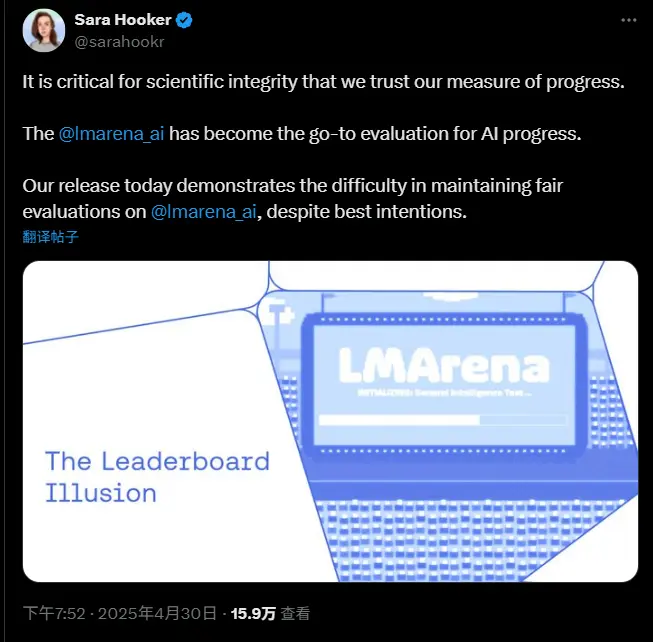
一项由 Cohere、斯坦福大学、麻省理工学院和 Ai2 研究人员联合发布的新研究,指责热门 AI 基准测试平台 LM Arena(Chatbot Arena 的背后组织)帮助少数顶级 AI 实验室通过私下测试和选择性公布结果,操控其排行榜排名。这一指控引发了对 AI 基准测试公正性和透明性的广泛讨论。
LM Arena 的运作机制与争议背景
Chatbot Arena 是一个众包的 AI 模型评估平台,最初由加州大学伯克利分校于 2023 年创建,旨在通过“模型对决”的方式(即用户投票选出更优的回答)来评估不同 AI 模型的性能。随着时间推移,它已成为许多 AI 公司展示模型能力的重要基准测试工具。
然而,这项新研究指出,LM Arena 在实际操作中并未完全遵循其声称的“公平和社区驱动”原则。研究人员发现,部分行业巨头(如 Meta、OpenAI 和谷歌)被允许私下测试多个模型变体,并选择性地只公开表现最佳的结果。这种做法被认为为这些公司提供了不公平的竞争优势。
核心指控:私下测试与选择性披露
根据研究,以下几点是 LM Arena 被指责的关键问题:
私下测试未公开模型 研究人员指出,Meta 在 Llama 4 发布前的 1 月至 3 月期间,在 Chatbot Arena 上测试了多达 27 个模型变体,但最终仅公开了一个表现最优的模型得分。这个模型在排行榜上获得了领先位置。 类似的情况也发生在其他顶级实验室,例如 OpenAI 和谷歌,而小型实验室则没有这样的机会。
更高的采样率带来数据优势 研究人员分析了超过 280 万次 Chatbot Arena 的“战斗”,发现某些公司的模型在平台上出现的频率远高于其他模型。这种高采样率使得这些模型能收集更多用户反馈数据,从而优化其表现。 数据显示,使用额外的 LM Arena 数据可以将模型在另一个基准测试(Arena Hard)上的性能提升高达 112%。
缺乏透明度 研究人员批评 LM Arena 对哪些模型正在接受测试以及为何某些结果未被公开缺乏透明度。此外,他们还质疑 LM Arena 是否对所有参与者一视同仁。
LM Arena 的回应
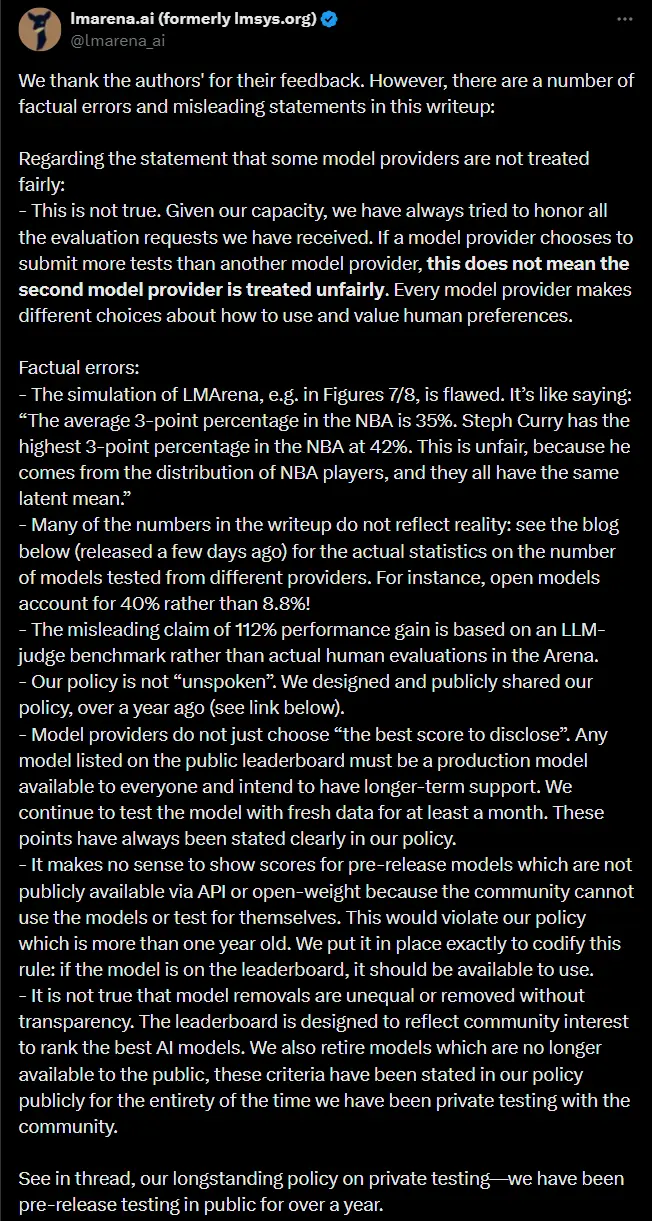
面对这些指控,LM Arena 及其联合创始人 Ion Stoica 迅速作出回应。Stoica 表示,该研究包含“不准确之处”和“有问题的分析”。LM Arena 在一份声明中强调了以下几点:
否认偏袒:LM Arena 称,任何一家公司都可以提交更多的模型进行测试,这并不构成不公平对待。如果某些公司选择提交更多模型,则是它们自己的策略问题。 预发布测试的必要性:LM Arena 指出,自 2024 年 3 月以来,已开始公开有关预发布测试的信息,并认为展示尚未发布的模型得分没有意义,因为 AI 社区无法独立验证这些模型。 改进采样算法:针对研究提出的建议之一——调整采样率以确保所有模型获得相等的机会,LM Arena 表示接受,并计划开发新的采样算法。
研究方法的局限性
尽管研究揭示了潜在的问题,但其方法论也存在一些局限性:
依赖“自我识别”分类:研究人员通过询问 AI 模型所属公司来确定其身份,这种方法可能存在误差。例如,模型可能错误报告或故意隐瞒真实来源。 样本量偏差:尽管研究涵盖了 280 万次战斗,但 LM Arena 强调,非主要实验室的模型实际上比研究显示的参与次数更多。
Meta 的案例:优化 vs. 透明性
研究特别提到了 Meta 在 Llama 4 发布期间的行为。据报道,Meta 优化了一个版本的 Llama 4 模型以提高“对话性”,使其在 Chatbot Arena 排行榜上表现优异。然而,Meta 最终并未发布该优化版本,而是推出了原始版本,后者的表现明显逊色。
这一事件进一步凸显了基准测试中的透明性问题。LM Arena 当时表示,Meta 应在基准测试方法上更加透明,但显然未能完全避免类似问题再次发生。
更大的问题:基准测试的可信度
随着 LM Arena 宣布成立公司并寻求外部融资,这一争议不可避免地引发了对私人基准测试组织的质疑。作为 AI 模型评估的核心工具,基准测试平台需要保持高度的中立性和透明性,才能赢得信任。
然而,当这些平台与企业利益交织时,如何确保其公正性成为一个难题。研究人员呼吁 LM Arena 采取以下措施:
限制私下测试数量:设置明确且透明的限制,规定每家公司可进行的私下测试次数,并公开所有测试结果。 增加透明度:公开所有参与测试的模型信息,包括未发布的预发布模型。 平等采样:确保每个模型在 Chatbot Arena 中的采样率相同,避免因高频曝光带来的数据优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











