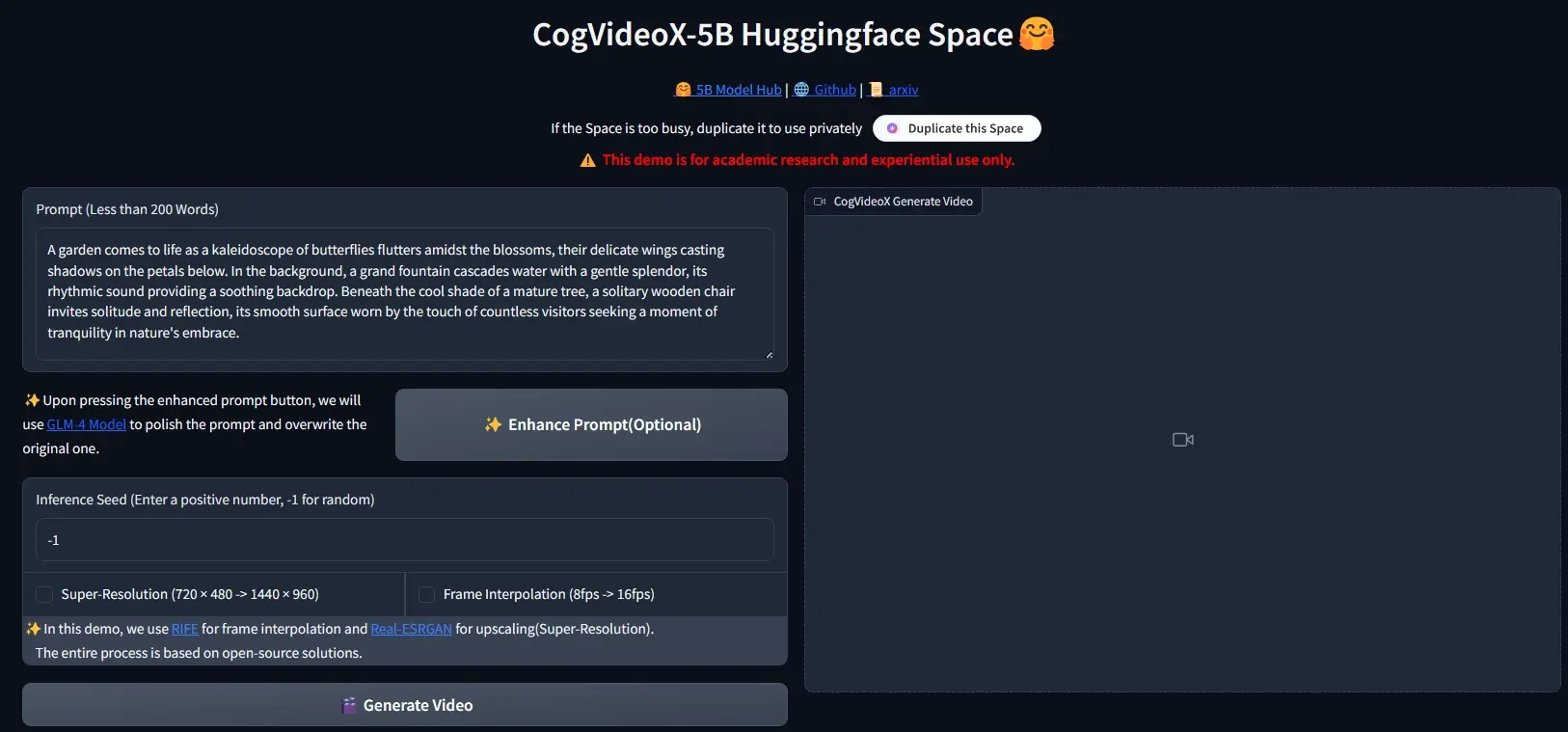
OmniJigsaw 是由 浙江大学 和 小米 联合提出的一种创新的全模态(Audio-Video)自监督学习框架。它旨在解决当前多模态大模型在视频和音频协同理解上的不足,通过一种名为“时间重排序”的代理任务,强制模型进行深度的跨模态推理,而非依赖单一模态的捷径。
- 项目主页:https://aim-uofa.github.io/OmniJigsaw
- GitHub:https://github.com/aim-uofa/OmniJigsaw
该框架在无需人工标注的情况下,显著提升了模型在视频理解、音频分析及多模态协同推理方面的性能,并在 Qwen3-Omni 基线上取得了 SOTA 级别的提升。
核心理念:像拼拼图一样学习
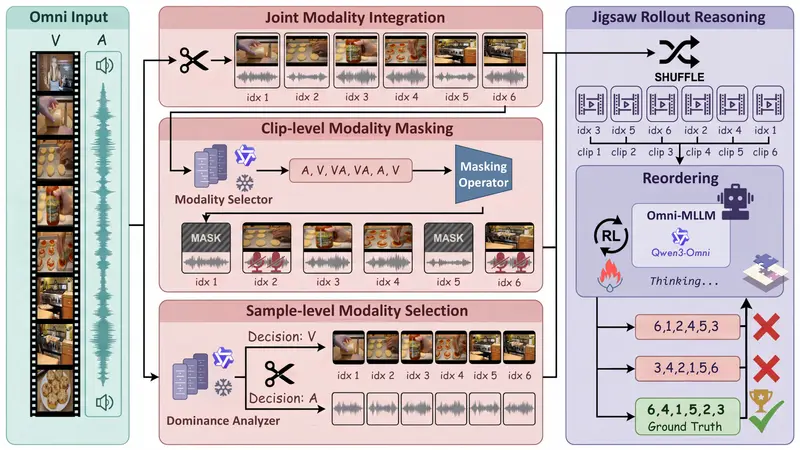
OmniJigsaw 的核心思想非常直观:如果模型能正确地将打乱顺序的视频片段和音频片段重新排列成原始的时间序列,那么它一定真正理解了音视频之间的语义关联和时间逻辑。
1. 自监督代理任务:时间重排序
- 输入:一段被随机打乱顺序的视频片段和对应的音频片段。
- 任务:模型需要预测这些片段的正确时间顺序。
- 优势:完全自监督,无需任何人工标注数据,可利用海量未标注的音视频资源。
2. 模态编排策略:防止“偷懒”
研究发现,如果同时提供完整的视频和音频,模型往往会“偷懒”,只依赖其中一种更容易理解的模态(通常是语言或视觉主导),而忽略另一种,这被称为**“双模态捷径现象”**。为了解决这个问题,OmniJigsaw 提出了三种策略来调控信息流:
| 策略 | 全称 | 机制 | 效果 |
|---|---|---|---|
| JMI | Joint Modal Integration | 基线:保留所有片段的完整同步视听信息。 | 模型易产生依赖,跨模态推理较弱。 |
| SMS | Sample-level Modal Selection | 中级:识别整个样本的主导模态,抑制非主导模态。 | 优于 JMI,但粒度较粗。 |
| CMM | Clip-level Modal Masking | 高级(最佳):评估每个片段的语义密度,动态掩码掉不显著的模态。 | 强制模型联合分析剩余线索,最大化局部信息熵,效果最佳。 |
💡 关键洞察:CMM 策略通过制造“信息瓶颈”,迫使模型在视觉缺失时听声音,在音频模糊时看画面,从而真正实现深度跨模态融合。
高质量数据管道:从粗到细的过滤
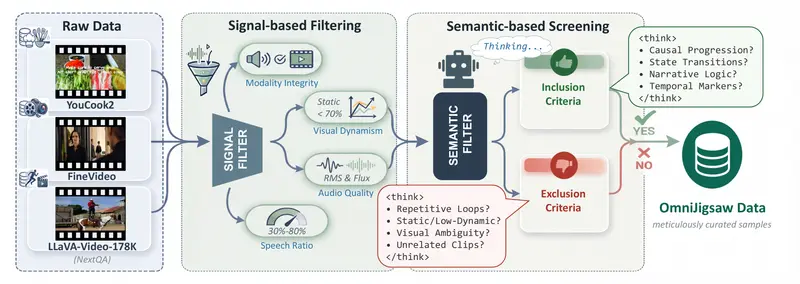
并非所有打乱的音视频都适合做“拼图”。低质量的数据会导致模型学习到错误的关联。OmniJigsaw 设计了一个两阶段过滤管道:
- 第一阶段:基于信号的启发式过滤
- 确保音视频数据的完整性、同步性和基本质量。
- 第二阶段:基于语义的思维链(CoT)筛选
- 利用大模型分析片段的叙事逻辑和状态转换,剔除那些缺乏明确时间逻辑或语义混乱的片段。
- 确保留下的“拼图块”具有清晰的因果或时间线索。
卓越的性能表现
在 15 个主流基准测试中,OmniJigsaw 均展现出显著提升,特别是在需要复杂推理的视频问答和音频理解任务上。
基于 Qwen3-Omni 基线的提升示例:
- MLVU-Test (长视频理解): +4.38
- MMAR (多模态音频推理): +2.50
- OmniVideoBench (综合视频基准): +1.70
此外,消融实验证实:
- 片段级控制 (CMM) > 样本级控制 (SMS):更细粒度的模态掩码更能适应音视频信息的动态变化。
- 数据质量至关重要:未经过滤的数据训练会导致性能大幅下降。
- 折扣因子的作用:在强化学习中引入准确率折扣因子,能有效抑制次优解,防止模型过早收敛到简单策略。
定性分析:CMM 如何改变推理?
- JMI (基线):模型倾向于说“根据画面中的文字...”或“根据听到的对话...”,表现出明显的单模态依赖。
- CMM (OmniJigsaw):当视觉被掩码时,模型会主动分析背景音、语气和环境声;当音频被掩码时,模型会更细致地观察肢体语言和场景变化。最终输出的推理过程更加全面和稳健。
意义
OmniJigsaw 为全模态大模型的后训练(Post-training)提供了一条高效、可扩展的新路径。它证明了:
- 自监督学习依然强大:通过精心设计的代理任务,无需标注也能挖掘海量数据的价值。
- “困难”是学习的催化剂:通过模态掩码制造适度的困难,能迫使模型走出舒适区,建立更 robust 的跨模态表征。
- 通用性:该框架可广泛应用于各种音视频基础模型的增强,为未来的多模态 AI 助手、视频内容理解、智能监控等领域提供更强大的底层支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...