逆势豪赌视频生成!当 OpenAI 退守企业市场,埃隆·马斯克的 xAI 全力投入AI视频生成在 AI 视频生成的赛道上,风向正在发生戏剧性的逆转。就在 OpenAI 因高昂的算力成本、用户留存率崩塌及法律风险,宣布关闭 Sora 独立应用并撤出消费者市场之际,埃隆·马斯克旗下的 xAI 却选...早报# OpenAI# xAI# 埃隆·马斯克1周前0250
GitHub 新增 AI 驱动的漏洞检测,扩大安全覆盖范围GitHub 正在重塑代码安全的边界。今日宣布,其代码安全工具套件将引入基于 AI 的漏洞扫描机制,作为对传统静态分析工具 CodeQL 的强大补充。这一举措旨在突破现有技术的局限,将安全覆盖范围扩展...早报# GitHub1周前080
拒绝“黑卡”与封号风险:安卓用户自助订阅 Claude/ChatGPT 终极指南在 AI 订阅费用日益高涨的今天($20/月约合人民币 145 元),“代充”服务看似诱人,实则暗藏杀机。从尼日利亚区低价账号的“运气博弈”,到虚拟卡退款导致的“秒封号”,再到黑卡礼品卡的“连坐风险...教程# ChatGPT# Claude1周前0760
Reddit 启动“人类验证”计划:可疑账户需自证清白,AI 生成内容仍被允许在 AI 智能体(Agent)即将席卷互联网的浪潮前,Reddit 率先筑起了一道防线。Reddit 首席执行官 Steve Huffman 今日正式宣布,平台将引入新的验证机制,要求表现出“自动化或...早报# Reddit2周前0160
华为小艺 Claw 正式开启预约:基于 OpenClaw 打造,内置四种人格的鸿蒙原生智能体华为正式面向 鸿蒙 OS 6 终端用户开启 小艺 Claw 的预约通道。这款全新的 AI 助理并非简单的功能升级,而是华为基于全球爆火的开源框架 OpenClaw 深度定制的原生智能体(Agent...早报# 华为# 小艺Claw2周前0340
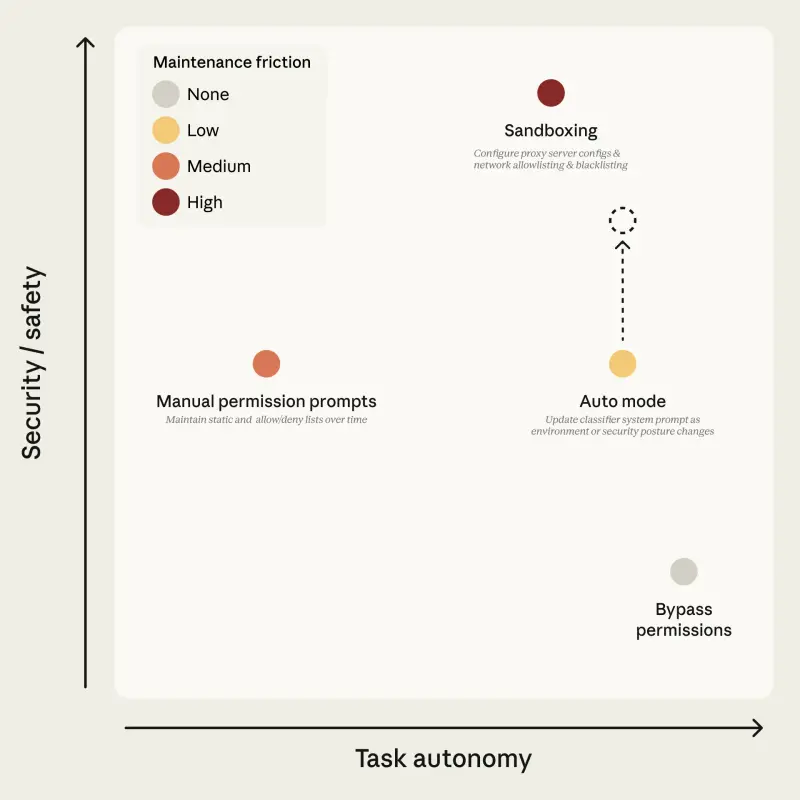
Claude Code 自动模式深度解析:用 AI 分类器终结“批准疲劳”,在安全与效率间寻找新平衡Claude Code 用户批准了 93% 的权限提示。我们构建了分类器来自动化部分决策,在提高安全性的同时减少批准疲劳。以下是它能捕捉和无法捕捉的内容。 默认情况下,Claude Code 在运行命...科普# Claude Code# 自动模式2周前060
Cloudflare 发布动态 Worker 加载器:AI 沙箱速度提升 100 倍,内存消耗骤降在 AI 智能体(Agent)深度融入软件开发流程的今天,如何既保证执行安全又实现极速响应,成为了开发者面临的核心挑战。Cloudflare 推出的动态 Worker 加载器 (Dynamic Wor...早报# Cloudflare# Worker 加载器2周前0160
迪士尼叫停 10 亿美元 OpenAI 合作:Sora 战略急转弯,IP 授权梦碎好莱坞与硅谷的一场世纪联姻尚未正式缔结便已宣告破裂。多家权威媒体报道证实,随着 OpenAI 突然宣布调整 Sora 视频生成业务的战略方向(包括关闭独立应用计划),其与 迪士尼 原计划达成的价值 1...早报# OpenAI# Sora# 迪士尼2周前0150
谷歌发布 Lyria 3 Pro:谷歌音乐生成迈入“完整曲目”时代,最长支持 3 分钟继上个月推出 Lyria 3 后,谷歌于本周三正式发布了其最新音乐生成模型 Lyria 3 Pro。这款升级版模型不仅将生成时长从 30 秒大幅延长至 3 分钟,更在音乐结构理解、创意控制和多平台集成...早报语音模型# Lyria 3 Pro# 谷歌2周前0330
英特尔“大号战斗法师”正式登场:Arc Pro B70/B65 发布,32GB 显存+367 TOPS 算力,剑指英伟达在等待了许久之后,英特尔终于在 2026 专业日 上揭开了代号为 “大号战斗法师” (Big Battlemage) 的神秘面纱。不过,这次亮相的并非游戏玩家期待的消费级显卡,而是两款专为 AI 推理...硬件# Arc Pro B65# Arc Pro B70# 英特尔2周前0170
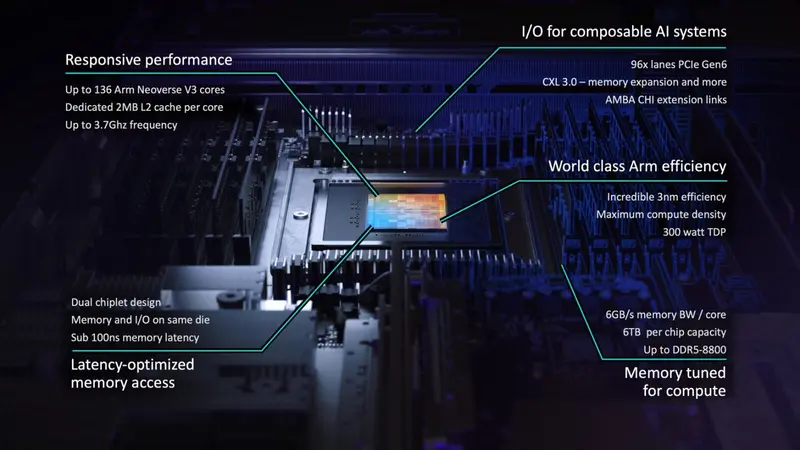
ARM 正式“下场”造芯:发布首款自研 AGI CPU,剑指英伟达与 x86 服务器霸权在长期扮演“幕后军师”(IP 授权商)的角色后,ARM 终于决定走到台前。在最新的 “ARM Everywhere” 主题演讲中,ARM 正式宣布推出其历史上第一款直接销售的硅片产品——ARM AGI...硬件# Arm2周前0260
紧急安全警报:LiteLLM 遭供应链攻击,v1.82.7/1.82.8 窃取凭证并植入后门【高危预警】 Python 热门库 LiteLLM 遭遇严重供应链攻击。黑客入侵维护者账号,向 PyPI 发布了包含恶意代码的版本 v1.82.7 和 v1.82.8。恶意软件旨在窃取 SSH 密钥...早报# LiteLLM2周前01430