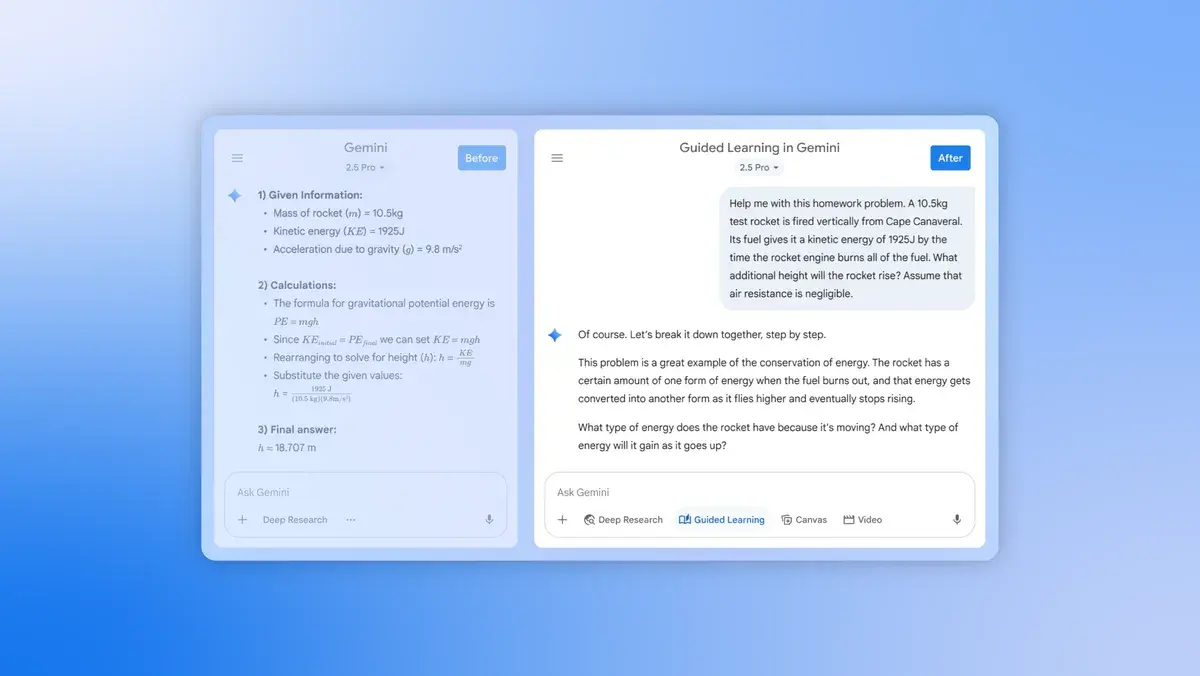
Character.AI 近日又有了新动作,推出了一款名为 AvatarFX 的 AI 视频生成工具。这款工具的出现,让静态图像也能“活”起来,为用户带来了全新的交互体验。
AvatarFX 的核心功能是将静态图像转化为动态角色。用户只需上传一张图片并选择对应的声音,就能生成会说话、能移动且富有情感的动态头像。这项技术基于先进的“基于 SOTA DiT 的扩散视频生成模型”,经过精心策划的数据训练,并结合特定的音频条件和高效生成技术进行优化。它能够以惊人的速度创建高保真、时间上连贯的视频,即使是较长的序列,甚至包含多个说话者和多次对话轮流,也能轻松应对。
在竞争激烈的视频生成领域,AvatarFX 以其独特的定位脱颖而出。与 OpenAI 的 Sora 和 Google 的 Veo 等竞争对手不同,AvatarFX 专注于将用户上传的图像转化为动画,而非完全从零开始或从文本生成视频。这不仅为用户提供了更大的创作自由度,也带来了一系列独特的可能性和潜在挑战。例如,用户可以上传真实人物的照片,生成看似逼真的视频,描绘他们说或做一些虚构的事情。这种技术被滥用的潜力不容忽视,但 Character.AI 已经采取了一系列措施来确保其安全性和合规性。
AvatarFX 的强大功能不仅体现在其生成的视频质量和多样性上,还在于它对各种风格和场景的适应能力。从逼真的角色到神话生物,甚至是有面孔的无生命物体,该模型都能表现出色。其数据专家构建了一个复杂的数据流程,专注于策划多样化的视频风格,过滤掉低质量的视频数据,并选择具有不同运动和美学水平的视频,最终获得一个强大的数据集,将模型的生成能力提升到一个新的水平。在音频方面,Character.AI 专有的 TTS 语音模型也为视频的真实感提供了有力支持。
为了确保生成过程的成本和时间效率,AvatarFX 利用了最先进的蒸馏技术来减少扩散步骤的数量,从而在几乎不降低质量的情况下显著加速推理。这一技术的突破,使得生成高质量视频变得轻松且高效。
AvatarFX 在多个方面突破了现有技术的界限:
- 它可以生成高质量的 2D 动画角色、3D 卡通角色和非人类面孔(比如宠物)的视频。
- 它能够保持面部、手部和身体运动的一流时间连贯性,即使在长视频中也能维持这种连贯性。
- 它可以从预先存在的图像生成高质量的视频,而不是依赖于文本到图像的生成,为用户提供了对其想要创建的视频的最大可控性。
这些特性代表了显著的技术进步,将极大地提升 Character.AI 的产品,帮助创作者和用户借助 AI 讲述下一代故事。
Character.AI 正在努力将 AvatarFX 模型集成到其产品中,预计在未来几个月内供所有用户使用。CAI+ 订阅用户将率先体验这些新的视频功能,感兴趣的用户可以加入候补名单。
在技术实现方面,AvatarFX 的多模态团队在 DiT 架构的基础上,设计了一个参数高效的训练流程,允许扩散模型根据音频序列生成逼真的嘴唇、头部和身体运动。为此,团队开发了一种新颖的推理策略,可以在任意长度的视频中保持视觉质量、运动连贯性和富有表现力的多样性。
在安全方面,Character.AI 已经为 AvatarFX 实施了强大的安全措施。这些措施包括对用户编写的对话进行安全过滤,使用行业领先的工具阻止使用未成年人、知名政治家和其他知名人士的照片生成视频,对其他人上传的人类照片进行 AI 处理以使其无法识别具体人物,以及在视频上应用水印以表明它们不是真实镜头。此外,用户必须同意一套严格的条款才能使用测试功能,这些条款明确禁止冒充、欺凌、深度伪造以及未经许可使用受保护的知识产权。
随着产品的不断发展,Character.AI 将持续改进这些控制措施,确保社区的安全始终是产品开发过程中的首要考虑因素。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











