阿里云JVS Claw全面开放!无需邀请码领云端龙虾,39元首月解锁深度体验3 月 25 日,阿里云正式宣布 JVS Claw结束内测,面向公众全面开放。即日起,用户无需任何邀请码,即可注册并获得属于自己的云端 AI 智能体。作为年轻人“养虾”的第一站,JVS Claw 在保...早报# JVS Claw# 阿里云2周前0440
突发!OpenAI宣布关闭Sora视频生成器,迪士尼10亿美元合作告吹OpenAI正式官宣,将关闭其备受关注的视频生成器Sora,这一举措正值该公司战略转向,计划重新聚焦商业和生产力应用场景之际,距离Sora 2024年底公开推出仅一年多时间,曾经惊艳行业的AI视频标杆...早报# OpenAI# Sora2周前0120
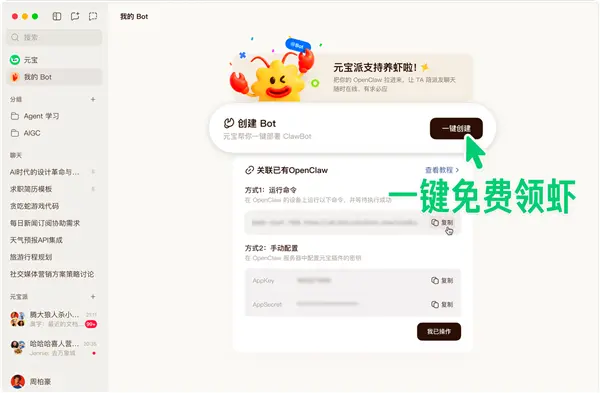
腾讯元宝派电脑版正式上线!一键创建免费龙虾,多端同步+办公功能拉满腾讯旗下AI助手元宝正式官宣,元宝派电脑版全面上线。用户只需将元宝电脑版升级至最新版本,即可在侧边栏找到元宝派入口,解锁多端协同、办公高效操作、龙虾智能体调用等一站式功能,进一步完善AI社交与办公协同...早报# 元宝派# 腾讯2周前0100
Claude Code 上线自动模式:告别“连环确认”,让 AI 安全地“自动驾驶”对于重度使用 Claude Code 的开发者来说,最打断心流的时刻莫过于:当你启动一个复杂的重构任务,准备去倒杯咖啡时,AI 却因为你没点击“允许”而停在原地。以前,你只有两个选择:要么忍受频繁的人...早报# Claude Code# 自动模式2周前01220
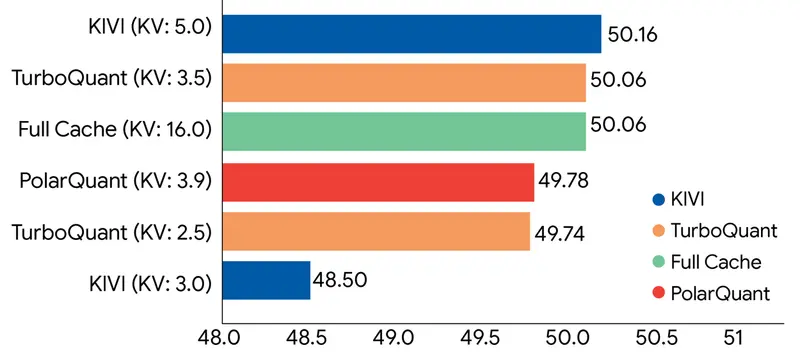
TurboQuant:谷歌新算法实现零精度损失压缩,KV Cache 内存缩减 6 倍在大型语言模型(LLM)向更长上下文、更复杂任务演进的过程中,显存瓶颈已成为制约效率的关键障碍。尤其是键值缓存(KV Cache),随着序列长度增加呈线性增长,不仅占用大量显存,还限制了推理速度和并发...新技术# KV Cache# TurboQuant# 谷歌2周前0560
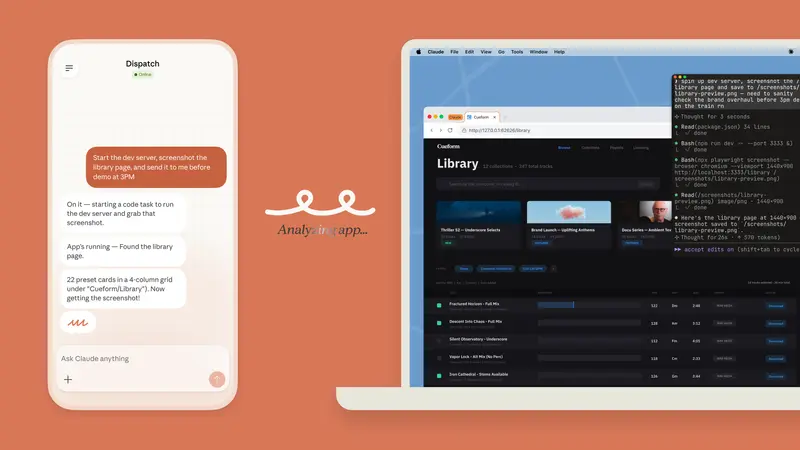
OpenAI 推出 ChatGPT“图书馆”:个人文件的云端永久仓库,删除对话也不丢数据OpenAI 为 ChatGPT 引入了一项名为 “图书馆” (Library) 的全新功能,旨在解决用户在多轮对话中文件管理混乱、历史资料难以复用的痛点。该功能允许 Plus、Pro 及 Busin...早报# ChatGPT# OpenAI2周前0860
Anthropic 重磅更新:Claude 现已能“接管”Mac,自主执行任务并支持手机远程指派AI 智能体的进化迎来了里程碑式的一刻。Anthropic 正式宣布,其旗舰模型 Claude 现在可以通过 Claude Cowork 和 Claude Code 直接控制 macOS 电脑,像人类...早报# Anthropic# Claude# Claude Code2周前0200
PaCo-RL:西安交大首创“一致性裁判”强化学习框架,让AI生成四张图也能保持角色与风格完美统你是否曾有过这样的经历:想让AI画一组连环画,比如“一只狐狸在森林、舞台、海边、卧室弹吉他”,结果AI生成的四张图里,狐狸变成了四种不同的动物,吉他变了样,画风也从油画突变成了水彩? 这就是AI绘画领...新技术# PaCo-RL2周前0860
阿里玄铁C950刷新全球RISC-V性能纪录:5nm工艺、3.2GHz主频,专为AI Agent时代打造在RISC-V架构迈向高性能计算的关键节点,阿里巴巴达摩院今日正式发布最新一代旗舰CPU——玄铁C950。这款采用5nm先进工艺(由台积电生产)的处理器,不仅刷新了全球RISC-V性能纪录,更标志着R...硬件# 玄铁C950# 阿里2周前0560
谷歌 Gemini 深入暗网:以 98% 准确率每日筛查千万条威胁情报在网络安全领域,误报(False Positives)一直是困扰安全运营中心(SOC)的头号难题。传统的暗网监控工具往往产生海量噪音,让分析师疲于奔命。如今,谷歌宣布其 Gemini AI 智能体已正...早报# Gemini# 谷歌2周前0140
OpenAI 启动史上最大规模扩张:员工翻倍至 8000 人,全面押注企业 AI 市场在人工智能竞争进入“深水区”的 2026 年,OpenAI 正酝酿其成立以来的最大变革。据《金融时报》报道,这家估值高达 7300 亿美元 的巨头计划在今年年底前将员工人数从目前的约 4500 人激增...早报# OpenAI2周前0120
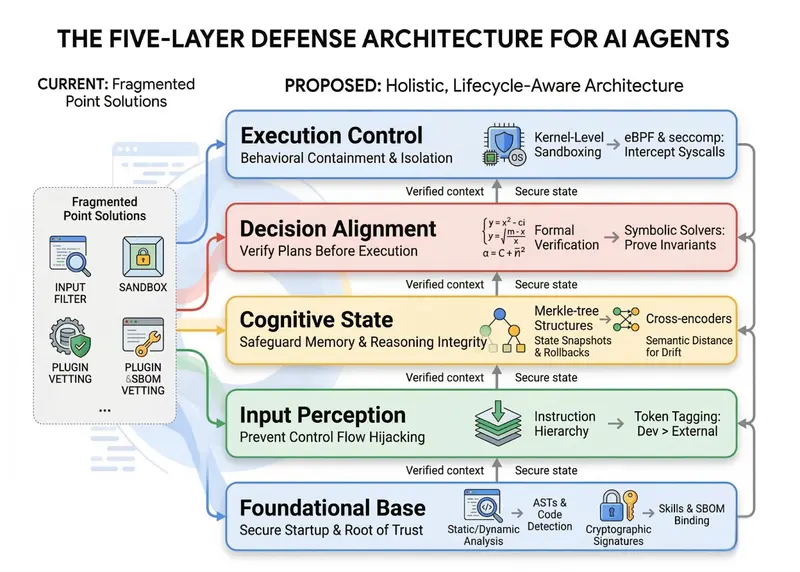
清华与蚂蚁发布 OpenClaw 五层安全框架:揭示技能投毒与内存污染风险,构建全生命周期纵深防御随着 OpenClaw 等自主 LLM 智能体从“被动问答”进化为能执行高权限系统任务的“主动实体”,其面临的安全挑战也发生了质变。 论文地址:https://arxiv.org/pdf/2603.1...新技术# OpenClaw2周前0180