微软发布 Phi 系列两款新模型:Phi-4-multimodal 和 Phi-4-mini微软在今天宣布推出 Phi 系列小型语言模型(SLM)的两款新成员——Phi-4-multimodal 和 Phi-4-mini。这两款模型旨在为开发者提供更强大的 AI 功能,分别在多模态处理和文本...大语言模型# Phi-4-mini# Phi-4-multimodal# 微软1年前04510
浏览器正在被AI重写!2025年值得尝试的AI浏览器大盘点2025年,浏览器再次成为AI厂商争夺的核心入口。从Perplexity、Opera到微软和谷歌,几乎所有主流玩家都在将AI深度集成进浏览器——不是简单加个侧边栏,而是让浏览器真正理解你、替你行动。 ...AI合集# AI浏览器# Comet# Dia6个月前04440
微软推出 Copilot 3D 实验功能,瞄准创意与设计领域微软正在不断拓展其 AI 助手 Copilot 的能力边界,最新动向显示,他们正开发一项名为 Copilot 3D 的实验性功能,旨在帮助用户基于图片生成 3D 模型。这一进展表明,微软正将 Copi...早报# Copilot 3D# 微软9个月前04190
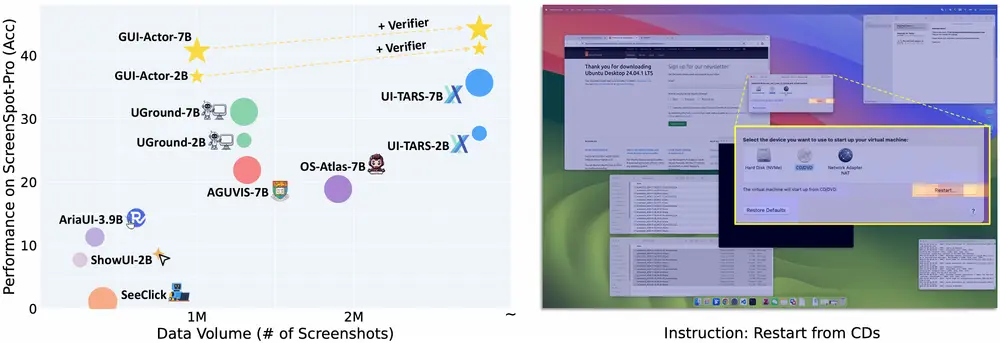
微软提出 GUI-Actor:基于视觉语言模型的无坐标 GUI 定位新范式在构建基于视觉语言模型(VLM)的 GUI 代理系统中,一个关键挑战是如何准确理解屏幕上的视觉内容并定位应执行操作的区域。传统方法通常将此问题建模为“文本到坐标的生成”任务,即通过语言描述预测具体像素...多模态模型# GUI-Actor# 微软10个月前04040
微软推出“Windows AI Labs”:画图应用将成 AI 新功能试验田近日,有用户在打开 Windows 11 版 Microsoft画图 时,意外收到一则弹窗邀请: “在画图中尝试实验性 AI 功能:注册 Windows AI Labs 计划。” 这并非普通更新提示...早报# Windows AI Labs# 微软# 画图6个月前04000
微软Copilot Search上线,挑战谷歌搜索模式,引入 AI 互动助用户延伸搜索在搜索引擎领域,AI技术正逐渐成为提升用户体验的关键。继谷歌上个月推出AI模式实验后,微软也迅速跟进,推出了Bing Copilot Search,正式向谷歌发起挑战。 谷歌的AI搜索模式 谷歌的AI...早报# Copilot Search# 微软# 谷歌1年前04000
微软 Copilot Think Deeper 功能升级:由OpenAI 的 o3-mini-high 模型驱动,无限制免费用微软近日宣布,其 Copilot 的 Think Deeper 功能已升级,现采用 OpenAI 的 o3-mini-high 模型。这一升级不仅提升了功能的效率和反应速度,还为所有用户带来了免费且无...早报# Copilot# o3-mini-high# OpenAI1年前03930
微软推出NLWeb:让每个网站都能拥有AI驱动的自然语言界面在2025年Build大会上,微软宣布推出一个名为 NLWeb 的开放项目,旨在简化为网页创建自然语言界面的过程。这一技术使任何网站都能轻松转变为人工智能驱动的应用程序,用户可以通过简单的对话界面(即...早报# NLWeb# 微软11个月前03900
微软Copilot升级:Agent Actions测试与原生图像生成功能上线微软正在悄然推进其AI助手Copilot的功能扩展,不仅新增了由OpenAI GPT-4o模型驱动的原生图像生成功能,还开始测试一项名为“Agent Actions”的隐藏功能。这些更新展示了微软在生...早报# Agent Actions# Copilot# 原生图像生成11个月前03820
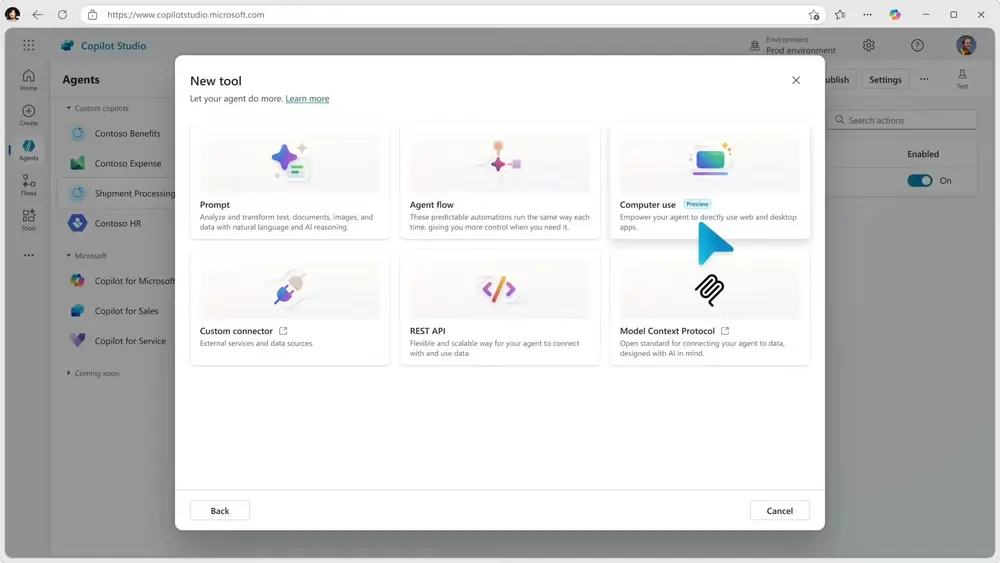
微软Copilot Studio 上线“计算机使用”功能,让AI智能体直接与网站和桌面应用互动4月15日,微软公司发布博文,宣布上线“计算机使用(Computer Use)”功能,这一新功能让Copilot Studio AI智能体能够直接与网站和桌面应用程序进行互动。这标志着自动化技术在企业...早报# Computer Use# Copilot Studio# 微软12个月前03810
微软 Copilot 或已免费上线 ChatGPT 的 o4-mini-high 模型?微软 Copilot 虽然在用户认知中不如 ChatGPT 那么热门,但它一直在悄悄提供一些原本需要付费才能使用的 GPT 功能。最近有用户测试发现,Copilot 的“Think Deeper”功能...早报# Copilot# o4-mini-high# 微软9个月前03730
微软将AI功能扩展至配备英特尔和AMD处理器的Copilot+ PC微软正加速推进其AI技术在更广泛设备上的应用,特别是针对配备英特尔和AMD处理器的Copilot+ PC。这次更新最引人注目的是实时字幕功能的全面开放,该功能支持将音频实时翻译为英语字幕,覆盖了数十种...早报# AMD# Copilot+PC# 微软1年前03700