
在大模型强化学习(RL)训练中,rollout 生成是耗时最长的环节之一。以 DAPO-32B 为例,rollout 阶段占据了约 70% 的总训练时间。这一瓶颈使得整个训练流程效率低下,尤其在大规模模型上更为明显。
为解决这一问题,FlashRL 应运而生——这是首个开源且可直接部署的 RL 训练方案,能够在保持下游性能的前提下,对 rollout 阶段进行高效量化。它通过一项关键技术实现了性能与速度的兼顾:
pip install flash-llm-rl
只需一条命令即可安装使用,支持 INT8 和 FP8 量化,兼容主流 GPU 架构,包括 H100 和 A100。
为什么量化 rollout 如此困难?
传统上,研究人员倾向于在训练过程中使用高精度(如 BF16)进行 rollout 生成,以确保生成质量稳定。而一旦引入低精度(如 INT8 或 FP8),模型输出可能发生偏移,导致策略梯度估计偏差,进而影响最终训练效果。
因此,“量化 rollout 是否可行” 一直是一个悬而未决的问题。核心挑战在于:
- 量化后的 rollout 与训练阶段存在分布差异;
- 推理引擎缺乏对参数动态更新的支持;
- 不同精度下响应长度不一致,难以公平评估吞吐量。
FlashRL 正是从这两个关键点切入,提出了一套完整、可用的解决方案。
FlashRL 的两大核心技术
1. 截断重要性采样(TIS):修复 rollout 与训练的不匹配
当 rollout 使用量化模型生成样本时,其策略分布与训练时使用的高精度模型之间会产生偏差。这种偏差会累积并影响策略优化方向。
FlashRL 引入了 截断重要性采样(Truncated Importance Sampling, TIS) 来缓解该问题。TIS 能有效控制权重方差,在保留大部分有效样本的同时抑制极端偏差的影响。
实验表明:
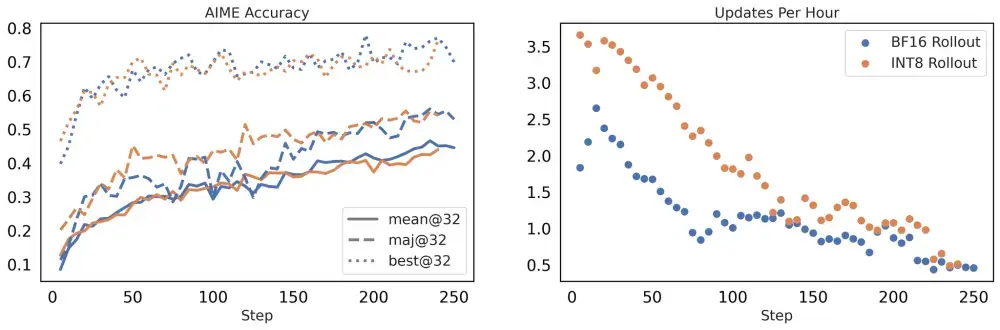
- 使用 TIS 后,INT8 量化的 rollout 训练性能可达到甚至超过 BF16 基线;
- 相比之下,未使用 TIS 的 BF16 训练反而表现更差。
图1 和 图2 显示:无论是否使用 TIS,BF16 与量化 rollout 的性能差距显著缩小,且 TIS 明显提升了量化路径的收敛稳定性。
这项技术使得“用低精度生成、高精度学习”成为可能,打破了精度与效率不可兼得的传统认知。
2. 在线量化支持:为 RL 定制的推理后端
现有推理框架(如 vLLM)主要面向静态服务场景,无法满足 RL 中频繁更新模型参数的需求。更重要的是,它们对量化模型的加载与执行支持有限。
为此,FlashRL 团队基于 vLLM 进行深度改造,推出了 Flash-LLM-RL 包,实现了:
- 动态模型更新:支持在 rollout 过程中热加载最新训练权重;
- 全流程量化支持:从权重加载到推理执行,完整支持 INT8/FP8;
- 高效内存管理:减少冗余拷贝,提升多轮 rollout 的连续吞吐。
这意味着,你不再需要在“高性能推理”和“可训练性”之间做取舍。
实际加速效果:从吞吐量到端到端训练
我们从两个维度评估 FlashRL 的实际收益:rollout 吞吐提升 和 端到端训练效率改善。
一、rollout 吞吐量提升(常规设置)
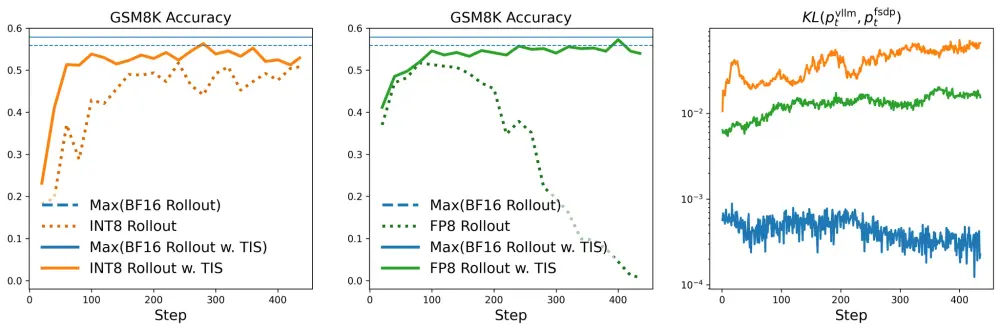
我们在 Deepseek-R1-Distill-Qwen 系列模型(7B、14B、32B)上测试了不同精度下的 rollout 吞吐量。
| 模型规模 | INT8 加速比 | FP8 加速比 |
|---|---|---|
| 7B | ~1.15x | ~1.20x |
| 14B | ~1.40x | ~1.45x |
| 32B | ~1.75x | ~1.65x |
注:加速比相对于 BF16 baseline
可以看到:
- 量化带来的收益随模型规模增大而提升;
- 对 32B 模型,INT8 实现近 1.75 倍加速;
- FP8 在分布对齐方面优于 INT8,但 INT8 更具挑战性和现实意义(硬件支持更广)。
📌 建议:仅当模型参数量超过 14B 时启用量化 rollout,小模型增益有限。
二、内存受限场景下的吞吐表现
在实际部署中,GPU 显存往往是瓶颈。我们进一步测试了在 A100、A6000 和 H100 上,使用 vLLM 服务 BF16 与 INT8 版本的 32B 模型时的极限吞吐。
结果表明:
- INT8 可在相同显存下容纳更多并发请求;
- 在 A100 上,INT8 吞吐提升约 1.6 倍;
- H100 因原生支持 FP8,潜力更大,未来可通过 FP8 进一步优化。
这说明 FlashRL 不仅适用于训练加速,也能用于资源受限环境下的高效推理服务。
三、端到端训练效果验证
我们使用 FlashRL 训练 DAPO-32B 模型,并对比 BF16 与 INT8 rollout 的训练轨迹。
关键发现:
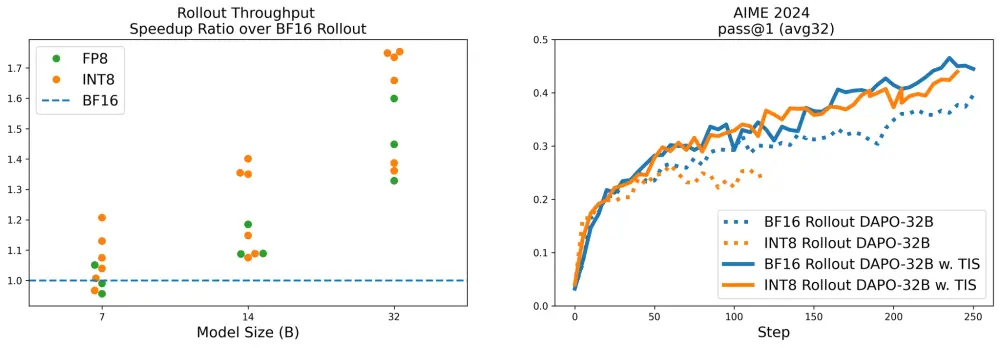
- 训练速度:INT8 rollout 缩短了 40% 的 rollout 时间;
- 下游性能:在 AIME 基准测试中,两者最终准确率几乎一致;
- 稳定性:引入 TIS 后,INT8 路径的训练曲线更加平滑。
图4 显示:INT8 + TIS 的组合不仅没有损失性能,反而因更高的采样频率带来了更稳定的优化过程。
这意味着:你可以用更低的成本,完成同样甚至更好的训练结果。
总结:让强化学习训练更快、更轻、更实用
FlashRL 的核心贡献在于:
- 首次实现可在真实 RL 训练中使用的量化 rollout 方案;
- 提出 TIS 技术桥接精度鸿沟,保障性能不下降;
- 构建支持在线更新的量化推理后端,填补工具链空白;
- 开源可用,开箱即用,适配主流硬件。
对于正在开展大模型 RL 训练的团队来说,FlashRL 是一个值得尝试的性能增强组件。尤其在 14B 以上模型上,量化 rollout 能带来显著的时间与资源节省。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











