在长期扮演“幕后军师”(IP 授权商)的角色后,ARM 终于决定走到台前。在最新的 “ARM Everywhere” 主题演讲中,ARM 正式宣布推出其历史上第一款直接销售的硅片产品——ARM AGI CPU。
这一举动标志着 ARM 商业模式的重大转折:从单纯的技术授权商,转型为端到端的硅片制造商。其目标非常明确:利用智能体(Agent)AI 工作负载爆发的契机,打破英伟达(NVIDIA)和 x86 阵营在高端服务器领域的垄断,成为下一代 AI 基础设施的核心玩家。
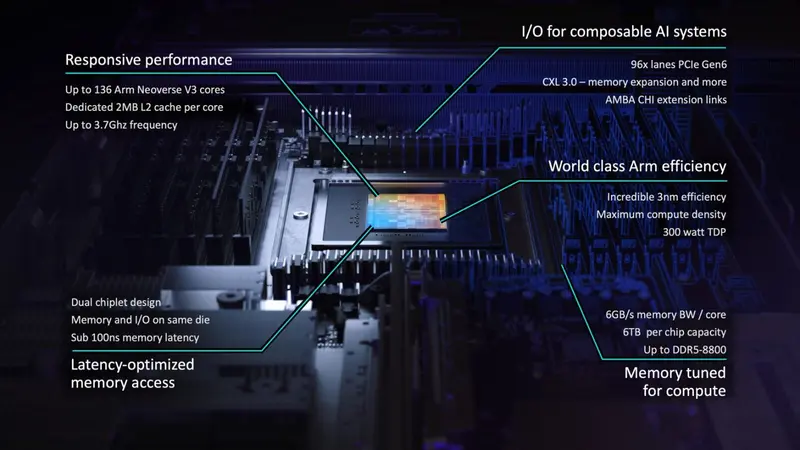
核心规格:为“智能体 AI”量身打造
这款 ARM AGI CPU 并非普通的服务器芯片,而是专为高并发、低延迟的 Agent AI 场景设计。其参数令人咋舌,直接对标甚至超越了当前的顶级服务器处理器:
| 关键指标 | 规格详情 | 解读 |
|---|---|---|
| 核心架构 | Arm Neoverse V3 | ARM 目前最强的服务器核心,专为高性能计算设计。 |
| 核心数量 | 136 核 (单芯片) | 双芯片封装下,单节点可达 272 核,机架级高达 8160 核。 |
| 时钟频率 | 3.7 GHz | 在如此多核心下保持高频,确保单线程响应速度。 |
| 缓存系统 | 2MB L2 / 核心 | 总计 272MB L2 缓存,大幅减少内存访问延迟。 |
| 制造工艺 | 3nm | 采用最先进的制程,平衡性能与功耗。 |
| 内存带宽 | 6GB/s / 核心 | 总带宽惊人,支持 DDR5-8800,单芯片支持 6TB 内存。 |
| I/O 能力 | 96 条 PCIe Gen 6 | 为连接 GPU、高速网卡和存储提供极致吞吐。 |
| 互连技术 | CXL 3.0 + AMBA CHI | 支持内存池化和大规模集群扩展。 |
| 功耗 (TDP) | 300W | 在提供顶级性能的同时,保持了 ARM 传统的高能效比。 |
机架级革命:重新定义数据中心密度
ARM 不仅卖芯片,还推出了完整的机架级解决方案,直接挑战传统服务器形态:
- 1OU 超薄节点:采用创新的刀片式设计,一个机箱可容纳两个节点(共 272 核)。
- 高密度部署:一个标准机架可容纳 30 个节点,总算力高达 8160 个核心。
- 统一内存池:通过 CXL 3.0 互联,整个机架共享巨大的内存资源,完美适配需要海量上下文窗口的 Agent AI 任务。
- 能效优势:整个机架额定功率仅 36kW(风冷),相比同等算力的 x86 或 GPU 方案,能效比显著提升。

战略意图:终结英伟达的“独家优势”?
ARM 此举最深远的影响在于生态格局的重塑:
- 直面英伟达:此前,英伟达基于 ARM 架构推出的 Grace (Vera) 芯片享有独特的优化优势。如今 ARM 亲自下场,意味着所有服务器厂商(如戴尔、惠普、超微等)都能获得与英伟达同源的顶级 CPU,英伟达在 ARM 服务器核心的“独家特权”宣告终结。
- 碾压 x86:ARM 声称,其 AGI CPU 方案的每机架性能是现代 x86 解决方案的两倍。在 AI 推理和 Agent 编排这种对并发和能效极度敏感的场景下,ARM 架构的优势将被无限放大。
- 开放生态:ARM 明确表示支持任何符合 OCP (开放计算项目) 标准的加速器。这意味着客户可以自由搭配 NVIDIA、AMD 或其他厂商的 GPU/TPU,不再被绑定在特定的私有生态中。
行业影响:AI 基础设施的“去中心化”
ARM CEO Rene Haas 表示:“这是 Arm 计算平台的下一阶段……我们为合作伙伴提供了更多选择。”
- 对于云厂商:AWS、Google、Microsoft 等巨头将拥有一个强大的“公版”高性能 CPU 选项,减少了对英特尔、AMD 甚至英伟达定制芯片的依赖。
- 对于 AI 开发者:更低的延迟、更高的并发能力和更低的成本,将使部署大规模 Agent 集群 变得前所未有的容易。
- 对于英特尔/AMD:压力倍增。x86 架构在能效比和核心密度上的劣势在 AI 时代被进一步放大,必须加速迭代以应对 ARM 的正面冲击。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











