ComfyUI-FreeMemory 是 ComfyUI 的一个自定义节点扩展,专为图像生成工作流程中的高级内存管理而设计。它旨在帮助用户避免内存不足错误,并在执行复杂操作时优化资源使用。
功能介绍
ComfyUI-FreeMemory 提供了以下功能:
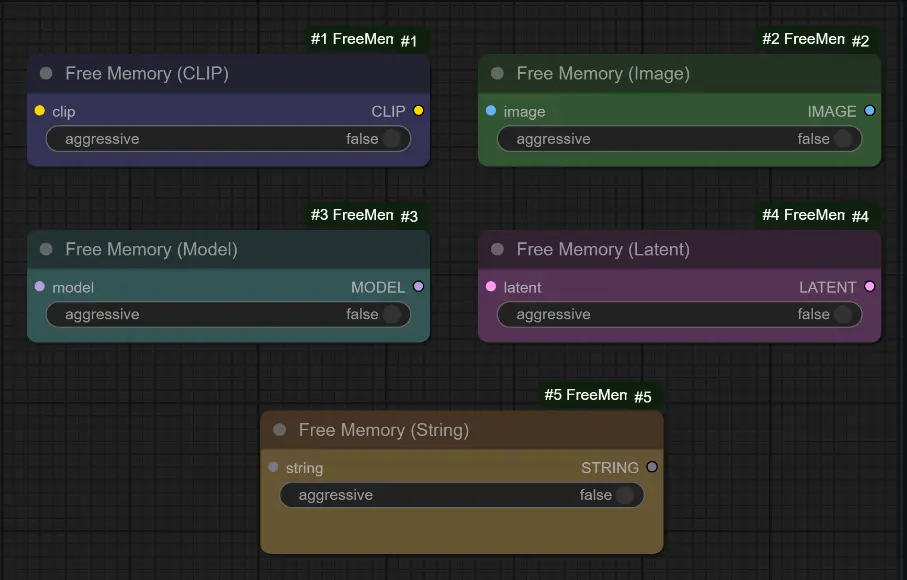
四种专用内存释放节点
- 释放内存(图像):清理内存,同时传递图像数据。
- 释放内存(潜在变量):清理内存,同时传递潜在变量数据。
- 释放内存(模型):清理内存,同时传递模型数据。
- 释放内存(CLIP):清理内存,同时传递 CLIP 模型数据。
- 释放内存(字符串):清理内存,同时传递字符串模型数据。
兼容性
- 兼容 Windows 和 Linux 系统。
- 无缝集成到现有的 ComfyUI 工作流程中。
激进模式
- 每个节点包含一个“激进”布尔输入,用于更彻底的内存清理。
- 默认(False):执行标准内存清理。
- 激进模式(True):执行更彻底的内存清理。
使用方法
基本用法
- 将 FreeMemory 节点(图像、潜在变量、模型或 CLIP)添加到工作流中。
- 将相应的输入(图像、潜在变量、模型或 CLIP)连接到节点。
- 将输出连接到工作流中的下一步。
激进模式
- 在节点的“激进”布尔输入中设置为 True,以启用更激进的内存清理。
工作原理
当执行 FreeMemory 节点时:
- 检查“激进”标志:确定清理强度。
- 显存清理:
- 标准模式:使用
torch.cuda.empty_cache()释放未使用的 CUDA 内存。 - 激进模式:
- 使用
comfy.model_management.unload_all_models()卸载所有模型。 - 使用
comfy.model_management.soft_empty_cache()执行软缓存清空。 - 再次调用
torch.cuda.empty_cache()。
- 使用
- 标准模式:使用
- 系统内存清理:
- 使用
gc.collect()触发 Python 的垃圾收集器。 - 激进模式:
- Linux:执行
sync刷新文件系统缓冲区,并写入/proc/sys/vm/drop_caches清除页缓存、目录项和索引节点。 - Windows:调用 Windows API 的
EmptyWorkingSet减小当前进程的工作集大小。
- Linux:执行
- 使用
- 内存使用情况报告:节点会报告显存和系统内存的初始和最终使用情况,提供清理过程的可视化。
- 数据传递:清理完成后,输入数据将不变地传递到下一步,确保工作流的连续性。
技术细节
显存清理
- 标准模式:使用
torch.cuda.empty_cache()释放未使用的 CUDA 内存。 - 激进模式:
- 卸载所有模型:
comfy.model_management.unload_all_models() - 软缓存清空:
comfy.model_management.soft_empty_cache() - 清除 CUDA 缓存:
torch.cuda.empty_cache()
- 卸载所有模型:
系统内存清理
- 垃圾收集:
gc.collect()触发 Python 的垃圾收集器。 - 激进模式:
- Linux:
- 执行
sync刷新文件系统缓冲区。 - 写入
/proc/sys/vm/drop_caches清除页缓存、目录项和索引节点。
- 执行
- Windows:调用
EmptyWorkingSet减小当前进程的工作集大小。
- Linux:
限制和注意事项
- 内存清理效果:清理的有效性可能因系统状态和工作流的性质而异。
- 激进模式的影响:激进模式可能会暂时减慢操作速度,因为需要重建缓存并重新加载模型。
- 权限要求:某些清理操作(如 Linux 上的
/proc/sys/vm/drop_caches)可能需要提升的权限才能完全生效。 - 无法完全避免内存不足错误:虽然这些节点有助于管理内存,但不能保证完全防止所有内存不足错误。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...