Stable Diffusion 是一种基于深度学习的图像生成模型,它属于扩散模型(Diffusion Models)的范畴。扩散模型是一种生成模型,它通过逐步向数据中添加噪声(扩散过程)来学习数据的分布,然后通过逆转这一过程(逆扩散过程)来生成新的数据样本。Stable Diffusion 是这一技术路线的代表之一,它在图像生成、图像编辑和风格迁移等领域展现出了强大的能力。

Stable Diffusion是2022年发布的深度学习文本到图像生成模型,主要用于根据文本的描述生成高质量图像。Stable Diffusion由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络之一,它是由初创公司StabilityAI、CompVis与Runway合作开发,并得到EleutherAI和LAION的支持。后续模型主要由StabilityAI负责开发,每隔一段时间就会释出新的基础模型。

Stable Diffusion是开源的,采用Creative ML OpenRAIL-M,允许商业和非商业用途。Stable Diffusion的源代码和模型已分别公开发布在GitHub和Hugging Face,可以在大多数配备有适度显卡的电脑硬件上运行。

Stable Diffusion版本
目前流行的Stable Diffusion模型主要是1.5版本、SDXL、SDXL Turbo以及用于视频生成的模型Stable Video。
| 版本号 | 发行日期 | 注释 | 下载地址 |
| 1.5 | 2022年10月 | 目前主流的基础模型,拥有大量的衍生模型 | Hugging Face |
| SDXL | 2023年7月 | 提取自XL 1.0而以更少扩散步骤运行 | Hugging Face |
| SDXL Turbo | 2023年11月 | XL 1.0基础模型有35亿个参数,使其比以前版本大了约3.5倍 | Hugging Face |
| Stable Video | 2023年11月 | 视频生成模型 | Hugging Face |

Stable Diffusion的整体架构和工作原理的简要概述:
整体架构:
- 文本编码器: 将输入的文本描述转换为高维空间中的嵌入向量。这个嵌入向量捕捉了文本描述的内容和风格信息。
- UNet架构的解码器: 这是一个深度神经网络,用于将噪声图像逐步转换为清晰图像。它包含多个卷积层和残差连接,以及注意力机制来提高生成图像的质量。
- 变分自编码器 (VAE): 用于学习图像数据的高效表示,并帮助模型生成新的图像。VAE将图像编码为一个潜在空间的向量,然后可以从中解码出新的图像。
工作原理:
- 文本到嵌入: 当用户输入一个文本描述时,文本编码器将其转换为嵌入向量。
- 噪声图像生成: 使用VAE,从高斯噪声中生成一个初始的噪声图像。
- 去噪过程: UNet解码器逐步减少噪声图像中的噪声量,同时尝试匹配文本描述的嵌入向量。这一过程通常涉及多次迭代,每次迭代都减少一部分噪声,并逐步细化图像的细节。
- 图像生成: 最终,通过多次迭代去噪,模型生成一个与文本描述相匹配的清晰图像。

为什么要使用Stable Diffusion?
相对于其他文生图模型(如DALL-E和Midjourney)只能通过云计算服务且付费使用,因为开源的特性,大量开发者投入开发 Stable Diffusion相关应用,如Stable Diffusion WebUI、Fooocus、ComfyUI等。这些应用都可以在本地安装,依靠个人电脑 CPU/GPU 的算力去生成图像,而且图片版权属于你。除了使用本机电脑的算力,也可以采用 Google Colab 等云端平台来部署软件来使用。
- 开源:许多爱好者创建了免费的工具和模型
- 成本:可本地货云端平台安装使用
可以用Stable Diffusion做什么?
文生图
Stable Diffusion中的文生图采样脚本,称为"txt2img",接受一个提示词,以及包括采样器(sampling type),图像尺寸,和随机种子的各种选项参数,并根据模型对提示的解释生成一个图像文件。

图生图
Stable Diffusion包括另一个取样脚本,称为"img2img",它接受一个提示词、现有图像的文件路径和0.0到1.0之间的去噪强度,并在原始图像的基础上产生一个新的图像,该图像也具有提示词中提供的元素;去噪强度表示添加到输出图像的噪声量,值越大,图像变化越多,但在语义上可能与提供的提示不一致。

视频生成
文生图和图生图是Stable Diffusion最基础的功能,目前通过AnimateDiff 或Stable Video等来进行视频生成。

名词解释:
Transformer
Transformer模型是由Vaswani等人在2017年提出的,它是一种基于自注意力机制(Self-Attention)的深度学习模型,主要用于处理序列数据,如自然语言处理(NLP)任务。Transformer模型的核心思想是捕捉序列中的长距离依赖关系,这在当时是革命性的,因为它摒弃了传统的循环神经网络(RNN)和长短时记忆网络(LSTM)中的循环结构。
CLIP
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
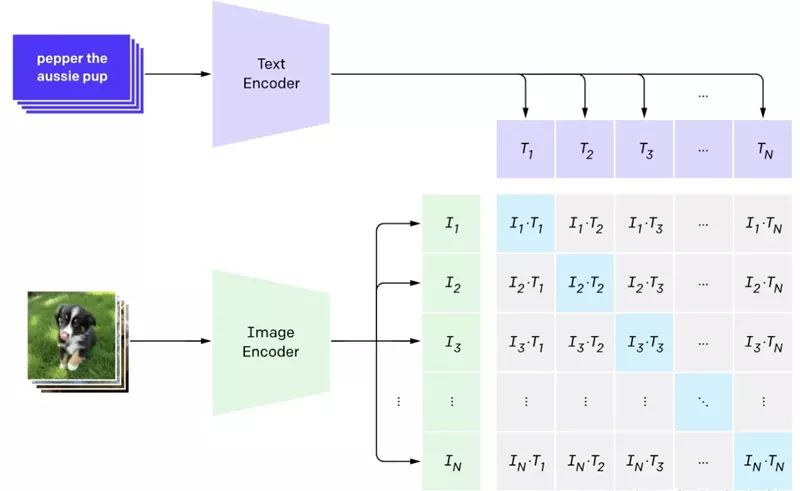
如图所示,CLIP包括两个模型:Text Encoder(文本编译器)和Image Encoder(图像编码器),其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
U-Net
U-Net网络一开始是作为医学影响分割用途被提出来的,U-Net结构能够有效地捕捉图像中的全部和局部信息。在预测过程中,通过反复调用 U-Net,将 U-Net预测输出的 noise slice 从原有的噪声中去除,得到逐步去噪后的图像表示。

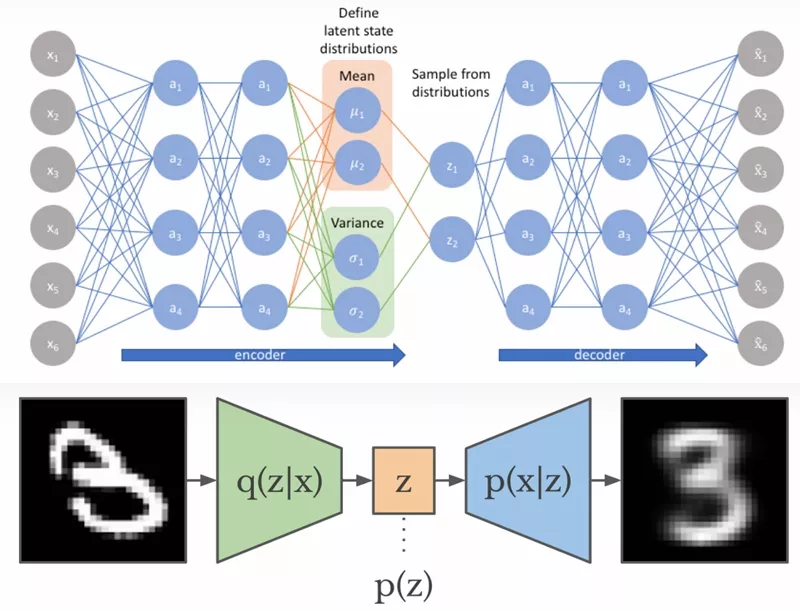
VAE
变分自编码器(Variational Auto-Encoders,VAE)作为深度生成模型的一种形式,是由 Kingma 等人于 2014 年提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构。与传统的自编码器通过数值的方式描述潜在空间不同,它以概率的方式描述对潜在空间的观察,在数据生成方面表现出了巨大的应用价值。对于stable diffusion而言,VAE相当于是一个滤镜。
DDPM/DDIM/PLMS...
stable diffusio中的采样方法其实就是去噪算法,在训练及图像生成阶段,通过指定步数的迭代,将噪音逐步从图像潜空间中去除,而每一次迭代如何去除噪音。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











