DeepSeek 的 R1 模型以其强大的性能和灵活性在 AI 领域引起了广泛关注。为了帮助用户更好地部署和使用该模型,DeepSeek 提供了一系列优化建议。这些设置不仅适用于云服务厂家,也对普通用户在使用基于 R1 模型的应用时有所帮助。
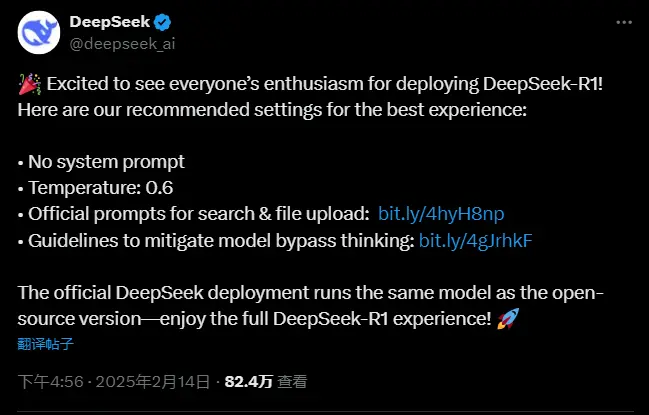
推荐设置
1. 不使用系统提示语
DeepSeek 建议在部署 R1 模型时避免使用系统提示语。这样可以让模型更灵活地适应不同的输入,从而生成更自然和多样化的回答。
2. 温度值设为 0.6
将温度值设置为 0.6 可以在模型响应的创造性和连贯性之间取得良好的平衡。温度值决定了模型输出的随机性,0.6 是一个经过验证的平衡点,既能保证输出的多样性,又不会使回答过于离谱。
3. 使用官方提示词
DeepSeek 提供了针对搜索和文件上传的官方提示词,用户可以通过以下链接访问这些提示:
这些提示词经过优化,能够帮助模型更好地理解和处理用户输入,从而提供更准确和有用的回答。
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''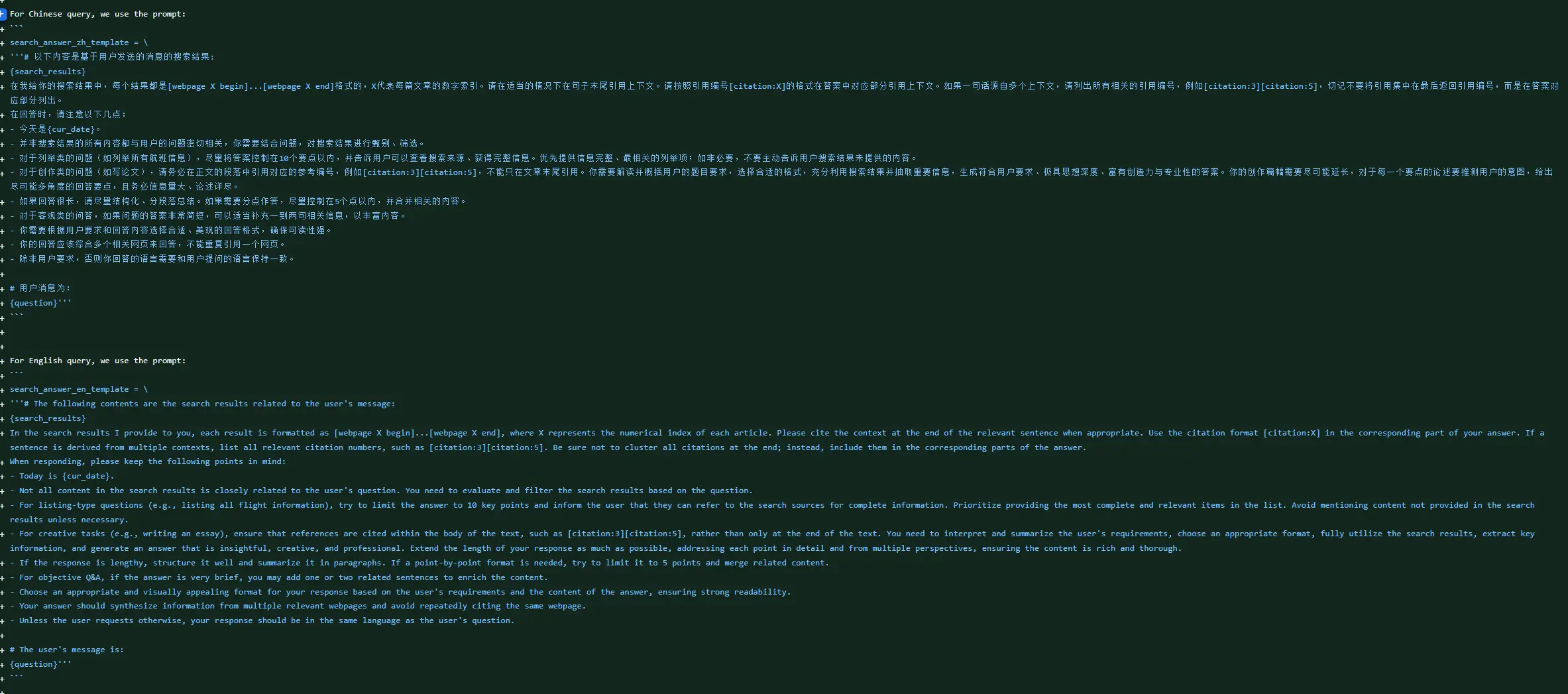
4. 避免模型绕过思考模式
为了确保模型在回答问题时进行充分的推理,DeepSeek 建议在输出的开头加入 <think> 标签。这可以避免模型跳过推理过程,直接输出答案,从而提高回答的质量和深度。更多细节可以参考以下链接:

官方部署与开源版本
DeepSeek 强调,官方部署的 R1 模型与开源版本完全一致。这意味着用户在使用开源版本时也能体验到模型的全部功能,无需担心功能上的差异。
对普通用户的意义
虽然这些部署建议主要针对云服务提供商和技术专家,但普通用户也可以从中受益。例如,如果你使用的是基于 DeepSeek R1 模型的应用程序,了解这些设置可以帮助你更好地理解应用的性能和行为。此外,如果你对技术感兴趣,这些信息也可以作为你探索 AI 的起点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











