新型图像编辑方法Guide-and-Rescale:能够在不破坏原始图像的基础上,对真实的照片进行各种编辑俄罗斯高等经济大学、斯科尔科沃科学技术研究所 和新南威尔士大学悉尼分校的研究人员推出新的图像编辑方法Guide-and-Rescale,此方法的核心是能够在不破坏原始图像的基础上,对真实的照片进行各种...新技术# Guide-and-Rescale# 图像编辑2年前07260
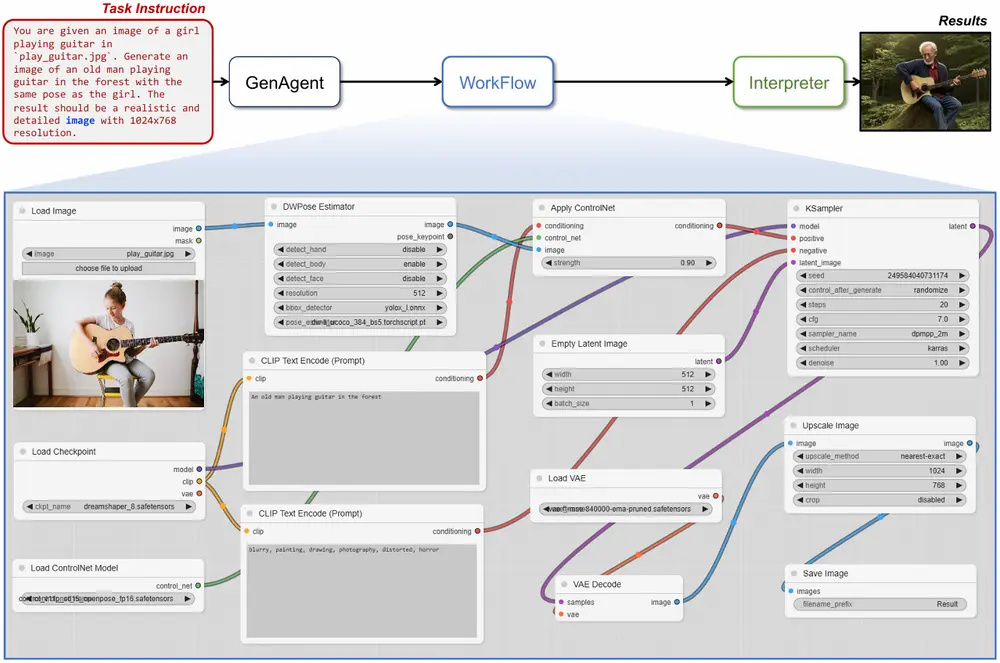
基于大语言模型的框架GenAgent:用于自动生成复杂的工作流程,以构建协作式人工智能系统上海人工智能实验室推出一个基于大语言模型的框架GenAgent,用于自动生成复杂的工作流程,以构建协作式人工智能(AI)系统,相比单一的大型模型,GenAgent提供了更大的灵活性和可扩展性。这种系统...新技术# GenAgent2年前01,0800
字节跳动推出基于音频驱动人物肖像新框架Loopy:专门用于生成与音频同步的逼真人像视频字节跳动和浙江大学的研究人员推出新型人工智能模型Loopy,它专门用于生成与音频同步的逼真人像视频。Loopy的核心特点是完全基于音频信号来驱动人像动作,而不需要额外的空间信号来辅助控制动作,这使得生...新技术# Loopy# 人物# 字节跳动2年前06410
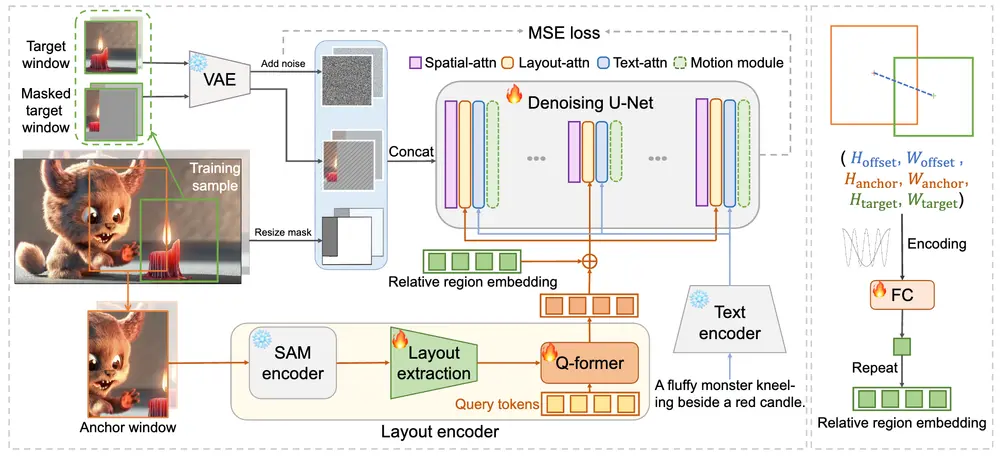
无需训练的图像编辑技术DiffUHaul:专门用于在图像中无缝移动物体英伟达研究中心、耶路撒冷希伯来大学、特拉维夫大学和赖希曼大学的研究人员推出一种无需训练的图像编辑技术DiffUHaul,专门用于在图像中无缝移动物体。例如,你有一张图片,里面有一只猫和一块岩石,你想要...新技术# DiffUHaul# 图像编辑2年前06870
新型视频扩展方法Follow-Your-Canvas:能够将现有视频的内容扩展到更高的分辨率,并在扩展区域生成丰富的新内容腾讯混元、香港科技大学、中国科学技术大学和清华大学的研究人员推出新型视频扩展方法Follow-Your-Canvas,它能够将现有视频的内容扩展到更高的分辨率,并在扩展区域生成丰富的新内容。这种方法特...新技术# Follow-Your-Canvas# 视频扩展2年前05170
新型SD模型压缩方法VQDM:通过向量量化技术,能够将大型的文本到图像扩散模型压缩到较低比特位表示,同时保持图像生成的高质量Yandex 研究、HSE 大学、Skoltech、MIPT、Neural Magic和IST 奥地利的研究人员推出新型文本到图像扩散模型压缩方法VQDM,通过向量量化(Vector Quantiza...新技术# VQDM# 模型压缩2年前07190
新型图像生成蒸馏模型LinFusion:利用文本提示生成高分辨率的图像新加坡国立大学学习与视觉实验室的研究人员推出新型图像生成模型LinFusion,它能够利用文本提示生成高分辨率的图像。LinFusion的核心在于它采用了一种新颖的线性注意力机制,这使得它在处理大量像...新技术# LinFusion# 蒸馏模型2年前08290
新型视频深度估计方法DepthCrafter:为开放世界(即不受限制、多样化的现实世界场景)的视频生成时间上连贯、细节丰富的深度序列腾讯人工智能实验室、香港科技大学和腾讯 PCG ARC 实验室的研究人员推出新型视频深度估计方法DepthCrafter,能够为开放世界(即不受限制、多样化的现实世界场景)的视频生成时间上连贯、细节丰...新技术# DepthCrafter# 视频深度估计2年前08380
不需要额外的训练!用于个性化调整扩散模型的新方法RB-Modulation德克萨斯大学奥斯汀分校、谷歌和谷歌 DeepMind的研究人员推出一种用于个性化调整扩散模型的新方法RB-Modulation,RB-Modulation 建立在一个新颖的随机最优控制器基础上,其中样...新技术# RB-Modulation2年前04120
适用于 DiTs 模型的快速后训练向量量化方法 VQ4DiT:能够在各种资源受限的环境中高效运行,同时保持生成图像的质量。浙江大学和vivo的研究人员推出一种适用于 DiTs 的快速后训练向量量化方法 VQ4DiT,它是一种针对扩散变换器模型(Diffusion Transformers,简称DiTs)的高效后训练矢量化...新技术# DiTs 模型# VQ4DiT2年前07790
CoRe:用于文本到图像个性化的上下文正则化文本嵌入学习中山大学和香港理工大学的研究人员推出文本对齐新技术CoRe,它用于提升文本到图像个性化生成的效果。简单来说,CoRe技术可以帮助人工智能系统更好地理解用户通过文本提供的概念,并生成与这些概念和文本描述...新技术# CoRe2年前04490
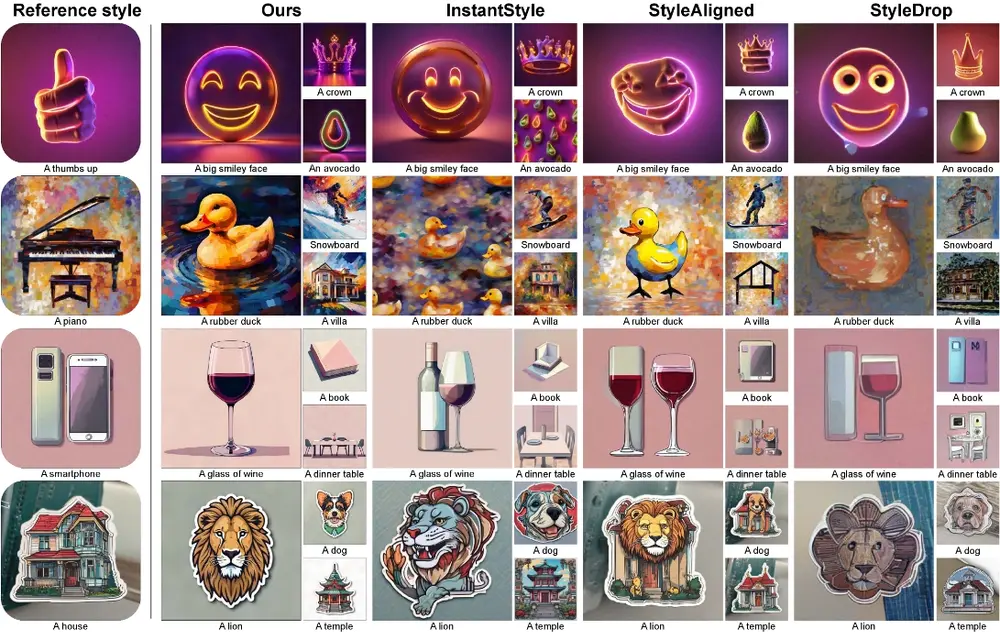
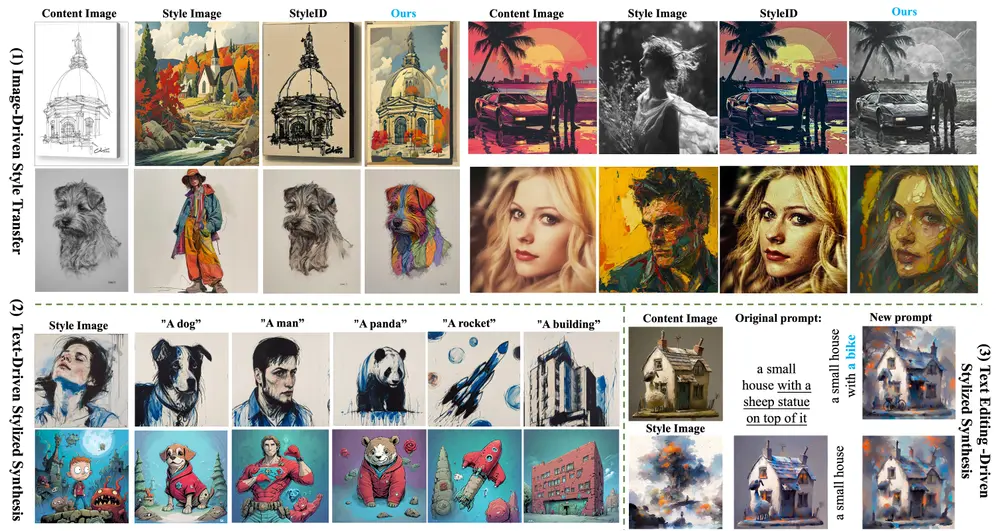
基于端到端训练的风格迁移模型CSGO:根据用户提供的文本描述和风格图像,生成具有特定风格的内容图像InstantX Team、南京理工大学、北京航空航天大学和北京大学的研究人员推出一种基于端到端训练的风格迁移模型CSGO,它是一个用于文本到图像生成的风格迁移模型。简单来说,CSGO能够根据用户提供...新技术# CSGO# 风格迁移模型2年前06470