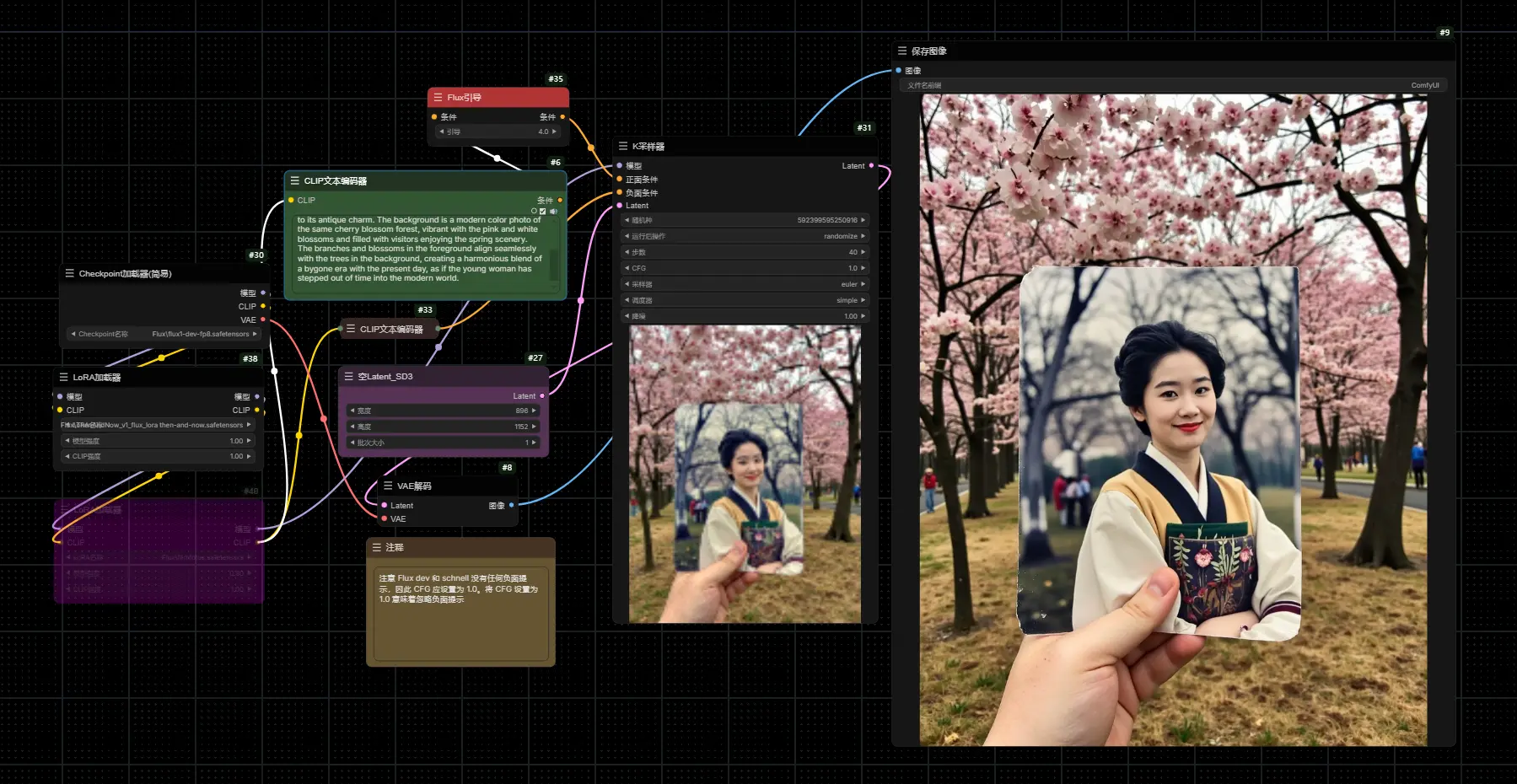
Then and Now:基于 FLUX.1-dev 的概念LoRA,创作“图中图”效果
Then and Now 是基于 FLUX.1-dev 的概念LoRA,旨在创作“图中图”效果,即在同一个位...

ComfyUI-Fluxtapoz:RF-Inversion的官方ComfyUI插件,对图片进行风格转换和编辑
RF-Inversion是德克萨斯大学奥斯汀分校和谷歌的研究人员提出的一种图像处理方法,...
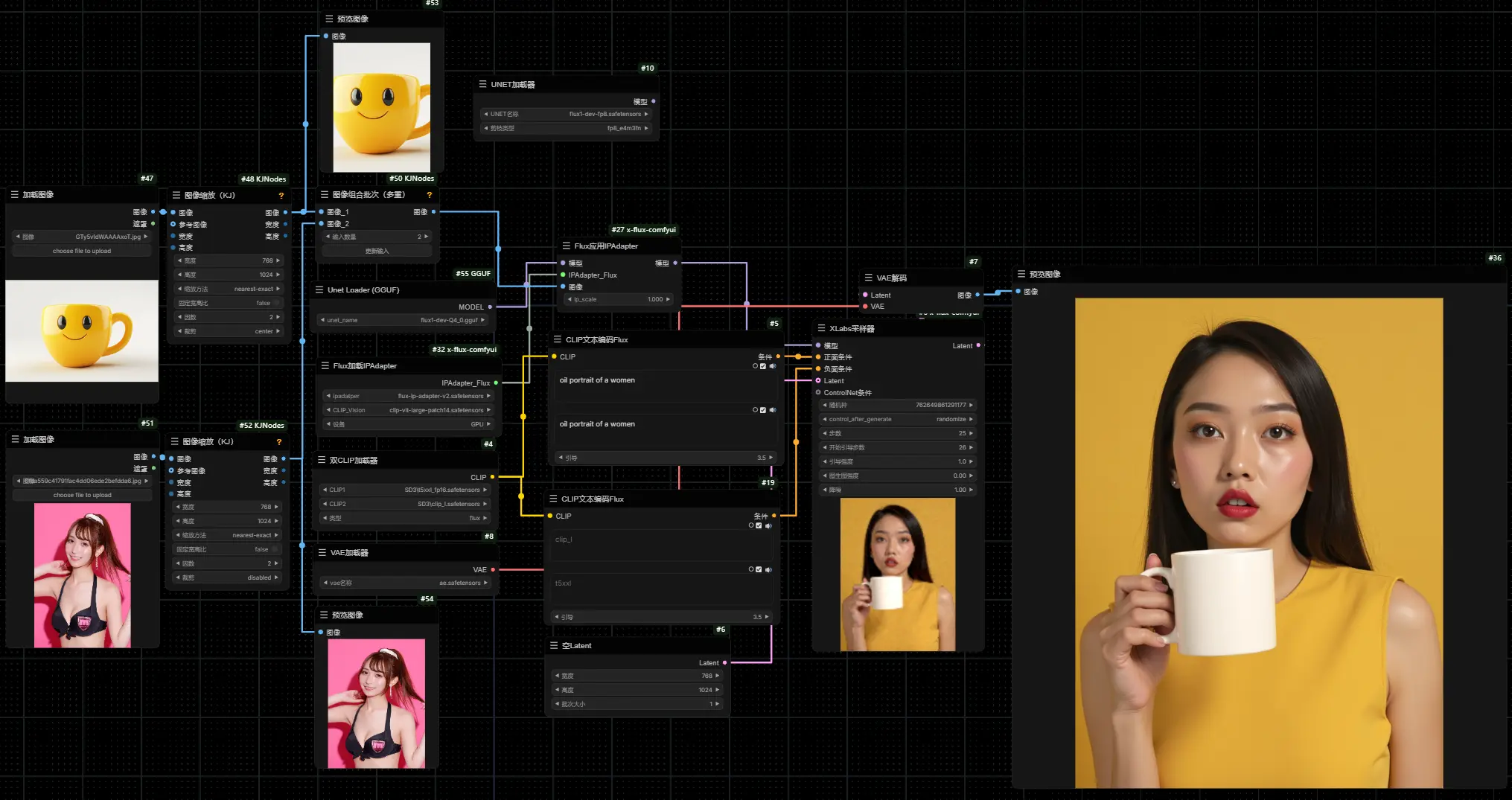
flux-ip-adapter-v2:基于FLUX.1-dev的风格迁移IP-Adapter 模型
XLabs-AI推出了很多基于FLUX.1-dev 模型的ControlNet模型,近期XLabs-AI又推出了基...

ComfyUI-Detail-Daemon:通过在采样过程中直接调整噪声来实现图片细节的调节
ComfyUI-Detail-Daemon是一款基于 Stable Diffusion Web UI插件sd-webui-detail-da...

阿里妈妈推出个性化图像生成新方法EcomID:结合PuLID 和 InstantID 的优点,拥有更好的背景一致性、面部关键点控制、更真实的面部以及更高的相似度
EcomID是阿里妈妈开源的个性化图像生成方法,结合了 PuLID 和 InstantID 的优点,...
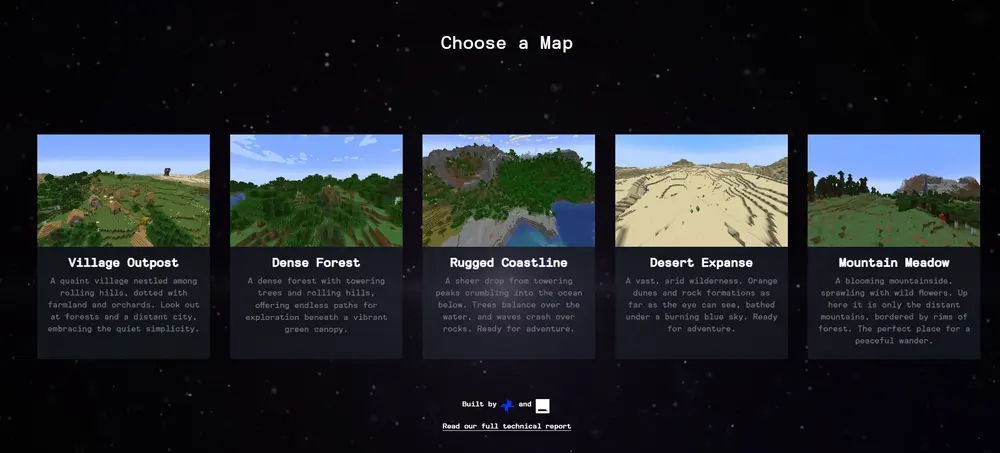
Decart 和 Etched 联手打造的全球首个实时 AI 世界模型Oasis:完全由AI实时生成游戏场景
Oasis 是由 Decart 和 Etched 联手打造的全球首个实时 AI 世界模型。这不仅仅是一...