OpenAI 澄清:ChatGPT 的“Peloton 推荐”不是广告,而是未优化的功能近日,一张 ChatGPT 在无关对话中弹出“寻找健身课程 › 连接 Peloton”提示的截图在社交平台广泛传播,引发大量用户担忧:ChatGPT 是否已开始向免费甚至付费用户展示广告? 尤其令 P...早报# OpenAI# 广告3个月前0190
Anthropic 或抢先 OpenAI 上市,有望获得资金优势AI领域 OpenAI 的主要竞争对手之一是拥有 Claude 系列模型的 Anthropic。目前有传言称,Anthropic 已启动早期筹备,最早可能于明年启动首次公开募股,并有望成为规模最大的 ...早报# Anthropic# OpenAI# 上市3个月前0200
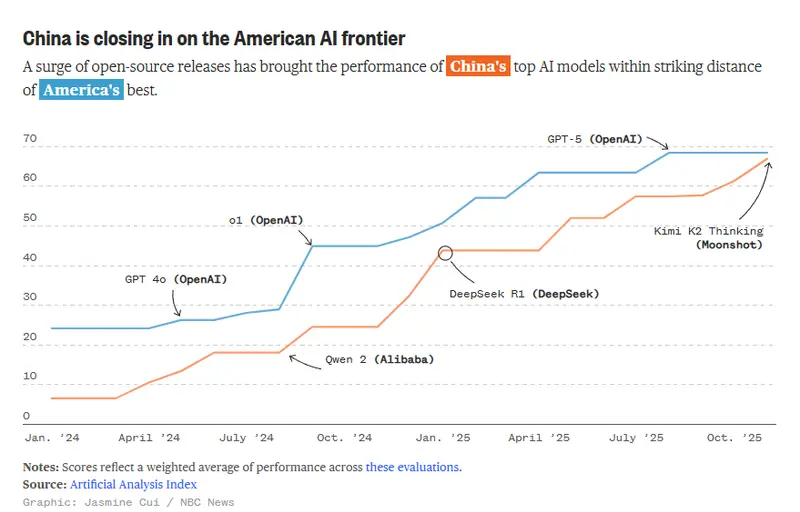
越来越多的硅谷公司正在基于免费的中国AI模型进行构建AI初创企业的估值屡创新高,但许多企业是建立在廉价、可免费下载的中国AI模型基础之上的。 今年早些时候,在审视美国AI领域的状况时,Misha Laskin 感到担忧。 Laskin 是一位理论物理学...科普# AI模型# 中国# 硅谷3个月前0640
DeepSeek V3.2正式发布:推理能力追平GPT-5,首个思考+工具调用开源模型经过两个多月测试,DeepSeek 正式推出 V3.2 系列模型,包括平衡型主力版本 DeepSeek V3.2 与极致推理增强版 DeepSeek V3.2 Speciale。前者以“推理能力不逊 ...大语言模型早报# DeepSeek V3.23个月前02160
可灵 AI 发布 O1 视频模型:统一架构支持多模态视频生成可灵 AI正式推出 O1 视频模型,并同步上线新版创作界面。该模型采用统一的生成式架构,旨在解决当前 AI 视频工具中常见的“功能割裂”问题——即文生视频、图生视频、编辑、补全等任务需依赖多个独立模型...早报# O1 视频模型# 可灵 AI3个月前0470
Vidu Q2 上线:聚焦图像生成一致性与编辑实用性,开启限免一个月活动近日,国产 AI 视频生成平台 Vidu 推出 Q2 版本,重点强化了参考生图的一致性与图像编辑的实用性。作为成立仅两年多的初创团队,Vidu 在最新Artificial Analysis榜单中,其图...早报# Vidu Q23个月前0980
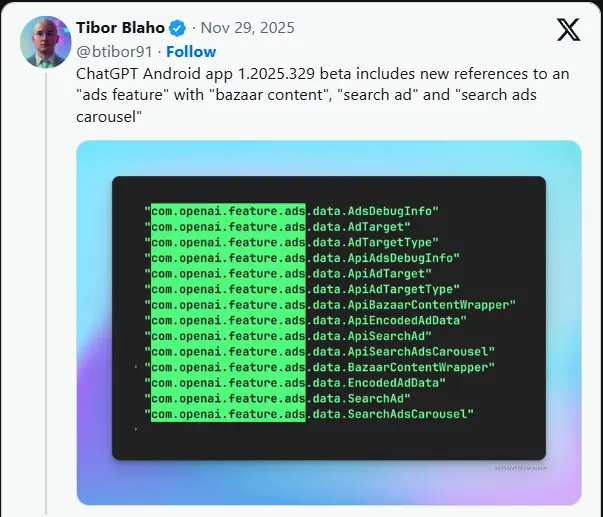
OpenAI 测试版代码现广告痕迹,ChatGPT 免费用户或见广告尽管 ChatGPT 拥有约 8亿周活跃用户,其中 95% 使用免费版本,OpenAI 始终未在其聊天界面中植入广告。但最新证据显示,这一策略可能即将改变。 开发者蒂博尔·布拉霍(Tibor Blah...早报# OpenAI# 广告3个月前0820
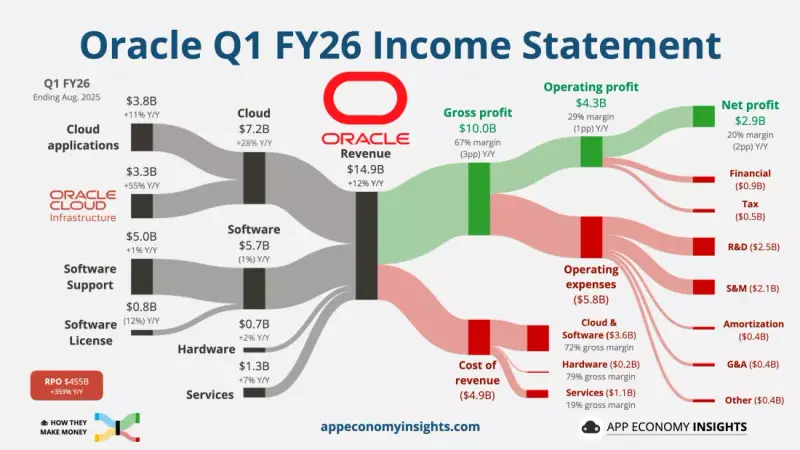
180亿债券+560亿贷款!甲骨文AI扩张引华尔街担忧,信用风险升至三年新高甲骨文正因大举投入人工智能基础设施而面临日益严峻的信用压力。一项关键风险指标——五年期信用违约互换(CDS)成本——已攀升至125个基点,创下2022年以来新高。这意味着投资者为对冲每100万美元甲骨...早报# 华尔街# 摩根士丹利# 甲骨文3个月前0230
Runway推出全新视频生成模型Gen-4.5:1247 Elo分刷新视频生成纪录,物理级运动保真+复杂指令精准执行Runway 推出的全新视频生成模型 Gen-4.5(曾用代号 Whisper Thunder/David),凭借在预训练数据效率、后训练技术上的重大突破,以 1247 Elo 分登顶 Artific...早报# Gen-4.5# Runway3个月前01690
如何使用 Nano Banana Pro 创作图像与视频:完整工作流指南如今创作专业视频不再需要昂贵设备或多年技术经验。借助 Nano Banana 2 等AI工具,任何人都能将创意转化为惊艳的视觉内容。本指南将带您了解结合AI图像生成与视频转换技术的高效工作流,助您在3...早报# Nano Banana Pro4个月前0980
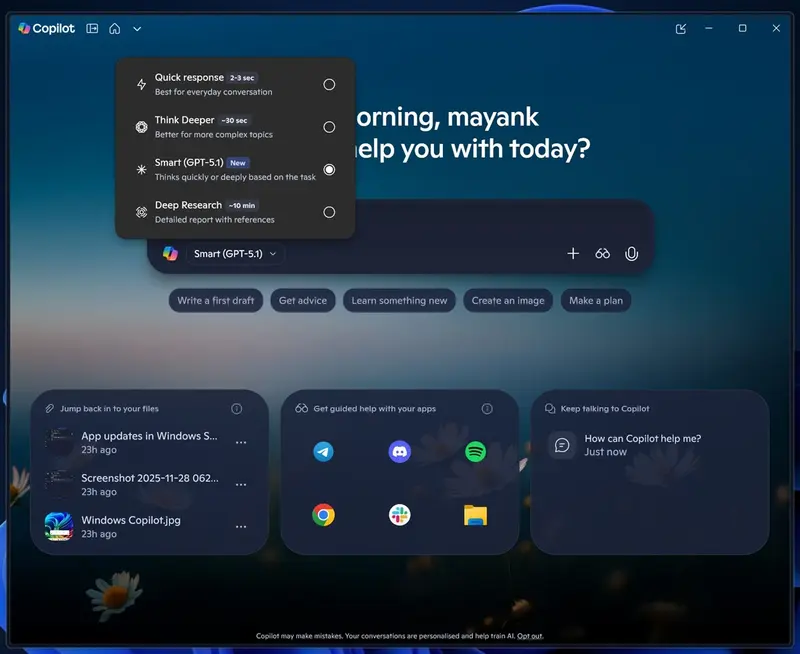
Windows 11 Copilot 开始灰度推送 GPT-5.1,实验室功能同步上线OpenAI在2025年11月12日正式发布GPT-5.1后,作为其大股东的微软迅速跟进——开始向Windows 11平台的Copilot用户分阶段推送这一最新模型,且未付费订阅微软AI服务的普通用户...早报# Copilot# GPT-5.1# Windows 114个月前0280
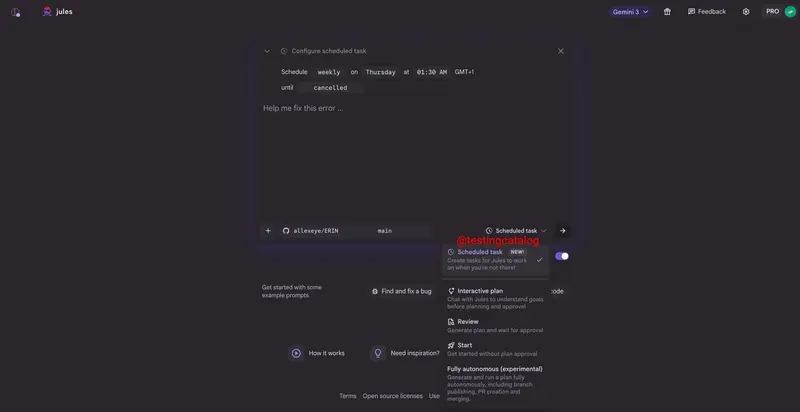
谷歌 Jules 智能体将支持定时任务与主动代码监控,迈向自主开发助手谷歌正为其 AI 编程助手 Jules 引入两项关键能力:定时任务 与 主动代码监控模式。这标志着 Jules 从“被动响应指令”向“主动维护项目”迈出关键一步,目标是成为支持手动与自主双模式的工程助...早报# Jules 智能体# 谷歌4个月前0480