
DeepSeek在昨晚悄悄地发布了一款新的大语言模型——DeepSeek-V3-0324。这款模型不仅因其出色的能力在AI行业掀起波澜,更因其独特的部署方式引发了广泛关注。该模型已经在Hugging Face上低调上线,延续了DeepSeek低调但影响力深远的发布模式。
在消费级硬件上运行的巨大突破
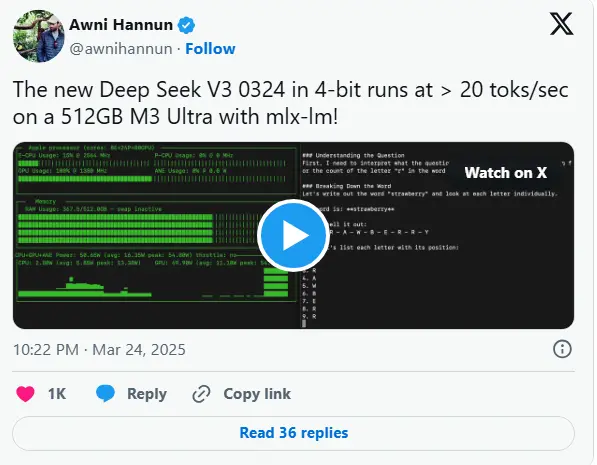
此次发布的一大亮点是DeepSeek-V3-0324采用MIT许可证,这意味着它可以免费用于商业用途。更令人瞩目的是,早期报告显示该模型能够直接运行在消费级硬件上,尤其是苹果的Mac Studio搭配M3 Ultra芯片。AI研究人员Awni Hannun在社交媒体上分享道:“新的DeepSeek-V3-0324在4位量化下,于配备512GB M3 Ultra的Mac Studio上以超过20个令牌/秒的速度运行,使用mlx-lm!”尽管售价9,499美元的Mac Studio可能超出了普通消费者对“消费级硬件”的定义,但能够在本地运行如此庞大的模型,与传统依赖数据中心的尖端AI相比,无疑是一个重大突破。
颠覆传统发布的隐秘策略
这款拥有6850亿参数的模型发布时并未附带技术说明、博客文章或营销推广,只有一个空的README文件和模型权重本身。这种发布方式与西方AI公司精心策划、提前数月炒作的产品发布形成鲜明对比。早期测试者报告称,新版本相比之前有了显著改进。
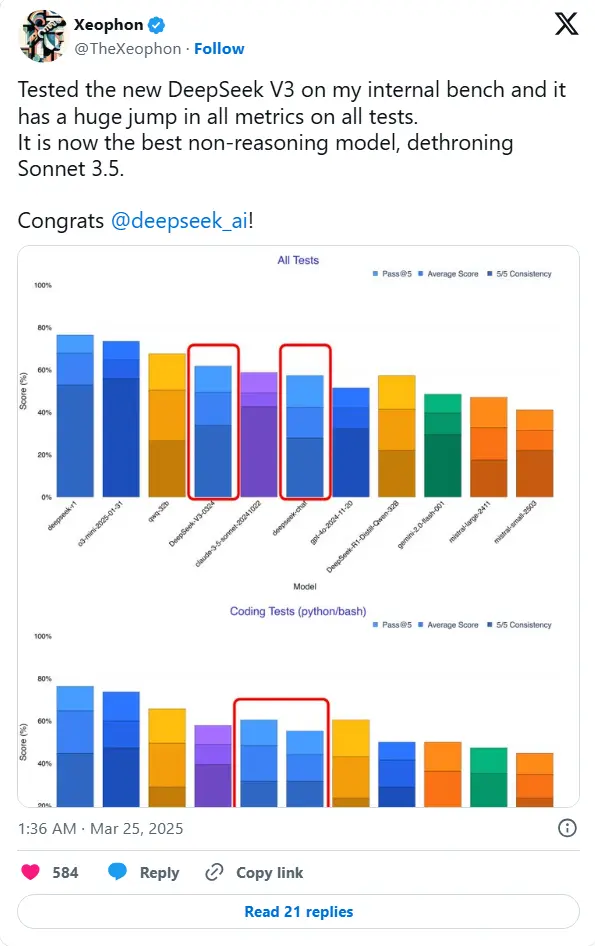
AI研究人员Xeophon在X.com上发帖宣称:“我在内部测试平台上测试了新的DeepSeek V3,它在所有测试的所有指标上都有巨大提升。现在它是非推理模型中最好的,超越了Sonnet 3.5。”如果这一说法通过更广泛的测试得到验证,DeepSeek的新模型将超越Anthropic的Claude Sonnet 3.5——这是最受尊敬的商业AI系统之一。而且与需要订阅的Sonnet不同,DeepSeek-V3-0324的权重可供任何人免费下载和使用。
突破性架构与技术
DeepSeek-V3-0324采用了专家混合(MoE)架构,从根本上重新构想大型语言模型的运作方式。传统模型在每个任务中激活全部参数,而DeepSeek的方法在特定任务中仅激活其6850亿参数中的约370亿个。这种选择性激活代表了模型效率的范式转变。通过仅激活每个特定任务最相关的“专家”参数,DeepSeek实现了与更大全激活模型相当的性能,同时大幅降低了计算需求。
该模型还融入了两项突破性技术:多头潜在注意力(MLA)和多令牌预测(MTP)。MLA增强了模型在长文本中保持上下文的能力,而MTP每步生成多个令牌,而不是通常的一次一个方式。这些创新共同将输出速度提升了近80%。开发者工具创造者Simon Willison在一篇博客文章中指出,4位量化版本将存储占用减少到352GB,使其能够在高端消费硬件(如配备M3 Ultra芯片的Mac Studio)上运行成为可能。
对AI部署的重大转变
这代表了AI部署的潜在重大转变。传统AI基础设施通常依赖多个英伟达GPU,消耗数千瓦的电力,而Mac Studio在推理过程中的功耗不到200瓦。这种效率差距表明,AI行业可能需要重新思考顶级模型性能的基础设施假设。
中国开源AI革命的崛起
DeepSeek的发布策略体现了中国与西方公司在AI商业哲学上的根本分歧。美国领导者如OpenAI和Anthropic将模型置于付费墙后,而中国AI公司日益接受宽松的开源许可。这种方式正迅速改变中国的AI生态系统。尖端模型的公开可用性创造了乘数效应,使初创公司、研究人员和开发者能够在无需巨额资本支出的情况下,基于复杂的AI技术进行构建。这以令西方观察家震惊的速度加速了中国AI能力的发展。
这一策略背后的商业逻辑反映了中国市场的现实。面对多个资金雄厚的竞争对手,当竞争者免费提供类似能力时,维持专有方式变得越来越困难。开源通过生态系统领导力、API服务和基于免费基础模型的企业解决方案创造了替代价值路径。甚至中国老牌科技巨头也认识到这一转变。百度宣布计划在6月前将其文心 4.5模型系列开源,而阿里巴巴和腾讯已发布了具有专门能力的开源AI模型。这一趋势与西方领导者采用的以API为中心的策略形成鲜明对比。
开源方式还应对了中国AI公司面临的独特挑战。由于获取尖端英伟达芯片受限,中国企业强调效率和优化,以更有限的计算资源实现竞争力性能。这种因需求驱动的创新现已成为潜在的竞争优势。
DeepSeek-V3-0324:AI推理革命的基础
DeepSeek-V3-0324的发布时间和特性强烈暗示,它将成为预计在未来两个月内推出的改进型推理模型DeepSeek-R2的基础。Reddit用户mxforest指出:“这与他们在圣诞节前后发布V3,随后几周后发布R1的模式一致。传言R2将在4月推出,所以这可能是它。”一个先进的开源推理模型的影响不容小觑。当前的推理模型,如OpenAI的o1和DeepSeek的R1,代表了AI能力的尖端,展示了从数学到编码等领域的空前问题解决能力。将这项技术免费开放将使目前仅限于预算充足者的AI系统民主化。
潜在的R2模型正值关于推理模型计算需求的重大揭露之际。英伟达首席执行官黄仁勋最近指出,DeepSeek的R1模型“比非推理AI消耗100倍的计算能力”,这与早先行业对效率的假设相矛盾。这揭示了DeepSeek模型的卓越成就,其在比西方同行更大资源限制下仍能提供竞争性能。如果DeepSeek-R2遵循R1的轨迹,它可能对OpenAI的下一代旗舰模型GPT-5构成直接挑战,后者传言将在未来几个月发布。OpenAI的封闭、高资金投入方式与DeepSeek的开放、资源高效策略之间的对比,代表了AI未来的两种竞争愿景。
如何体验DeepSeek-V3-0324:开发者与用户指南
对于渴望体验DeepSeek-V3-0324的用户,根据技术需求和资源有多种途径可选择。完整模型权重可从Hugging Face获取,尽管641GB的大小仅对拥有充足存储和计算资源的人实用。对大多数用户来说,基于云的选项提供了最便捷的入口。OpenRouter提供免费API访问该模型,附带用户友好的聊天界面。只需选择DeepSeek V3 0324作为模型即可开始试验。DeepSeek自有的聊天界面chat.deepseek.com也已更新到新版本。早期用户报告,通过该平台可访问该模型,且性能比之前版本有所提升。
希望将模型集成到应用程序的开发者可通过多个推理提供商访问它。Hyperbolic Labs宣布立即可用,作为“在Hugging Face上提供此模型的首个推理提供商”,而OpenRouter提供与OpenAI SDK兼容的API访问。
模型风格的转变
早期用户报告称,该模型的交流风格发生了显著变化。虽然之前的DeepSeek模型因其对话式、类人语气而受到赞誉,但“V3-0324”呈现出更正式、技术导向的形象。Reddit用户nother_level问道:“只有我一个人觉得这个版本不那么像人吗?对我来说,DeepSeek V3与其他模型区别开来的地方在于它感觉更像人类。语气、措辞等都不像其他LLM那样机器人化,但现在这个版本就像其他LLM一样,声音超级机器人化。”另一位用户AppearanceHeavy6724补充说:“是的,它肯定失去了那种轻松的魅力,感觉过于理性了。”
这种个性转变可能反映了DeepSeek工程师的刻意设计选择。转向更精确、分析性的交流风格表明,该模型正被战略性地重新定位为专业和技术应用,而非休闲对话。这与更广泛的行业趋势一致,AI开发者越来越认识到不同用例受益于不同的交互风格。对于构建专用应用的开发者,这种更精确的交流风格实际上可能是一个优势,为专业工作流程的整合提供更清晰、更一致的输出。然而,对于需要温暖和亲和力的面向客户的应用,其吸引力可能受限。
深远影响:重塑全球AI格局
DeepSeek在AI开发和分发上的方式不仅仅是一项技术成就——它体现了一种关于先进技术如何在社会中传播的根本不同愿景。通过在宽松许可下免费提供尖端AI,DeepSeek促成了封闭模型固有约束下的指数级创新。
这种理念正迅速缩小中国与美国之间感知到的AI差距。就在几个月前,大多数分析师估计中国在AI能力上落后美国1-2年。如今,这一差距已显著缩小至3-6个月,某些领域甚至接近平等或中国领先。
这与Android对移动生态系统的影响有惊人相似之处。谷歌决定免费提供Android打造了一个最终占据全球主导市场份额的平台。同样,开源AI模型可能通过广泛存在和成千上万贡献者的集体创新,超越封闭系统。
其影响超越市场竞争,延伸至技术获取的基本问题。西方AI领导者日益因将先进能力集中在资源充足的公司和个人手中而受到批评。DeepSeek的方式更广泛地分配这些能力,可能加速全球AI的采用。
随着DeepSeek-V3-0324进入全球研究实验室和开发者工作站,竞争不再仅仅是构建最强大的AI,而是让最多的人能够使用AI进行构建。在这场竞赛中,DeepSeek的悄然发布对人工智能的未来发出了响亮的声音。最自由分享技术的公司可能最终对AI如何重塑我们的世界拥有最大影响力。(来源)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











