在 AI 图像与视频生成领域,一个长期存在的误解是:只要显存足够大,就能流畅运行高质量模型。
但事实并非如此。许多用户花高价购买 24GB 显存的显卡,却发现生成 720p 视频仍卡顿;而有些人用 16GB 显存配合合理配置,反而能稳定出片。
Reddit 用户 Volkin1 最近发布了一组详实的显卡基准测试,聚焦于 ComfyUI 环境下的图像与视频生成任务,涵盖 RTX 30/40/50 系列主流型号,并深入分析了显存卸载机制、PCIe 数据吞吐表现以及实际性能瓶颈。
本文基于其原始数据与观察,进行系统性整理与解读,帮助你做出更理性的硬件决策。
⚠️ 说明:本测试专注于 图像与视频生成(如 Wan2.1/2.2、Flux、Qwen、Kontext 等模型),不适用于大语言模型推理评估。所有测试均使用原生 ComfyUI 工作流,启用 Torch 编译与 fp16 累积,以实现最优性能与内存管理。
测试环境与方法
测试目标
- 比较主流消费级与专业级显卡在高分辨率 AI 视频生成中的表现
- 分析显存不足时,系统内存卸载的实际效率
- 提供最小与推荐配置建议,指导购买决策
核心参数
- 模型:Wan2.2 / Wan2.1 FP16,720p 分辨率,81 帧视频
- 框架:ComfyUI(官方原生工作流)
- 优化:启用 Torch 编译 + fp16 累积
- 测试平台:本地桌面 + 云服务器双环境验证
- 监控工具:英伟达系统日志,监测 PCIe Rx/Tx 传输速率
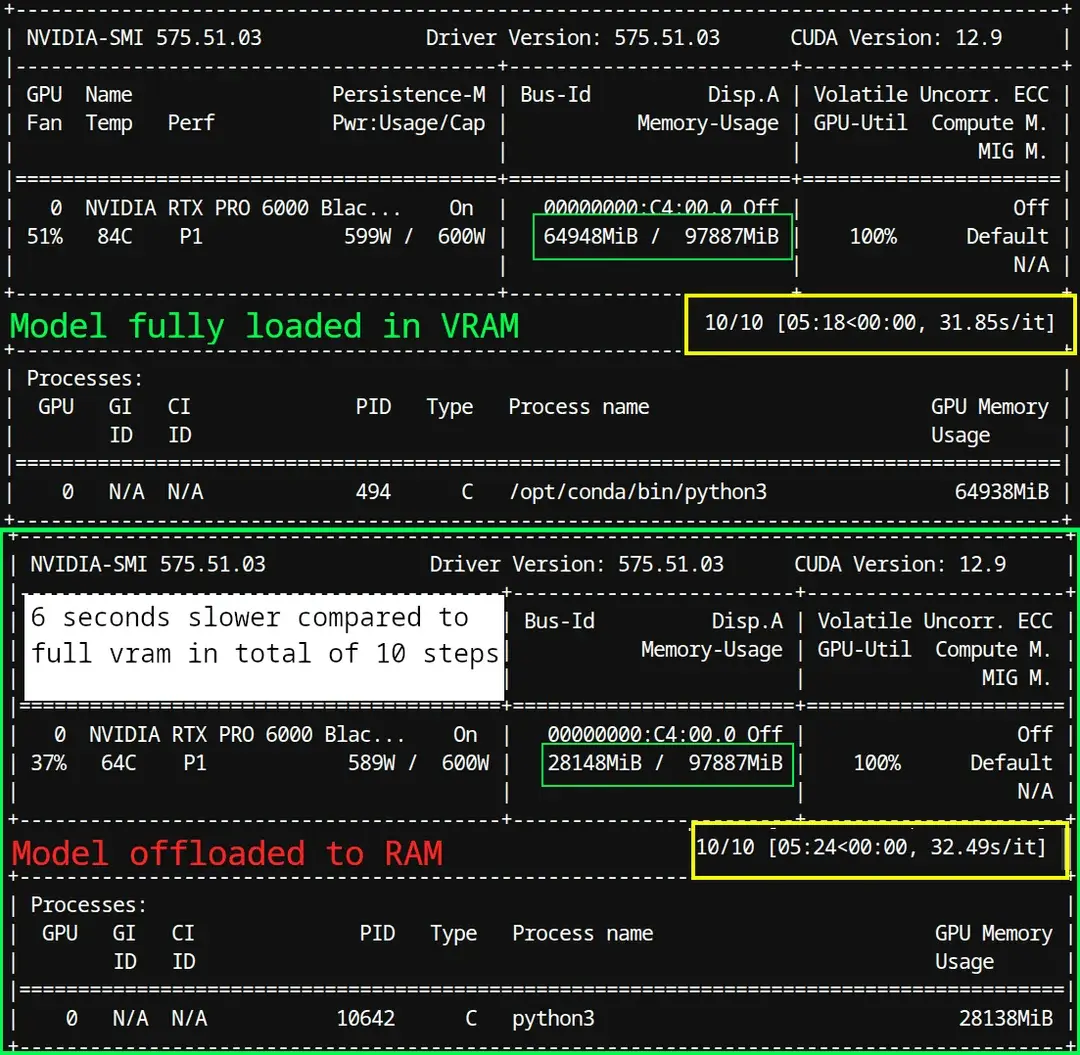
显存卸载真相:内存并不“慢”
一个普遍误区是:当显卡显存不足时,将模型部分加载到系统内存(RAM)会导致严重性能下降——因为“内存比显存慢”。
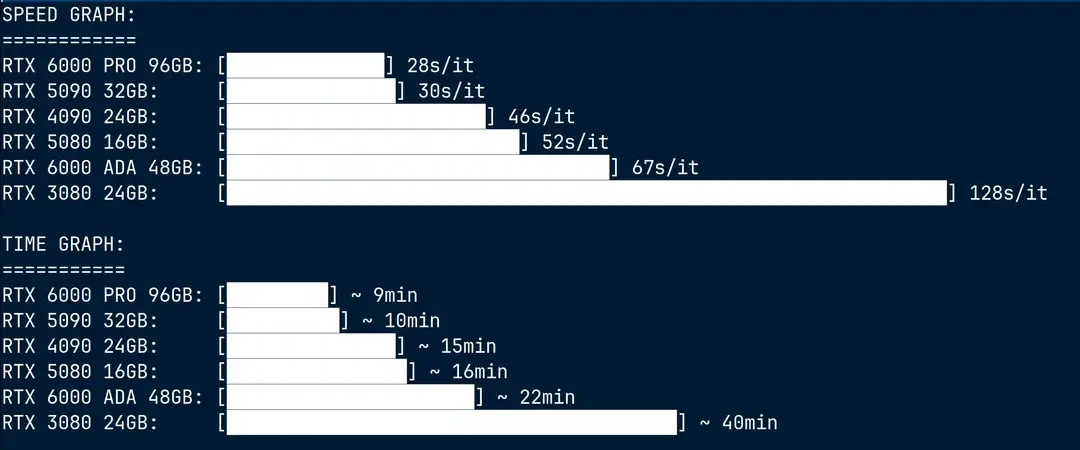
但 Volkin1 的实测数据表明:这种性能损失远比想象中小,关键在于现代 PCIe 总线的带宽能力和卸载机制的设计。
实测数据(RTX 6000 PRO 与 RTX 5080)
| 数据方向 | 平均传输速率 |
|---|---|
| 内存→ 显存(卸载加载) | ~900 MB/s |
| 显存 → 内存(数据回传) | ~72 MB/s |
这意味着系统可以在每秒约 1 GB 的速率下,将模型块从内存动态加载到显存。
而 PCIe 5.0 x16 的理论带宽为:
3.938 GB/s × 16 = 63 GB/s
即使考虑到协议开销和实际调度延迟,实测峰值可达 9.21 GB/s,远高于当前 AI 推理中模型块交换的实际需求。
结论:
- 系统内存作为“扩展显存”是完全可行的
- 卸载带来的性能损失微乎其微,尤其在合理调度下
- 所谓“内存太慢”的说法,在现代 PCIe 架构下已不成立
卸载是如何工作的?——提前预取机制
那么,为什么卸载能如此高效?
根据观察,现代 AI 推理框架(如 ComfyUI)的卸载机制本质上是一种异步预取策略:
- 显卡正在处理第 N 步时
- 系统提前将第 N+1 步所需的模型权重从内存加载到显存
- 当显卡完成第 N 步后,所需数据已就绪
这种“流水线式”加载极大减少了等待时间,使得即使部分模型驻留在内存中,也能实现接近全 显存 运行的效率。
💡 类比:就像视频播放时提前缓冲下一帧,而不是边播边等。
此外,ComfyUI 提供多种内存管理参数,可精细控制卸载行为:
--novram:禁用显存优化--lowvram:优先使用系统内存--reserve-vram:保留部分显存用于关键操作
这些选项让开发者可根据硬件灵活调整策略。
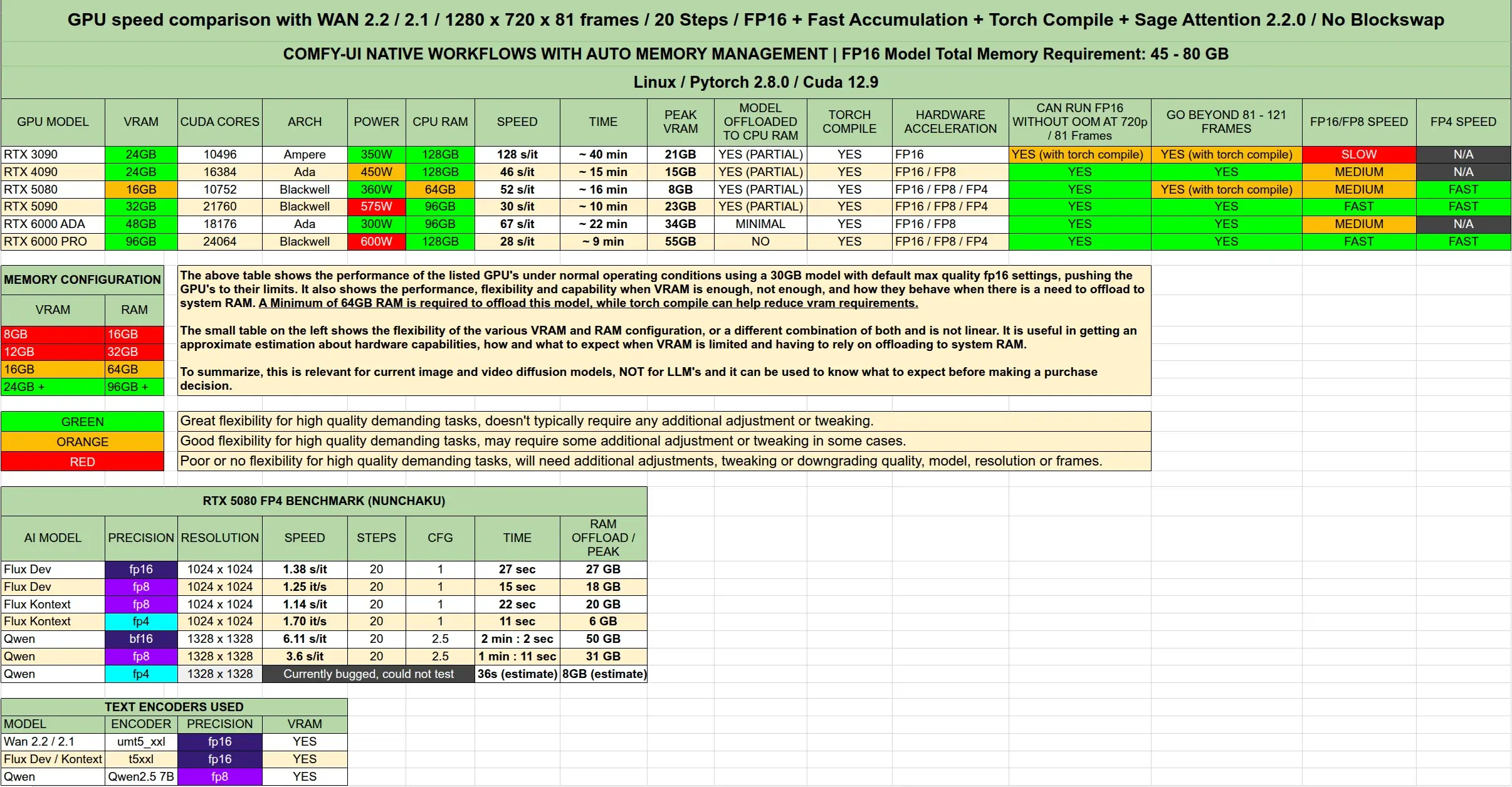
各显卡表现与显存需求分析
1. 显存使用情况(峰值)
| 显卡型号 | 峰值显存占用(Wan2.2 720p 81帧) |
|---|---|
| RTX 4070 Ti (12GB) | 超出,需卸载 |
| RTX 4080 (16GB) | 接近上限,轻微卸载 |
| RTX 4090 / 5080 (24GB) | 可全载运行,余量充足 |
| RTX 6000 PRO (48GB) | 宽松运行,支持更高分辨率 |
✅ 启用 Torch 编译后,显存占用平均降低 15%-20%
2. 性能差异的真实原因
很多人认为 RTX 5090 比 RTX 6000 PRO 慢是因为“频繁卸载”,但实测显示:
- 主要差距来自 CUDA 核心数量:5090 比 6000 PRO 少约 4000 个核心
- 卸载本身并非瓶颈,PCIe 带宽足够支撑
- 真正限制性能的是计算单元数量与架构效率
这也解释了为何某些 24GB 显存的消费卡在复杂工作流中仍不如专业卡流畅。
购买建议:三档配置推荐
基于实测数据与成本效益分析,Volkin1 提出以下三类配置建议:
1. 最低配置(预算有限)
| 组件 | 推荐 |
|---|---|
| 显卡 | RTX 4070 Ti/ 5070 系列,16GB 显存起步 |
| 系统内存 | 64GB内存 |
| 说明 | 可运行 Wan 等主流模型,需依赖内存卸载。建议选择支持 FP4 加速的 50 系列,未来兼容性更好 |
📌 12GB 显存已不足以应对 720p 以上视频生成,不推荐。
2. 性价比首选(追求流畅体验)
| 组件 | 推荐 |
|---|---|
| 显卡 | RTX 4090(24GB)、即将发布的 RTX 5070 Ti SUPER / 5080 SUPER(24GB) |
| 系统内存 | 64–96GB 内存(推荐 96GB) |
| 说明 | 可全载运行主流模型,减少卸载依赖。50 系列因支持 FP4 硬件加速,在低精度推理中效率更高 |
✅ 适合内容创作者、独立工作室,兼顾性能与成本。
3. 高端专业配置(极致性能)
| 组件 | 推荐 |
|---|---|
| 显卡 | RTX 6000 PRO(48GB)或 RTX 5090 |
| 系统内存 | 96GB 内存起步 |
| 说明 | 支持 4K 分辨率、长序列视频生成,无需卸载,稳定性最佳 |
💼 适合影视级 AI 制作、企业级渲染集群。
FP4 支持:50 系列的关键优势
RTX 50 系列引入了对 FP4 精度的硬件级支持,这在 AI 推理中具有重要意义:
- 模型体积缩小近 50%
- 推理速度提升 1.3–1.8 倍
- 显存占用显著降低
这意味着即使在 16GB 显存下,50 系列也能运行原本需要 24GB 的模型。
🔍 示例:Wan2.2 模型在 FP4 下可压缩至原大小的 55%,大幅缓解显存压力。
因此,如果考虑长期使用,50 系列是更优选择。
重要提醒:工作流影响巨大
本文所有测试均基于 原生 ComfyUI 工作流。
如果你使用第三方插件或封装工具(如 Kijai 的包装器),虽然功能更强大,但可能:
- 内存管理策略不同
- 卸载效率降低
- 实际显存占用更高
因此,同样的硬件,在不同工作流下表现可能差异显著。
建议:
- 优先使用官方或社区验证的内存优化工作流
- 合理配置
--lowvram等参数 - 避免盲目追求“一键生成”,牺牲稳定性
结语:别只看显存,系统协同才是关键
这场测试给我们最重要的启示是:
AI 生成性能 ≠ 显存大小
真正的瓶颈往往不在“有没有 24GB”,而在:
- 是否合理利用 PCIe 带宽
- 是否启用 Torch 编译与 fp16
- 是否选择支持新精度格式(如 FP4)的硬件
- 是否搭配足够大的系统内存
未来的 AI 推理,是显卡、处理器、内存与 PCIe 总线的协同作战。
盲目堆显存不如构建一个均衡高效的系统。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...