


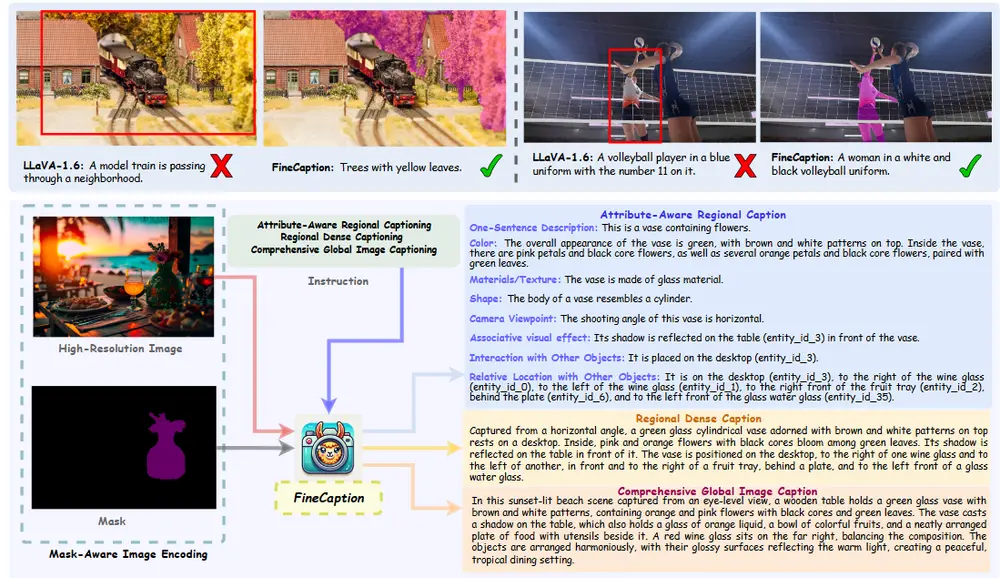
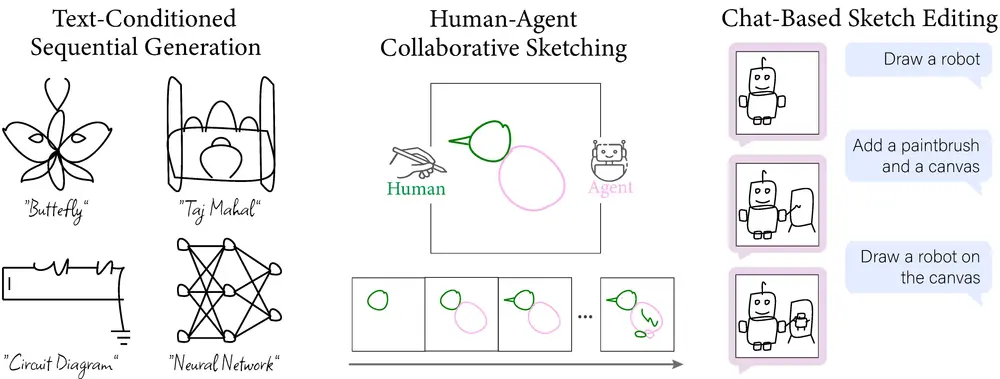
语言驱动的顺序草图生成方法SketchAgent:让用户通过动态、对话式的交互来创建、修改和细化草图
MIT和斯坦福大学的研究人员推出一种语言驱动的顺序草图生成方法SketchAgent,能够...

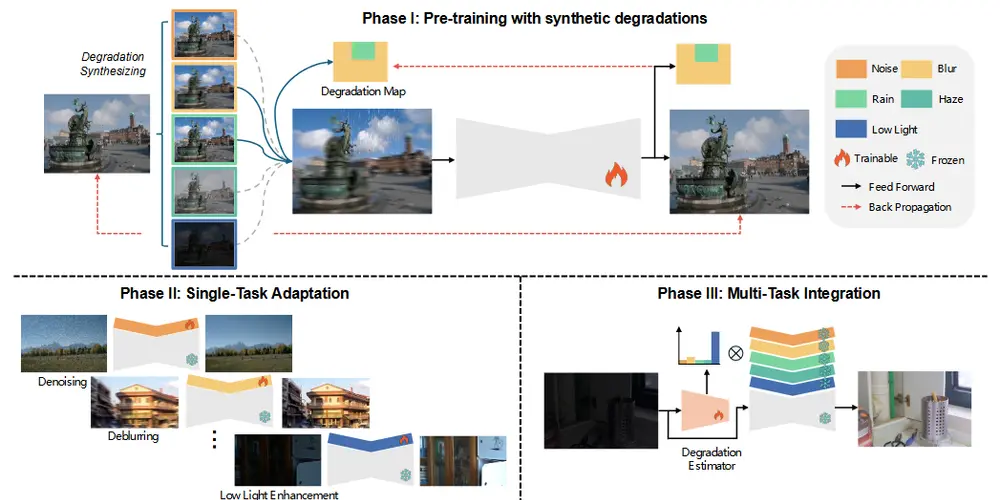
图像修复模型ABAIR:在从受到未知退化影响的输入图像中恢复出高质量的图像
在图像处理领域,盲目的全功能图像恢复(Blind All-in-One Image Restoration, BAI...

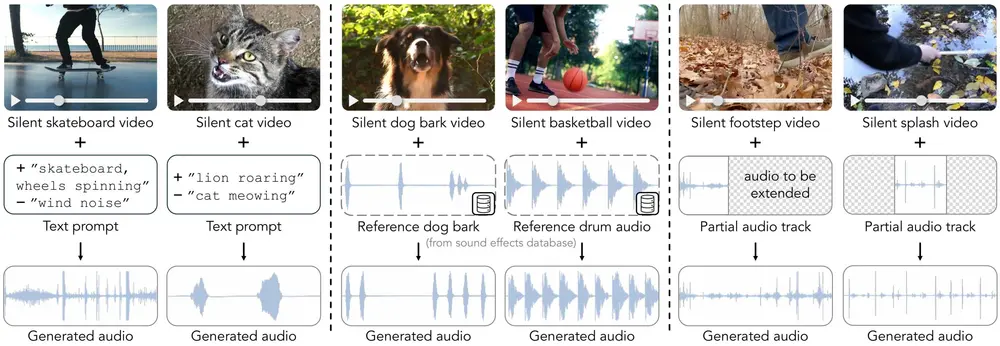
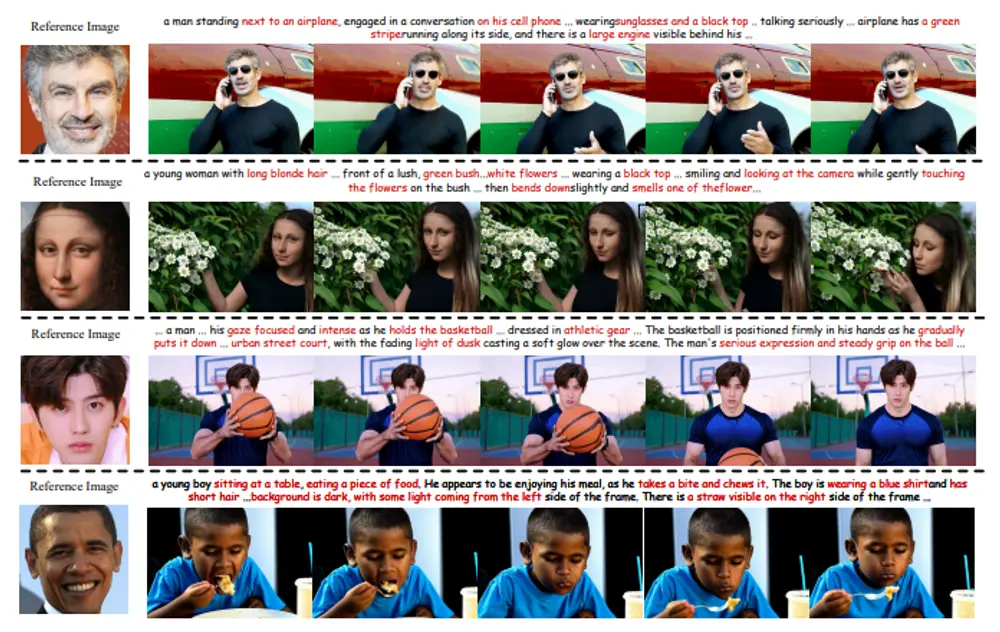
视频引导音效生成模型MultiFoley:根据多种模态的控制信号(包括文本、音频和视频)来生成与视频同步的声音效果
在影视制作、游戏开发和多媒体内容创作中,为视频添加恰当的音效是提升观众体验的...


个性化图像生成的高效、轻量级框架DreamCache:在不需要额外微调的情况下,通过特征缓存实现快速的个性化图像生成
在数字内容创作日益丰富的今天,个性化图像生成技术正逐渐成为各行业创新的关键。...