为了在激烈的市场竞争中更好地应对谷歌等竞争对手,OpenAI近日推出了名为“Flex处理模式”的新API服务。这一服务通过牺牲响应速度和资源稳定性,为用户提供更优惠的模型使用价格。
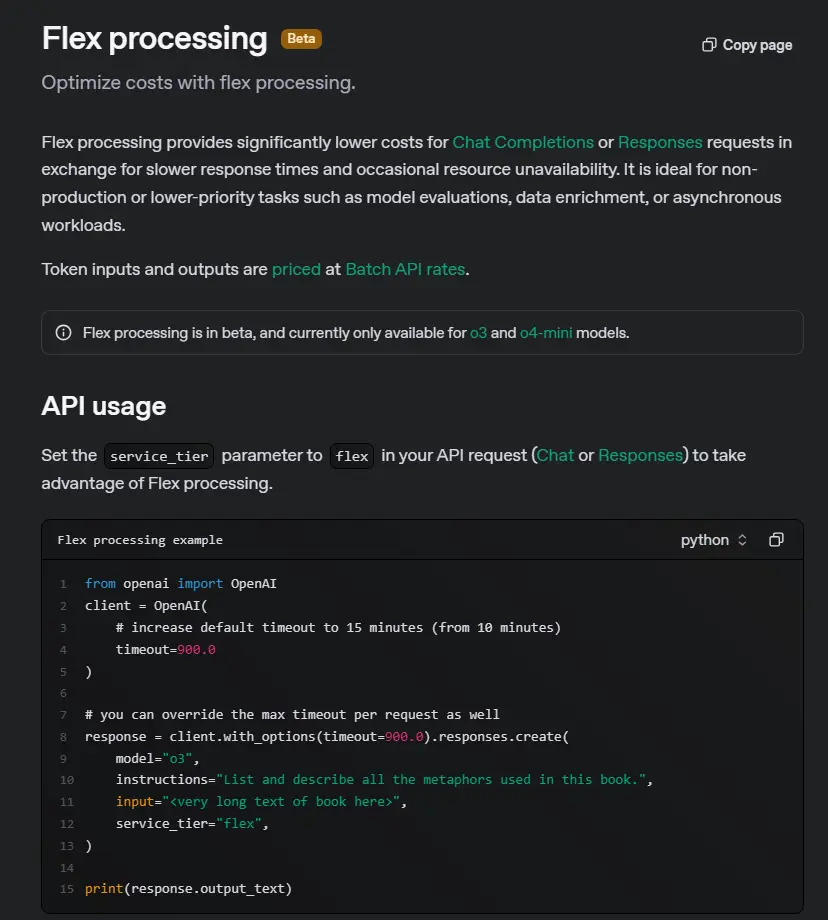
定价策略:
o3模型:在Flex模式下,每百万输入tokens的费用从标准的10美元降至5美元,每百万输出tokens的费用从40美元降至20美元。 o4-mini模型:输入tokens的费用从1.10美元降至0.55美元,输出tokens的费用从4.40美元降至2.20美元。
适用场景:
Flex处理模式目前主要针对OpenAI新发布的o3和o4-mini推理模型开放测试,适用于模型评估、数据扩充、异步处理等低优先级的“非生产”任务。这种模式特别适合那些对实时性要求不高、可以接受一定延迟的用户。
身份验证:
OpenAI还引入了新的身份验证流程。处于OpenAI使用层级体系中第1至第3层的开发者必须完成这一流程,才能获取o3模型的访问权限。此外,o3及其他模型的推理摘要功能和流式API服务同样需要通过身份验证后才能启用。
市场背景:
在当前AI服务成本普遍上涨的背景下,竞争对手纷纷推出性价比更高的产品。例如,谷歌最近发布的Gemini 2.5 Flash模型,其性能与DeepSeek R1相当,且输入tokens的成本更低。OpenAI的Flex处理模式正是为了满足市场对高效、低成本AI解决方案的需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...