
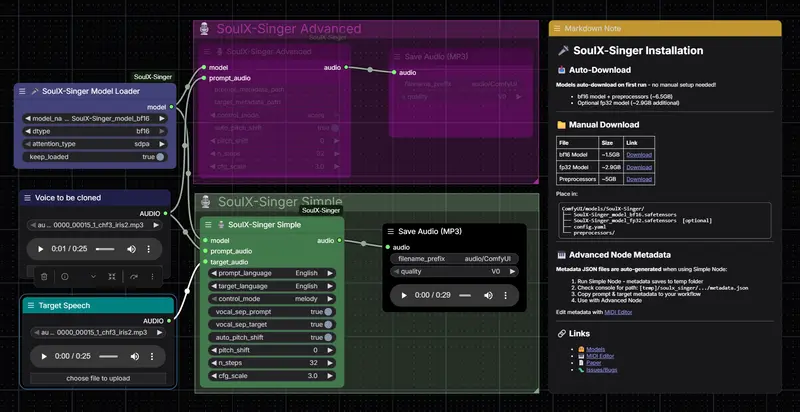
SoulX-Singer 是由 SoulAI-Lab 开发的高保真零样本歌声合成模型。通过仅需 3–10 秒参考音频,即可克隆任意人声并生成自然、富有表现力的演唱。
本项目为其提供 原生 ComfyUI 节点封装,支持两种精准控制模式:
- 旋律条件(F0 基频轮廓):保留原始音频的音高动态
- 乐谱条件(MIDI 音符):按指定音符、节奏与歌词重新演绎
所有处理在本地完成,无需联网,适用于音乐创作、AI 演唱、语音克隆等场景。
核心特性
- 零样本克隆:无需目标歌手训练数据,一段参考音频即可生成新歌声
- 双控制模式:自由切换 F0 轮廓(自然)或 MIDI 乐谱(精确)
- ComfyUI 原生集成:AUDIO 数据线输入、进度条、中断支持
- 高性能推理:支持
bf16/fp32精度、SDPA 与 SageAttention 加速 - 智能下载:首次使用自动按需下载模型(~6.5GB 起)
- 模型缓存:支持
keep_loaded复用模型,避免重复加载 - MIDI 编辑支持:通过高级节点手动编辑歌词、音高、时序元数据
- 跨平台兼容:使用
soundfile + scipy替代torchaudio,提升 Linux/macOS/Windows 兼容性
📌 注意:本工具仅用于学术研究、教育及合法创作,请遵守伦理规范,勿用于伪造或欺骗。
安装指南
✅ 推荐方式:ComfyUI Manager
- 打开 ComfyUI Manager
- 搜索
SoulX-Singer - 点击 Install
- 重启 ComfyUI
手动安装
cd ComfyUI/custom_nodes
git clone --recursive https://github.com/Saganaki22/ComfyUI-SoulX-Singer.git
cd ComfyUI-SoulX-Singer
pip install -r requirements.txt
⚠️
--recursive参数至关重要,用于拉取 SoulX-Singer 子模块。
若已克隆但缺失子模块:
cd ComfyUI/custom_nodes/ComfyUI-SoulX-Singer
git submodule init && git submodule update
pip install -r requirements.txt
快速开始:两种工作流
简单模式(推荐新手)
适用于快速生成,自动完成预处理(人声分离、F0 提取、歌词转录)。
- 加载模型
- 添加
SoulX-Singer Model Loader节点 - 选择模型:
SoulX-Singer_model_bf16(默认,~1.5GB,速度快)SoulX-Singer_model_fp32(高精度,~2.9GB)
- 设置
dtype=bf16(推荐)、attention_type=sdpa - 启用
keep_loaded=True提升多轮效率
- 添加
- 加载音频
prompt_audio:3–10 秒参考歌声(含人声即可)target_audio:目标旋律音频(可为伴奏、哼唱或清唱)
- 合成设置
- 选择语言:普通话 / 英语 / 粤语
- 控制模式:
melody:保留 target 音高轮廓(适合翻唱)score:需后续配合 MIDI 编辑(见高级模式)
- 调整
n_steps=32(平衡质量/速度)、cfg_scale=3.0
- 输出
连接至Preview Audio或Save Audio节点
💡 首次运行将自动下载 ~5GB 预处理模型至
ComfyUI/models/SoulX-Singer/preprocessors/
高级模式(MIDI 精细控制)
适用于专业音乐制作,支持手动编辑歌词、音符、时序。
- 先用简单模式运行一次,生成临时元数据文件(路径见日志)
- 将
prompt.json和target.json复制到项目目录 - 使用 SoulX-Singer MIDI Editor 编辑目标元数据
- 使用
SoulX-Singer Advanced节点,输入:prompt_audio:参考人声prompt_metadata_path:原始元数据target_metadata_path:编辑后的 MIDI 元数据
❓ 为何无 target_audio?
高级模式完全由元数据驱动——模型从头合成新音频,而非转换现有音频,实现真正的“按谱演唱”。
文件结构与存储优化
模型默认存储于:
ComfyUI/models/SoulX-Singer/
├── SoulX-Singer_model_bf16.safetensors # ~1.5GB
├── SoulX-Singer_model_fp32.safetensors # ~2.9GB(可选)
├── config.yaml
└── preprocessors/ # ~5GB(人声分离、F0 提取等)
💾 节省空间:使用符号链接
Windows:
mklink /D "ComfyUI\models\SoulX-Singer" "D:\AI\Models\SoulX-Singer"
Linux/macOS:
ln -s /path/to/models/SoulX-Singer ComfyUI/models/SoulX-Singer
节点自动解析符号链接,不影响功能。
节点参数详解
Model Loader
| 参数 | 说明 |
|---|---|
model_name | 自动检测 .safetensors 文件,带 (download) 表示未下载 |
dtype | bf16(推荐)或 fp32;不支持 fp16(声码器兼容问题) |
attention_type | sdpa(默认)或 sageattention(需 pip install sageattention) |
keep_loaded | 缓存模型至内存,多次生成时显著提速 |
Simple Synthesizer
| 参数 | 说明 |
|---|---|
enable_preprocessing | True:完整流程(人声分离 + F0 + 转录)False:仅 F0 + 转录(仅限纯净人声) |
vocal_sep_prompt/target | 手动开关人声分离(当 enable_preprocessing=False 时生效) |
auto_pitch_shift | 自动对齐参考与目标音域(不同歌手建议开启) |
Advanced Synthesizer
- 输入为 元数据 JSON 路径,非音频
- 元数据包含:歌词、音素、MIDI 音符、F0、时序等
- 适合与 DAW 或 MIDI 编辑器联动
性能调优建议
| 场景 | 推荐配置 |
|---|---|
| 快速试听 | bf16 + n_steps=16 + keep_loaded=True |
| 高质量输出 | fp32 + n_steps=64 + cfg_scale=4.0 |
| 低显存设备 | bf16 + keep_loaded=False + 关闭其他应用 |
| 最大速度 | 安装 sageattention,设 attention_type=sageattention |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











