继上月发布旗舰模型 Gemini 3 Pro 后,谷歌于 12 月 17 日正式推出轻量级版本 Gemini 3 Flash,专为成本与延迟敏感的实时、高吞吐量 AI 应用打造,在保留 Pro 版核心能力的同时,实现成本大幅下调,为开发者与企业提供了极具性价比的推理选择。以下是模型核心信息、性能表现、定价策略及使用渠道的完整解析。

定位:填补低延迟高性价比的市场空白
Gemini 3 Pro 虽在多项 AI 基准测试中表现优异,但较高的成本(输入 2 美元/百万 token、输出 12 美元/百万 token)与延迟,使其难以覆盖实时客服、高频交互智能体、大规模内容审核等对成本和响应速度敏感的场景。
Gemini 3 Flash 则以实时和高吞吐量推理优化为核心定位,主打低延迟,同时完整保留 Gemini 3 Pro 级别的多模态能力(支持文本、图像、音频、视频输入)与推理性能,完美适配对响应速度和成本控制有双重需求的应用场景。
定价:成本直降 85%,缓存模式再享巨幅优惠
Gemini 3 Flash 的定价策略极具竞争力,大幅降低了 AI 应用的落地成本,具体如下:
| 计费类型 | 标准价格 | 缓存模式价格 | 较 Gemini 3 Pro 降幅 |
|---|---|---|---|
| 输入 token | 0.30 美元/百万 | 0.075 美元/百万 | 约 85% |
| 输出 token | 2 美元/百万 | — | 约 83% |
缓存模式下输入 token 成本仅为标准价的 1/4,可帮助存在重复 token 输入的高频场景(如固定格式客服问答、标准化内容生成)进一步降低 90% 左右的成本,综合性价比优势显著。
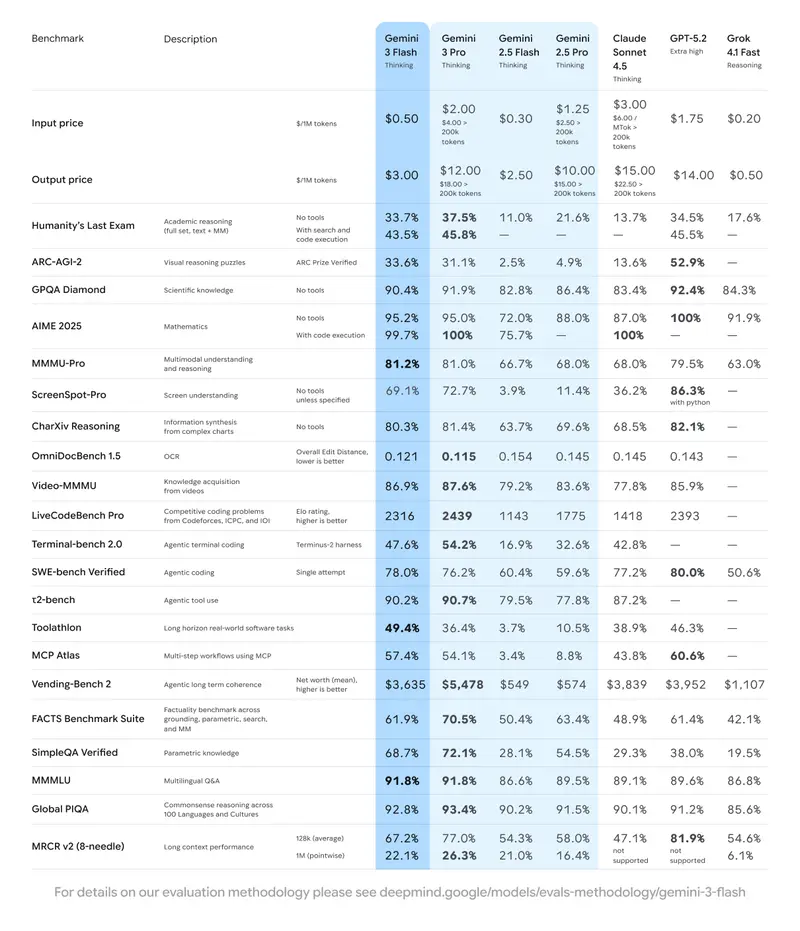
性能:越级表现,部分基准超更大规模模型
Gemini 3 Flash 在核心 AI 基准测试中展现出强劲实力,部分成绩甚至超越更大规模的前沿模型,具体关键数据如下:
- GPQA Diamond(博士级推理):90.4%;
- Humanity‘s Last Exam(无工具):33.7%;
- 速度优势:推理速度较 Gemini 2.5 Pro 提升约 3 倍,实现近实时响应;
- 代码能力:SWE - bench 测试得分 78%,小幅领先 Gemini 3 Pro 的 76.2%。
该模型凭借架构优化实现“提速不降智”,在多模态处理、智能体任务、编码等场景中,能以轻量级体量提供接近旗舰模型的输出质量。
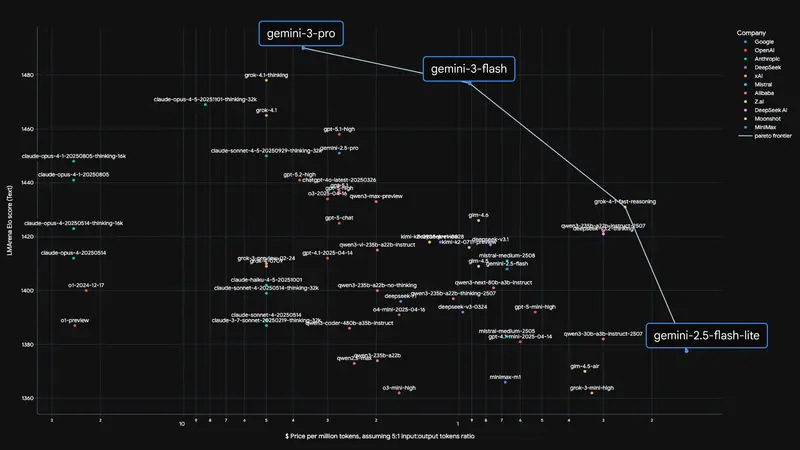
获取渠道与行业影响
1. 接入渠道
Gemini 3 Flash 已全面开放,不同用户群体可通过以下渠道快速接入:
- 开发者:Google AI Studio、Gemini CLI、Google Antigravity、Android Studio;
- 企业用户:Vertex AI 平台(适配企业级大规模部署需求)。
2. 行业竞争格局变化
上周 OpenAI 推出 GPT - 5.2 系列模型,在多数基准测试中略优于 Gemini 3 Pro,且定价相近。谷歌 Gemini 3 Flash 的发布,以极致性价比抢占中低端高吞吐 AI 应用市场。业内预测,OpenAI 大概率将在未来几周推出 GPT - 5.2 Mini 模型,以应对谷歌的价格与性能攻势,AI 大模型市场的性价比竞争将进一步白热化。(官方介绍)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...