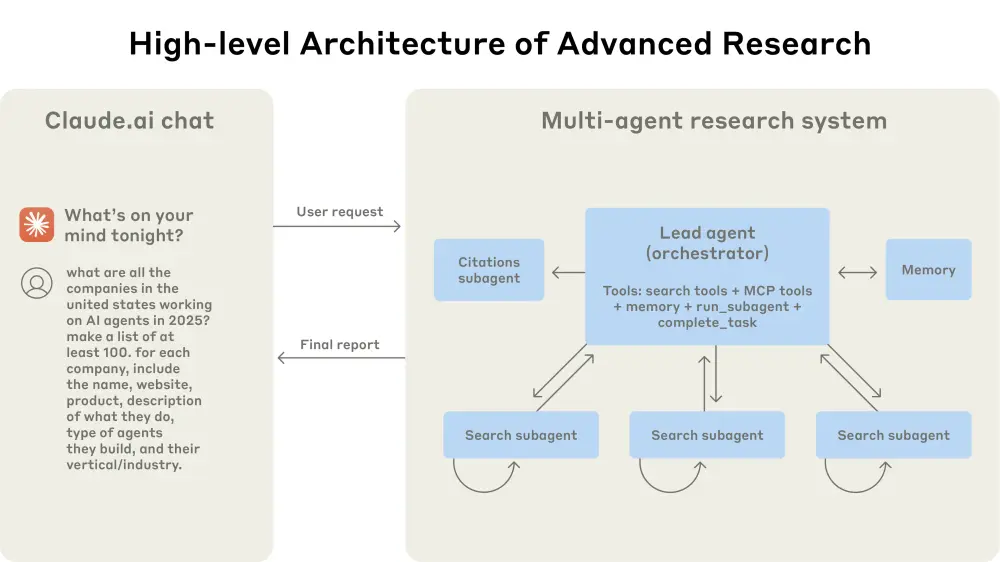
在本地运行大语言模型(LLM)进行代码生成的热潮中,许多开发者发现:尽管模型参数越来越大,但在实际构建“编程代理”(Coding Agent)时,体验往往不如预期——工具调用失败、上下文丢失、逻辑中断频发。
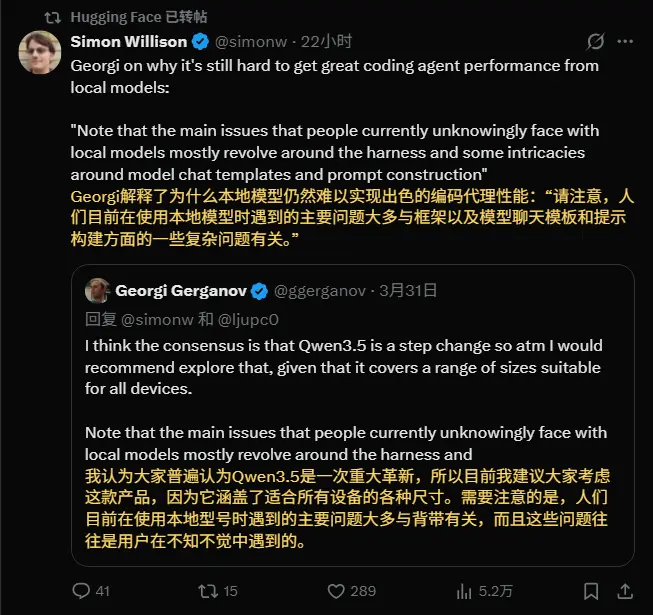
llama.cpp 核心开发者 Georgi Gerganov 近日对此现象进行了深度剖析。他指出,当前的瓶颈不再仅仅是模型本身的智能程度,而更多在于工具链的脆弱性、对话模板的复杂性以及生态整合的缺失。
- 地址:https://x.com/ggerganov/status/2038674698809102599
本文将梳理 Georgi 的核心观点,为希望在本地部署高效 AI 编程助手的开发者提供一份务实的行动指南。
核心洞察:瓶颈不在模型,而在“胶水层”
社区普遍共识认为,Qwen3.5 系列模型代表了本地模型能力的阶梯式进步,覆盖了从消费级显卡到高端工作站的多种硬件需求。然而,Georgi 强调,即便拥有了强大的模型,用户仍会遭遇诸多“莫名其妙”的失败。
1. 脆弱的技术长链
从用户在客户端输入任务,到最终获得可执行的代码结果,中间涉及一长串组件:
用户输入 → 客户端解析 → 提示词构建 → 对话模板应用 → 模型推理 → 工具调用解析 → 代码执行 → 结果反馈
Georgi 指出,这一链条中的每个环节往往由不同的第三方开发,彼此之间缺乏统一标准。
- 现状:整个技术栈极其脆弱。任何一个微小环节(如特殊字符转义、换行符处理、JSON 格式偏差)出错,都会导致整个流程崩溃。
- 后果:用户看到的往往是“模型胡言乱语”或“无响应”,但根本原因可能是提示词构建错误或工具响应解析失败,而非模型本身不够聪明。
2. “黑盒”集成的陷阱
许多用户试图直接将 Claude Code (CC) 或 Codex CLI 等官方工具挂接到本地模型(如 Qwen3.5)上,期望实现“即插即用”。
- 现实:这些官方 CLI 工具是为其自家模型量身定制的,开发人员目前并不关心它们是否兼容本地非官方模型。
- 风险:强行对接往往导致对话模板不匹配、工具定义解析错误,最终使得代理无法正常工作。
3. 推理错误的伪装
很多时候,所谓的“模型推理能力不足”,实际上是工程实现缺陷的伪装。如果模型接收到的指令因模板错误而被扭曲,或者它的输出因解析逻辑bug而被误读,那么再强大的模型也无法表现出应有的智能。
实战指南:如何构建可靠的本地代理?
针对上述痛点,Georgi 提出了一套循序渐进的实操建议,帮助开发者避开陷阱,建立稳定的本地工作流。
第一步:起点——全质量优先 (Start with Full Quality)
不要一开始就为了追求速度而使用低比特量化模型。
- 策略:从适合你硬件的最高质量版本开始(如 FP16, BF16, 或 Q8_0)。
- 目的:首先排除模型能力本身的问题。如果全精度模型都无法稳定运行,量化版本更不可能成功。
- 推荐模型(Georgi 亲测有效,主要使用 Q8_0 以保留质量):
- Qwen3.5-35B-A3B(强烈推荐,综合能力最强)
- Qwen3-Coder-30B
- gpt-oss-120b
- MiniMax-M2.5
- GLM-4.7-Flash
第二步:核心——掌控你的工具链 (Own Your Toolchain)
这是最关键的一步。放弃“一键接入”的幻想。
- 避坑:不要指望官方 Claude Code 或 Codex 能完美支持本地模型。
- 方案 A(硬核推荐):编写你自己的工具链。只有你自己写的代码,你才能完全掌控每一步的逻辑,清楚哪里出了错,并能迅速修复。这是构建稳定代理的最可靠途径。
- 方案 B(便捷推荐):使用
llama-server的 WebUI。- 作为 llama.cpp 生态的一部分,它对各种模型的**对话模板(Chat Templates)**拥有最好的原生支持。
- 开箱即支持 MCP (Model Context Protocol),能更规范地处理工具调用。
- 相比强行修改官方 CLI,这是更稳妥的本地代理入口。
第三步:优化——先跑通,再加速 (Run First, Optimize Later)
- 顺序:只有当你的工作流在全精度模型上稳定运行、工具调用准确无误后,再考虑性能优化。
- 手段:
- 尝试更低比特位的量化(如 Q4_K_M, Q5_K_M)以提升推理速度。
- 参考社区关于特定模型的最佳推理参数(Context Size, Temperature, Top_P 等)。
未来展望:正在改善的路上
尽管挑战重重,Georgi 也给出了积极的信号:
- 底层推理稳固:llama.cpp 团队将持续提供正确、高效的底层推理解决方案。
- 模板解析改进:
llama.cpp正在积极改进对复杂对话模板的解析能力,这将直接提升工具调用的成功率。 - 生态依赖社区:对于面向用户的技术栈(如各类 Agent 框架),Georgi 坦言自己控制力有限,这需要依赖像 VCC、OpenClaw 等社区项目来填补空白,推动标准化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











