来自加州大学伯克利分校、卡内基梅隆大学和Google Deepmind的研究人员推出新的适配器样式Stylus,它能够自动选择和组合适配器(adapters),以提高生成图像的质量。适配器是一种在特定任务上微调模型的技术,可以在不显著改变模型参数的情况下,提高模型在特定任务上的性能。Stylus通过自动选择和组合适配器,提高了图像生成的质量和多样性,同时减少了人工选择适配器的复杂性和时间成本。
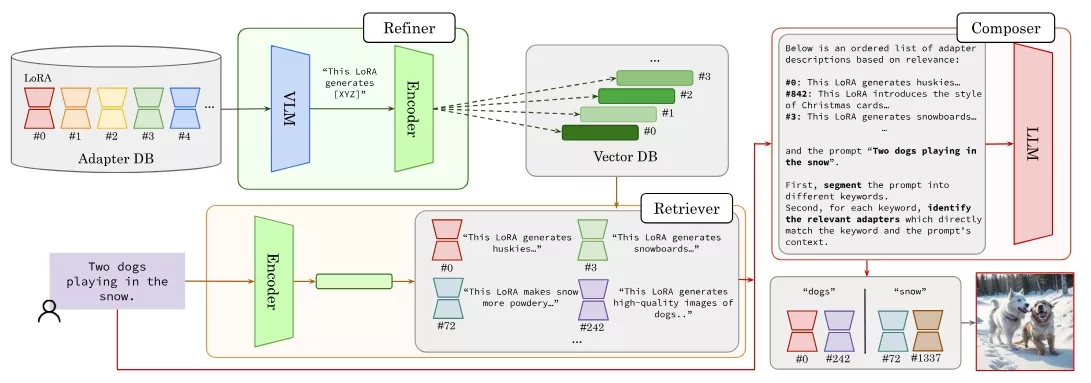
Stylus是基于提示的关键字高效地选择和自动组合特定任务的适配器。Stylus概述了一个三阶段方法,首先通过改进的描述和嵌入来总结适配器,然后检索相关适配器,最后根据提示的关键字进一步组装适配器,检查它们与提示的匹配程度。为了评估Stylus,开发人员开发了StylusDocs,这是一个包含7.5万个适配器并带有预计算适配器嵌入的精选数据集。在流行的Stable Diffusion模型上的评估中,Stylus在CLIP/FID Pareto效率方面取得了更高的成绩,并且在人类和多模态模型作为评估者的情况下,相比基础模型更受青睐,优势高达两倍。

例如,你想要使用一个AI模型来生成一张具有特定风格的图片,比如一幅看起来像梵高画作的风景图。为了达到这个效果,你需要选择一个合适的适配器来调整AI模型的输出。但是,如果有成百上千个适配器可供选择,而且每个适配器都有不同的功能和风格,那么找到最合适的适配器可能会非常困难。Stylus就是来解决这个问题的,它能够自动从众多适配器中选择出最合适的组合,以便生成满足你需求的图像。
主要功能:
- 自动适配器选择:根据用户提供的提示(prompt),自动选择最相关的适配器。
- 适配器组合:将选定的适配器组合起来,以生成具有所需特征的图像。
主要特点:
- 三阶段框架:包括精炼(Refine)、检索(Retrieve)和组合(Compose)三个阶段,有效处理适配器的选择和组合。
- 改进的描述和嵌入:通过多模态视觉-语言模型(VLM)生成适配器的描述,并使用文本编码器生成嵌入,以便于检索。
- 减少偏差:通过掩码策略(masking scheme)和权重调整,减少适配器组合可能引入的不希望的效果。
工作原理:
- 精炼(Refine):使用多模态视觉-语言模型和文本编码器来生成适配器的描述和嵌入。
- 检索(Retrieve):根据用户提示,检索与整个提示最相关的适配器集合。
- 组合(Compose):将提示分割成不同的任务,并为每个任务分配适配器,然后通过掩码策略生成多样化的图像。
具体应用场景:
- 文本到图像的生成:根据文本提示生成具有特定风格或内容的图像。
- 图像到图像的应用:如图像翻译和修复,将一张图片转换为另一种风格或填补图片中的缺失部分。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











