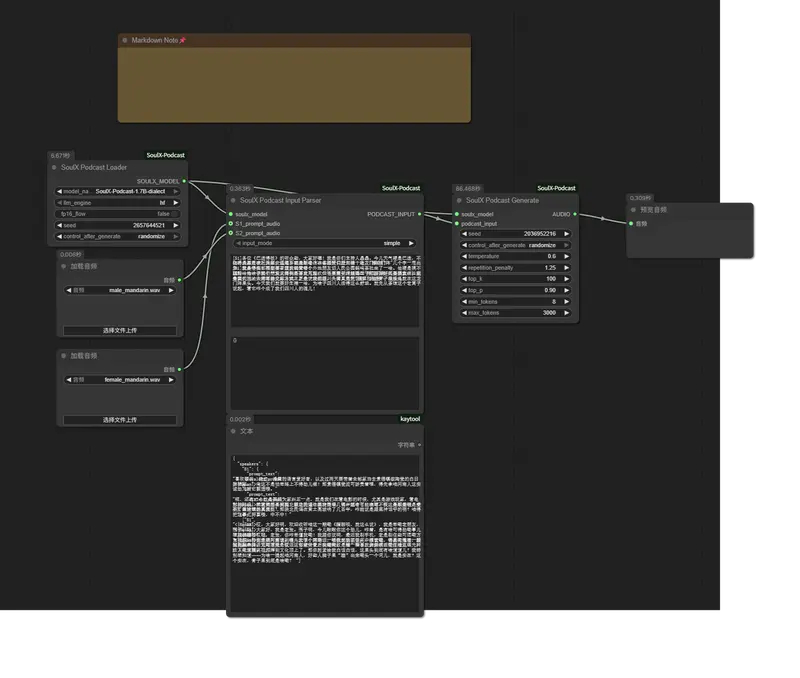
ComfyUI-SoulX-Podcast 是一个专为 ComfyUI 设计的自定义节点插件,将 SoulX-Podcast 的核心能力——长篇、多说话人、多方言的播客语音生成——封装为直观的可视化工作流。用户可通过简单脚本定义对话,并利用参考音频(如 Suno 生成片段)克隆说话人音色,一键生成高质量播客。
核心特性
- 双人播客生成:支持 S1/S2 两位说话人交替对话
- 多方言支持:普通话、四川话、河南话、粤语等(需加载方言模型)
- 脚本驱动:通过
[S1]/[S2]标记定义对话内容 - 音色克隆:使用提示音频(5–15 秒)提取并复用说话人音色
- 长文本支持:可生成数分钟以上的连贯播客内容
- 全节点化工作流:从加载模型到输出音频,全程在 ComfyUI 中完成
安装与依赖
系统要求
- Python 环境(建议 3.10+)
- CUDA 支持的 GPU(用于加速推理)
关键依赖(务必注意版本)
s3tokenizer
diffusers
torch>=2.0 (with CUDA)
transformers==4.57.1 # ⚠️ 必须为此版本!
onnxruntime-gpu # 或 onnxruntime(CPU 模式)
einops
librosa
scipy
❗ 重要:
transformers版本必须为 4.57.1,其他版本可能导致兼容性错误。
模型准备
将模型文件放入 ComfyUI 标准目录:
ComfyUI/
└── models/
└── TTS/
├── SoulX-Podcast-1.7B/ # 普通话模型
│ ├── soulxpodcast_config.json
│ ├── flow.pt
│ ├── hift.pt
│ ├── campplus.onnx
│ └── [LLM 权重文件...]
└── SoulX-Podcast-1.7B-dialect/ # 方言模型(含川话、粤语等)
💡 如需生成方言内容,请在 SoulX Podcast Loader 节点中选择
*-dialect模型。
快速开始
基础工作流(5 步完成)
- SoulX Podcast Loader
- 选择模型(如
SoulX-Podcast-1.7B-dialect) - 设置 LLM 引擎(
hf或vllm)
- 选择模型(如
- 加载提示音频
- 使用 ComfyUI 内置 Load Audio 节点
- 为 S1 和 S2 分别提供 5–15 秒清晰人声(可来自 Suno、录音等)
- SoulX Podcast Input Parser
- 输入对话脚本,格式如下:
[S1] 大家好,欢迎收听本期节目。 [S2] 今天我们要聊一聊 AI 语音合成。 [S1] 没错,最近的技术进展非常快……
- 输入对话脚本,格式如下:
- SoulX Podcast Generate
- 调整生成参数(温度、重复惩罚等)
- 启动生成
- 预览/保存音频
- 连接至 Preview Audio 或 Save Audio 节点
📎 可直接导入示例工作流:
example/example_workflow.json
节点详解
1. SoulX Podcast Loader(模型加载器)
| 参数 | 说明 |
|---|---|
model_name | 从 models/TTS/ 下拉选择模型 |
llm_engine | hf(HuggingFace)或 vllm(更快,需安装) |
fp16_flow | 启用 FP16 可节省显存,但可能轻微影响音质 |
seed | 随机种子(0–4294967295) |
输出:
SOULX_MODEL对象(供后续节点使用)
2. SoulX Podcast Input Parser(输入处理器)
输入模式:
- Simple 模式(推荐):直接填写多行文本脚本
- JSON 模式:适用于程序化生成
自动处理:
- 解析
[S1]/[S2]标记 - 从提示音频提取说话人嵌入(via
campplus.onnx) - 将文本转为 token ID 序列
- 生成梅尔频谱特征
输出:
PODCAST_INPUT对象
3. SoulX Podcast Generate(生成器)
| 参数 | 默认值 | 说明 |
|---|---|---|
temperature | 0.6 | 控制生成随机性(0.5–0.7 适合对话) |
repetition_penalty | 1.25 | 抑制重复(1.15–1.35 推荐) |
max_tokens | 3000 | 单句最大长度(按需调整) |
top_k / top_p | 100 / 0.9 | 采样策略(通常保持默认) |
输出:24kHz WAV 格式音频(符合 ComfyUI AUDIO 标准)
参数调优建议
| 目标 | 推荐设置 |
|---|---|
| 高音质 | 关闭 fp16_flow,使用高质量提示音频 |
| 稳定对话 | temperature=0.6,repetition_penalty=1.25 |
| 快速生成 | 启用 vllm 引擎 + 开启 fp16_flow |
| 方言准确 | 务必加载 *-dialect 模型,并在脚本中使用对应方言词汇 |
常见问题
Q1: 模型加载失败?
→ 检查路径是否为 ComfyUI/models/TTS/[模型名]/,并确认所有文件(.pt, .onnx, .json)齐全。
Q2: 音色不稳定?
→ 使用 10 秒以上、无背景噪音 的提示音频,避免音乐或多人混杂。
Q3: 生成速度慢?
→ 尝试 vllm 引擎(需额外安装),或降低 max_tokens。
Q4: 脚本格式报错?
→ 必须使用 [S1] 和 [S2] 标记,不可省略方括号。
技术架构
生成流程:
对话脚本 → Qwen3-1.7B LLM → 语义 Token → CausalMaskedDiffWithXvec (Flow) → 梅尔频谱 → HiFT 声码器 → 24kHz 音频波形
核心组件:
- LLM:Qwen3-1.7B(生成自然对话)
- 声学模型:Flow(基于扩散,支持长上下文)
- 声码器:HiFT(高保真波形合成)
- 说话人嵌入:CampPlus ONNX(从提示音频提取音色)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











